RECURRENT NEURAL NETWORKS FEATURING LSTM W KERAS AND



 past “cell” future input (current) In 1")


 OF PROBLEMS CAN YOU SOLVE WITH TIME SERIES DATA (AND RNNS)")
 • INPUT = MANY IMAGES -")
 • INPUT = ONE IMAGE • OUTPUT")
 • INPUT = MANY IMAGES –VIDEO(MULTIPLE")
 • INPUT = MANY WORDS (IN ONE")












 FOLLOW THE MATH TO UNDERSTAND")


 THE PAST What part")
 What")

![CURRENT STATE What part of cell to output tanh maps bits to [1, +1]](https://slidetodoc.com/presentation_image_h2/732dd668f48f811effc6960ccb069926/image-30.jpg "CURRENT STATE What part of cell to output tanh maps bits to [1, +1]")
 (2) CT-1 (3) FT IT ot")
 (2) (3)")








")





![IMAGE SENTENCE DATASETS MICROSOFT COCO [TSUNG-YI LIN ET AL. 2014] MSCOCO. ORG CURRENTLY: ~120](https://slidetodoc.com/presentation_image_h2/732dd668f48f811effc6960ccb069926/image-47.jpg "IMAGE SENTENCE DATASETS MICROSOFT COCO [TSUNG-YI LIN ET AL. 2014] MSCOCO. ORG CURRENTLY: ~120")
- Slides: 48
RECURRENT NEURAL NETWORKS FEATURING LSTM W/ KERAS AND TENSORFLOW
RNN – USED TO PROCESS TIME SEQUENCE DATA LIKE VIDEO THIS FIGURE SHOWS WORK RELATED TO NETWORK BASED LEARNING SCHEMES –THERE ARE OTHER TECHNIQUES LIKE SVM AND KNN THAT ARE NOT • THE BIGGER PICTURE –WE HAVE SEEN NETWORK BASED • ARTIFICIAL NEURAL NETWORKS • CONVOLUTIONAL NEURAL NETWORKS. SUPERVISED LEARNING – WE HAVE LABELED DATA SETS TRAIN WITH UNSUPERVISED LEARNING - UNLABELED DATA THAT THE ALGORITHM TRIES TO MAKE SENSE OF BY EXTRACTING FEATURES AND PATTERNS ON ITS OWN.
FIRST LETS PLAY A VIDEO IN YOUR GROUPS
GENERAL CONCEPT Prediction(at this point in “time”) past “cell” future input (current) In 1 In 2 In 3 In. N
RECURRENT NEURAL NETWORKS • PROCESS TIME –SERIES DATA LIKE • • VIDEO SPEECH NATURAL LANGUAGE PROCESSING ANY DATA WITH A TIME COMPONENT WAS DEVELOPED FOR SPEECH PROCESSING BUT – BOTH THE INPUT AND THE OUTPUT CAN HAVE THIS NOTION OF TIME. HUH? LETS LOOK
ARCHITECTURE FOR AN RNN Some information is passed from one subunit to the next Start of sequence marker SEQUENCE OF OUTPUTS SEQUENCE OF INPUTS End of sequence marker
WHAT KINDS (CASES) OF PROBLEMS CAN YOU SOLVE WITH TIME SERIES DATA (AND RNNS) ---FOCUSING ON VISION
CASE : VIDEO ACTIVITY RECOGNITION (MANY TO ONE) • INPUT = MANY IMAGES - VIDEO (MULTIPLE IMAGES) • OUTPUT = ACTIVITY LABEL WITH ONLY A “OBJECT RECOGNIZER” CNN YOU WOULD TYPICALLY ONLY KNOW THERE IS A POLL AND SOMEONE’S HAND CNN(FOR FEATURES) + RNN = THE RNN ALLOWS THE COMPUTER TO RECOGNI “DOG JUMPING”
CASE 4: IMAGE CAPTIONING (1 TO MANY) • INPUT = ONE IMAGE • OUTPUT = MANY WORDS (THIS HAS A SEQUENCE OF WORDS) With only a “object recognizer” CNN you would typically only know there is a Dog, you m know there is a poll and someone’s hand CNN(for features) + RNN = the RNN allows the computer to make out of the sentence “b and white dog jumps over bar”
