REVISION OF TOPICS FOR CMED 305 FINAL EXAM


 Study Designs (Casecontrol, Cohort, Experimental, Cross sectional) (3)")

 Formulae (manual calculations) (2)")

 DISCRETE QUANTITATIVE CONTINOUS QUANTITATIVE")
 --- Pie diagram Continuous data")


 Skewed: positively (skewed to the right)")

: Comments: n =")







 Absent Present Positive Correct Test Result False Positive")








 precision of the estimate is indicated by the width")
 gives you")

 Chi-square test: Study variable: Qualitative Outcome variable: Qualitative Comparison: two")


 data")
: Apply (i) Chi")
")

- Slides: 40
REVISION OF TOPICS FOR CMED 305 FINAL EXAM
The exam duration: 1 hour 30 min. Marks : 25 All MCQ’s. You should choose the correct answer. No major calculations, but simple maths IQ is required. No need to memorize the formulas. Bring your own calculator. Cell phones are not allowed to use as a calculator.
Research Methodology: Incidence and Prevalence (2) Study Designs (Casecontrol, Cohort, Experimental, Cross sectional) (3) Odds Ratio and Relative Risk (2) Designing questionnaire and Study Tools for data collection (1) Data Interpretation (2) Biostatistics Topics: ( 40 questions) Sampling Techniques (4) Sample size (2) Type of data & graphical presentation(4) Summary and Variability measures (7) Normal distribution (2) Statistical significance using p-values (6) Statistical significance using confidence intervals (5) Statistical tests for quantitative variables (5) Statistical tests for qualitative variables (4) Spss software (1)
SAMPLING METHODS Probability Sampling Simple random sampling Stratified random sampling Systematic random sampling Cluster (area) random sampling Multistage random sampling Non-Probability Sampling Deliberate (quota) sampling Convenience sampling Purposive sampling Snowball sampling Consecutive sampling
Estimation of Sample Size by Three ways: By using (1) Formulae (manual calculations) (2) Sample size tables or Nomogram (3) Softwares
SCALES OF MEASURE Nominal – qualitative classification of equal value: gender, race, color, city Ordinal - qualitative classification which can be rank ordered: socioeconomic status of families Interval - Numerical or quantitative data: can be rank ordered and sizes compared : temperature Ratio - Quantitative interval data along with ratio: time, age.
TYPES OF DATA QUALITATIVE DATA (Categorical data) DISCRETE QUANTITATIVE CONTINOUS QUANTITATIVE
Categorical data --- Bar diagram (one or two groups) --- Pie diagram Continuous data --- Histogram --- Frequency polygon (curve) --- Stem-and –leaf plot --- Box-and-whisker plot --- Scatter diagram
Describing Data Numerically Central Tendency Quartiles Variation Shape Arithmetic Mean Range Median Interquartile Range Mode Variance Geometric Mean Standard Deviation Skewness Harmonic Mean 9
DISTRIBUTION OF DATA IS SYMMETRIC ---- USE MEAN & S. D. , DISTRIBUTION OF DATA IS SKEWED ---- USE MEDIAN & QUARTILES(IQR)
Bell-Shaped (also known as symmetric” or “normal”) Skewed: positively (skewed to the right) – it tails off toward larger values negatively (skewed to the left) – it tails off toward smaller values 11
VARIANCE: Deviations of each observation from the mean, then averaging the sum of squares of these deviations. STANDARD DEVIATION: “ ROOT- MEANS-SQUARE-DEVIATIONS”
STANDARD ERROR OF THE MEAN Standard error of the mean (sem): Comments: n = sample size even for large s, if n is large, we can get good precision for sem always smaller than standard deviation (s)
Standard error of mean is calculated by:
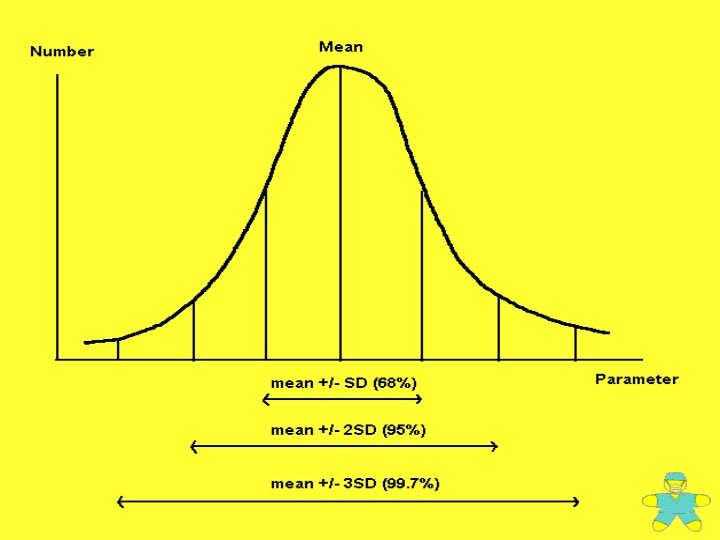
NORMAL DISTRIBUTION Many biologic variables follow this pattern Hemoglobin, Cholesterol, Serum Electrolytes, Blood pressures, age, weight, height One can use this information to define what is normal and what is extreme In clinical medicine 95% or 2 Standard deviations around the mean is normal Clinically, 5% of “normal” individuals are labeled as extreme/abnormal We just accept this and move on.
CHARACTERISTICS OF NORMAL DISTRIBUTION Symmetrical about mean, Mean, median, and mode are equal Total area under the curve above the x-axis is one square unit 1 standard deviation on both sides of the mean includes approximately 68% of the total area 2 standard deviations includes approximately 95% 3 standard deviations includes approximately 99%
Measures of Position z score Sample x x z= s Population x µ z=
Interpreting Z Scores Unusual Values -3 Ordinary Values -2 -1 0 Z Unusual Values 1 2 3
Hypothesis NULL HYPOTHESIS ‘No difference ‘ or ‘No association’ Alternative hypothesis Logical alternative to the null hypothesis ‘There is a difference’ or ‘Association’ simple, specific, in advance
