T 3 Cs Cache Miss Rates SPEC 92

 0. 14 1 -way")
 100% 1 -way 2")



















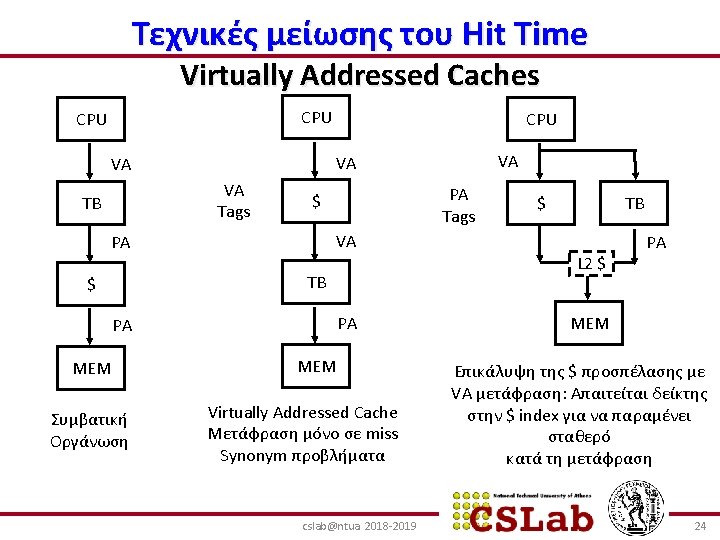





- Slides: 30
Tα 3 Cs των Cache: Απόλυτα Miss Rates (SPEC 92) 0. 14 1 -way 2 -way 0. 1 4 -way 0. 08 8 -way 0. 06 Capacity 0. 04 0. 02 Μέγεθος Cache (KB) cslab@ntua 2018 -2019 128 64 32 16 8 4 2 0 1 Miss Rate / τύπο 0. 12 Compulsory 2
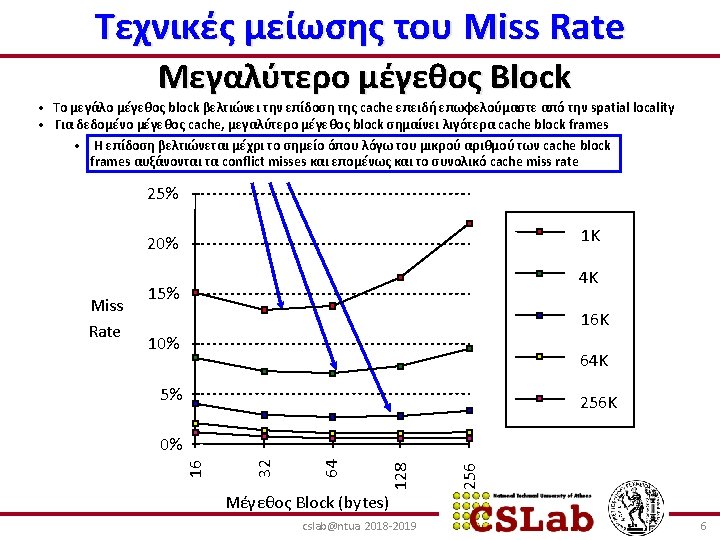
Tα 3 Cs των Cache: Σχετικά Miss Rates (SPEC 92) 100% 1 -way 2 -way 4 -way 60% 8 -way 40% Capacity Cache Size (KB) cslab@ntua 2018 -2019 64 32 16 8 4 2 0% 128 20% 1 Miss Rate / είδος 80% Compulsory 3
Τεχνικές μείωσης του Miss Rate Μεγαλύτερου βαθμού Associativity Παράδειγμα: Μέσος χρόνος πρόσβασης στη μνήμη vs. Miss Rate Cache Size (KB) 1 -way 1 2. 33 2 1. 98 4 1. 72 8 1. 46 16 1. 29 32 1. 20 64 1. 14 128 1. 10 Associativity 2 -way 4 -way 2. 15 2. 07 1. 86 1. 76 1. 67 1. 61 1. 48 1. 47 1. 32 1. 24 1. 25 1. 20 1. 21 1. 17 1. 18 8 -way 2. 01 1. 68 1. 53 1. 43 1. 32 1. 27 1. 23 1. 20 (Μπλε σημαίνει ότι ο μέσος χρόνος δεν βελτιώνεται με την αύξηση του associativity) cslab@ntua 2018 -2019 8
Τεχνικές μείωσης του Miss Rate: Compiler Optimizations Merging Arrays /* Before: 2 sequential arrays */ int val[SIZE]; int key[SIZE]; /* After: 1 array of stuctures */ struct merge { int val; int key; }; struct merged_array[SIZE]; Merging : • Μειώνονται τα conflicts μεταξύ των στοιχείων των val και key • Βελτίωση του spatial locality cslab@ntua 2018 -2019 13