CASE : VIDEO “ACTIVITY” RECOGNITION (MANY TO MANY) • INPUT = MANY IMAGES –VIDEO(MULTIPLE IMAGES) • OUTPUT = MANY WORDS (THIS HAS A SEQUENCE OF WORDS) BOY HITTING A BASEBALL CNN(FOR FEATURES) + RNN = THE RNN ALLOWS THE COMPUTER TO MAKE THE DIFFERENCE HERE OVER THE MANY TO ONE VIDEO ACTIVITY RECOGNITIO IDENTITY OF THE “ACTIVITY” LIKE A SENTENCE = SEQUENCE OF WORDS RATH ACTIVITY. IN THIS CASE WE COULD HAVE A SENTENCE LIKE “BLACK DOG JUMPING
CASE : SPEECH TRANSLATION (MANY TO MANY) • INPUT = MANY WORDS (IN ONE LANGUAGE) • OUTPUT = MANY WORDS (TRANSLATION) CNN(FOR FEATURES) + RNN = THE RNN ALLOWS THE COMPUTER TO MAKE OUT AND WHITE DOG JUMPS OVER BAR” “PERRO BLANCO Y NEGRO SALTA SOBR THIS IS A NON-VISION APPLICATION (MUCH LIKE THE MANY TO MANY VIDEO “AC
SUMMARY OF DIFFERENT CASES IMAGE CAPTIONING LANGUAGE TRANSLATION VIDEO ACTIVITY –WHERE ACTIVITY IS A SINGLE CONCEPT: JUMPING, RUNNING, ETC. VIDEO ACTIVITY RECOGNITION ON FRAME LEVEL –BUILDING
PREVIOUSLY: SIMPLE FEEDFORWARD NETWORK y 1 h 1 x 1 T=1 13
RECURRENT NEURAL NETWORK • STARTING STATE = H 0 INPUT TIMES 1, 2, 3 • PASS ON STATE H 1 TO NEXT RNN CELL (T=2) AND WITH ITS Y 3 INPUT REASON AND SO ON. Y 2 Y 1 H 0 X 1 T=1 H 2 X 2 T=2 H 3 X 3 T=3
THE VANILLA RNN CELL XT = INPUT TIME T XT W HT HT-1 = PREVIOUS CELL H STATE W = WEIGHT MATRIX HT = CURRENT CELL HID 15
THE VANILLA RNN FORWARD C 1 C 2 C 3 Y 1 Y 2 Y 3 H 1 H 2 H 3 X 1 H 0 X 2 H 1 X 3 H 2 PASS STATE INTO NEXT CELL AND 16 HIDDE ITS INPUT CREATE THE NEW STATE
THE VANILLA RNN FORWARD C 1 C 2 C 3 Y 1 Y 2 Y 3 H 1 H 2 H 3 X 1 H 0 X 2 H 1 X 3 H 2 INDICATES SHARED WEIGHT 17
IMAGE CAPTIONING RNN CNN H 1 THE DOG Linear Classifier H 2 H 3 RNN H 2 H 3
RNN OUTPUTS: IMAGE CAPTIONS SHOW AND TELL: A NEURAL IMAGE CAPTION GENERATOR, CVPR 15
LOOKING CLOSER ---WHAT IS HAPPENING
RNNS – THE INPUT • HAVE A PREVIOUS FEATURE EXTRACTION PHASE • THIS CAN BE DONE WITH ANY KIND OF FEATURE EXTRACTION ALGORITHM INCLUDING A CNN • INPUT TO RNN = FEATURE VOLUME (SET OF FEATURES OVER TIME—IN OUR CASE FEATURES FOR EACH IMAGE IN THE VIDEO SEQUENCE).
PROBLEM WITH VANILLA RNN --
PROBLEM: VANISHING GRADIENTS • HAMPERS LEARNING OF LONG DATA SEQUENCES. • GRADIENT IS USED IN BACK-PROPAGATION TO UPDATE WEIGHTS IN RNN • WHEN THE GRADIENT BECOMES SMALLER AND SMALLER, THE PARAMETER UPDATES BECOME INSIGNIFICANT WHICH MEANS NO REAL LEARNING IS DONE. gradient if gradient small
A SOLUTION LSTM LONG TERM SHORT TERM MEMORY (NETWORK) FOLLOW THE MATH TO UNDERSTAND HOW THE FORGET GATE TRANSLATES TO THE GRADIENTS NOT BECOMING VERY SMALL AND NO VANISHING GRADIENTS --SEE HERE FOR ONE OF MANY RESOURCES THAT SHOWS THE MATH BEHIND THIS HTTPS: //MEDIUM. COM/DATADRIVENINVESTOR/HOW-DOLSTM-NETWORKS-SOLVE-THE-PROBLEM-OF-VANISHING-