TYPE I & TYPE II ERRORS Every decisions making process will commit two types of errors. “We may conclude that the difference is significant when in fact there is not real difference in the population, and so reject the null hypothesis when it is true. This is error is known as type-I error, whose magnitude is denoted by the Greek letter ‘α’. On the other hand, we may conclude that the difference is not significant, when in fact there is real difference between the populations, that is the null hypothesis is not rejected when actually it is false. This error is called type-II error, whose magnitude is denoted by ‘β’.
DIAGNOSTIC TEST SITUATION Disease (Gold Standard) Absent Present Positive Correct Test Result False Positive a c Negative Total False Negative a+c Total a+b b d Correct b+d c+d a+b+c+d
Sampling Investigation P S S Results Inference P value Confidence intervals!!!
DEFINITION OF P-VALUE This level of uncertainty is called type 1 error or a false-positive rate ( ) More commonly called a p-value In general, p ≤ 0. 05 is the agreed upon level In other words, the probability that the difference that we observed in our sample occurred by chance is less than 5% Therefore we can reject the Ho
Testing significance at 0. 05 level 1. 96 Rejection region +1. 9 6 Nonrejection region Rejection region Z /2 = 1. 96 Reject H 0 if Z < -Z /2 or Z > Z /2 25
DEFINITION OF P-VALUE Stating the Conclusions of our Results When the p-value is small, we reject the null hypothesis or, equivalently, we accept the alternative hypothesis. is defined as a p-value , where = acceptable false (+) rate (usually 0. 05). “Small” When the p-value is not small, we conclude that we cannot reject the null hypothesis or, equivalently, there is not enough evidence to reject the null hypothesis. small” is defined as a p-value > , where = acceptable false (+) rate (usually 0. 05). “Not
Estimation Two forms of estimation • Point estimation = single value, e. g. , x-bar is unbiased estimator of μ • Interval estimation = range of values confidence interval (CI). A confidence interval consists of:
Estimation Process Population Mean, , is unknown Sample Random Sample Mean X = 50 I am 95% confident that is between 40 & 60.
Different Interpretations of the 95% confidence interval • “We are 95% sure that the TRUE parameter value is in the 95% confidence interval” • “If we repeated the experiment many times, 95% of the time the TRUE parameter value would be in the interval” • “the probability that the interval would contain the true parameter value was 0. 95. ”
Most commonly used CI: CI 90% corresponds to p 0. 10 CI 95% corresponds to p 0. 05 CI 99% corresponds to p 0. 01 Note: p value only for analytical studies CI for descriptive and analytical studies
CHARACTERISTICS OF CI’S --The (im) precision of the estimate is indicated by the width of the confidence interval. --The wider the interval the less precision THE WIDTH OF C. I. DEPENDS ON: ---- SAMPLE SIZE ---- VAIRABILITY ---- DEGREE OF CONFIDENCE
Comparison of p values and confidence interval • p values (hypothesis testing) gives you the probability that the result is merely caused by chance or not by chance, it does not give the magnitude and direction of the difference • Confidence interval (estimation) indicates estimate of value in the population given one result in the sample, it gives the magnitude and direction of the difference
STATISTICAL TESTS Z-test: Study variable: Qualitative Outcome variable: Quantitative or Qualitative Comparison: two means or two proportions Sample size: each group is > 50 Student’s t-test: Study variable: Qualitative Outcome variable: Quantitative Comparison: sample mean with population mean; two means (independent samples); paired samples. Sample size: each group <50 ( can be used even for large sample size)
STATISTICAL TEST (CONT. ) Chi-square test: Study variable: Qualitative Outcome variable: Qualitative Comparison: two or more proportions Sample size: > 20 Expected frequency: > 5 Fisher’s exact test: Study variable: Qualitative Outcome variable: Qualitative Comparison: two proportions Sample size: < 20 Macnemar’s test: (for paired samples) Study variable: Qualitative Outcome variable: Qualitative Comparison: two proportions Sample size: Any
STUDENT’S T-TEST 1. Test for single mean 2. Test for difference in means 3. Test for paired observation
Student ‘s t-test will be used: --- When Sample size is small , for mean values and for the following situations: (1) to compare the single sample mean with the population mean (2) to compare the sample means of two independent samples (3) to compare the sample means of paired samples
Statistical tests for qualitative (categorical) data
When both the study variables and outcome variables are categorical (Qualitative): Apply (i) Chi square test (ii) Fisher’s exact test (Small samples) (iii) Mac nemar’s test ( for paired samples)
DEGREES OF FREEDOM (DF )
Wishing all of you Best of Luck !