Τεχνικές μείωσης του Miss Rate: Compiler Optimizations Loop Fusion /* Before */ for (i = 0; i < N; i = i+1) for (j = 0; j < N; j = j+1) a[i][j] = 1/b[i][j] * c[i][j]; for (i = 0; i < N; i = i+1) for (j = 0; j < N; j = j+1) d[i][j] = a[i][j] + c[i][j]; /* After */ for (i = 0; i < N; i = i+1) for (j = 0; j < N; j = j+1) { a[i][j] = 1/b[i][j] * c[i][j]; d[i][j] = a[i][j] + c[i][j]; } – Αντί 2 misses/access στα a & c τελικά 1 miss/access – Βελτίωση της spatial locality cslab@ntua 2018 -2019 15
Τεχνικές μείωσης του Miss Rate: Compiler Optimizations Blocking /* After */ for (jj = 0; jj < N; jj = jj+B) for (kk = 0; kk < N; kk = kk+B) for (i = 0; i < N; i = i+1) for (j = jj; j < min(jj+B, N); j = j+1) {r = 0; for (k = kk; k < min(kk+B, N); k = k+1) r = r + y[i][k]*z[k][j]; x[i][j] = x[i][j] + r; }; • B : Blocking Factor • Capacity Misses αντί 2 N 3 + N 2 -> 2 N 3/B +N 2 • Πιθανόν να επηρεάζονται και τα conflict misses cslab@ntua 2018 -2019 17
Σύνοψη Miss rate Προτεραιότητα στα Read Misses Subblock Placement Early Restart & Critical Word 1 st Non-Blocking Caches Second Level Caches Hit time Μεγαλύτερο μέγεθος Block Υψηλότερη Associativity Victim Caches Pseudo-Associative Caches HW Prefetching of Instr/Data Compiler Controlled Prefetching Compiler Reduce Misses Miss Penalty Τεχνική Small & Simple Caches Avoiding Address Translation Pipelining Writes MR MP + + + + – cslab@ntua 2018 -2019 HT – + + Complexity 0 1 2 2 2 3 0 1 1 2 3 2 0 2 1 25
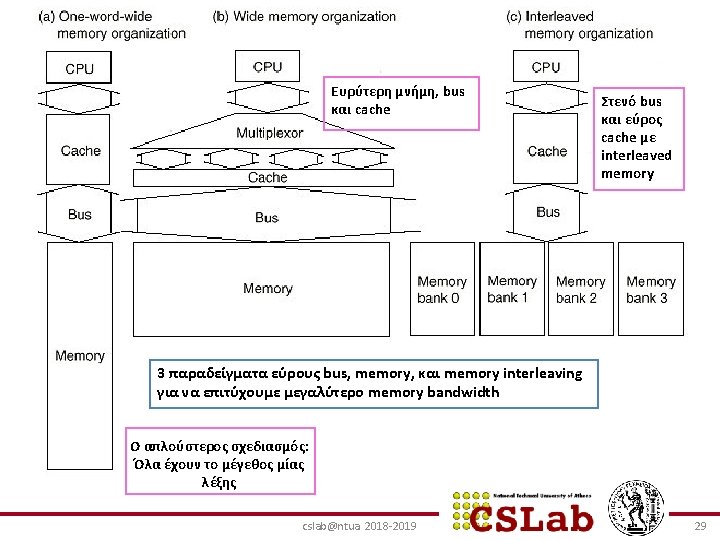
Οργάνωση της DRAM cslab@ntua 2018 -2019 27