ARCHITECTURE FOR AN LSTM “Bits of memory” Decide what to forget insert Longterm-short term model Combine with transformed xt σ: output in [0, 1] tanh: output in [-1, +1]
WHAT DOES DO? “GATING” Passed Throug h Larger # allows signal to go through Vector element-wise multiplication (element by element multiplication) NOT Passed Throug h Vector addition (element by element addition)
SHORT TERM MEMORY – THE PROCESS OF FORGETTING (OR REMEMBERING) THE PAST What part of memory to “forget” – zero means forget this The past The current output is the “masking vector” will multiple by to determine What values of (previous output) to let through or REMEM • Any element of vector that is zero means FORGET
INSERTING NEW DATA COMING IN -- (E. G. NEW IMAGE FRAME IN VIDEO) What content to insert into the next states What content to pass into the next state – these are like “Gating values”
COMBINING OLD DATA REMEMBERED AND INSERTED NEW DATA Next memory cell content – mixture of notforgotten part of previous cell and insertion new data Vector element-wise multiplication (element by element multiplication) Vector addition (element by element addition)
CURRENT STATE What part of cell to output tanh maps bits to [1, +1] range
ALL TOGETHER (1) (2) CT-1 (3) FT IT ot
IMPLEMENTING AN LSTM FOR T = 1, …, T: (1) (2) (3)
AFTER LSTM NEED A SOFTMAX LAYER TO MAKE A DECISION DO NOT FEED IN RAW IMAGES, FEED IN FEATURES, USE CONVOLUTIONAL LAYERS OF A CNN TO EXTRACT FEATURES Each Image in Sequen ce
SOME FUN LSTM EXAMPLES
IMAGE CAPTIONING • Explain Images with Multimodal Recurrent Neural Networks, Mao et al. • Deep Visual-Semantic Alignments for Generating Image Descriptions, Karpathy and Fei-Fei • Show and Tell: A Neural Image Caption Generator, Vinyals et al. • Long-term Recurrent Convolutional Networks for Visual Recognition and Description, Donahue et al. • Learning a Recurrent Visual Representation for Image Caption Generation, Chen and Zitnick Based on cs 231 n by Fei-Fei Li & Andrej Karpathy & Justin Johnson
RECURRENT NEURAL NETWORK CONVOLUTIONAL NEURAL NETWORK Based on cs 231 n by Fei-Fei Li & Andrej Karpathy & Justin Johnson
TEST IMAGE
TEST IMAGE
TEST IMAGE X
TEST IMAGE X 0 <STA RT> <START>
TEST IMAGE Y 0 BEFORE: H = TANH(WXH * X + WHH * H) H 0 WIH NOW: H = TANH(WXH * X + WHH * H + WIH * X 0 <STA RT> V <START>
TEST IMAGE Y 0 SAMPLE! H 0 X 0 <STA RT> <START> STRA W
TEST IMAGE Y 0 Y 1 H 0 H 1 X 0 <STA RT> STRA W <START>
TEST IMAGE Y 0 Y 1 SAMPLE! H 0 H 1 X 0 <STA RT> STRA W <START> HAT
TEST IMAGE Y 0 Y 1 Y 2 H 0 H 1 H 2 X 0 <STA RT> STRA W <START> HAT
TEST IMAGE Y 0 Y 1 Y 2 SAMPLE <END> TOKEN => FINISH. H 0 H 1 X 0 <STA RT> STRA W <START> H 2 HAT
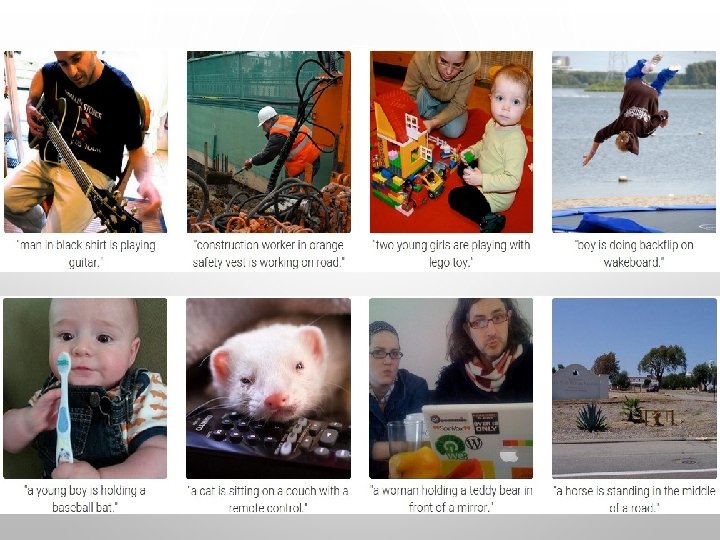
IMAGE SENTENCE DATASETS MICROSOFT COCO [TSUNG-YI LIN ET AL. 2014] MSCOCO. ORG CURRENTLY: ~120 K IMAGES ~5 SENTENCES EACH