SUPER RESOLUTION USING NEURAL NETS Hila Levi Eran


 image from a")
 Widely used")





![Previous work - Example based - External DB ■ [*] W. T. Freeman et](https://slidetodoc.com/presentation_image_h/e418345e3a299fa5dfb003b003d88786/image-10.jpg "Previous work - Example based - External DB ■ [*] W. T. Freeman et")


![Previous work - Example based - using the image ■ [*] J. Huang et](https://slidetodoc.com/presentation_image_h/e418345e3a299fa5dfb003b003d88786/image-13.jpg "Previous work - Example based - using the image ■ [*] J. Huang et")





 ■ PSNR (Peak Signal to Noise Ratio) –")

 ■ Based on two articles: – C. Dong et al,")











")



 ■ Based on: – Z. Wang, et al, Deep networks")











 ■ Based on: – J. Kim et al, Accurate Image")

 ■")









- Slides: 65
SUPER RESOLUTION USING NEURAL NETS Hila Levi & Eran Amar Weizmann Ins. 2016
Lecture Outline ■ Introduction ■ Previous work ■ NN #1 - Dong et al, pure learning ■ NN #2 - Wang et al, domain knowledge integrating ■ NN #3 - Kim et al, pure learning ■ Conclusions
Introduction – Super resolution ■ Goal: obtaining a high resolution (HR) image from a low resolution (LR) input image ■ Ill posed problem ■ Motivation – overcoming the inherent resolution limitations of low cost imaging sensors/compressed images allowing better utilization of high resolution displays
Introduction – Neural Networks Old machine learning algorithm (first work - 1943) Widely used since 2012 (Alex net) Mostly on high-level-vision tasks (classification, detection, segmentation)
Previous work – Single Image Super resolutions ■ ■ Interpolation based – Bilinear, Bicubic, Splines Reconstruction based - Exploiting natural images priors Example based – Using External Database (millions of HR + LR patch pairs) – Using redundancy in the image itself – at different locations and across different scales – Using Predefined dictionary - Sparse Coding Algorithm NN – Image denoising – Image super-resolution
Previous work - Interpolation based ■ Results overly smoothed edges + ringing artifacts
Previous work – Single Image Super resolutions ■ ■ Interpolation based – Bilinear, Bicubic, Splines Reconstruction based - Exploiting natural images priors Example based – Using External Database (millions of HR + LR patch pairs) – Using redundancy in the image itself – at different locations and across different scales – Using Predefined dictionary - Sparse Coding Algorithm NN – Image denoising – Image super-resolution
Previous work - Reconstruction based ■ Limited to small magnification factors ■ L 1 minimization + regularization based on bilateral prior ■ Gradient profile prior
Previous work – Single Image Super resolutions ■ ■ Interpolation based – Bilinear, Bicubic, Splines Reconstruction based - Exploiting natural images priors Example based – Using External Database (lots of HR + LR patch pairs) – Using redundancy in the image itself – at different locations and across different scales – Using Predefined dictionary - Sparse Coding Algorithm NN – Image denoising – Image super-resolution
Previous work - Example based - External DB ■ [*] W. T. Freeman et al, Example based super-resolution, 2002
Previous work – Single Image Super resolutions ■ ■ Interpolation based – Bilinear, Bicubic, Splines Reconstruction based - Exploiting natural images priors Example based – Using External Database (millions of HR + LR patch pairs) – Using redundancy in the image itself – at different locations and across different scales – Using Predefined dictionary - Sparse Coding Algorithm NN – Image denoising – Image super-resolution
Previous work - Example based - using the image ■ Use patch recurrence within and across scales of a single image: ■ [*] D. Glasner, S. Bagon, and M. Irani. Super-resolution from a single image. In ICCV, 2009
Previous work - Example based - using the image ■ [*] J. Huang et al, Single Image Super-resolution from Transformed Self. Exemplars, 2015
Previous work – Single Image Super resolutions ■ ■ Interpolation based – Bilinear, Bicubic, Splines Reconstruction based - Exploiting natural images priors Example based – Using External Database (millions of HR + LR patch pairs) – Using redundancy in the image itself – at different locations and across different scales – Using Predefined dictionary - Sparse Coding Algorithm NN – Image denoising – Image super-resolution
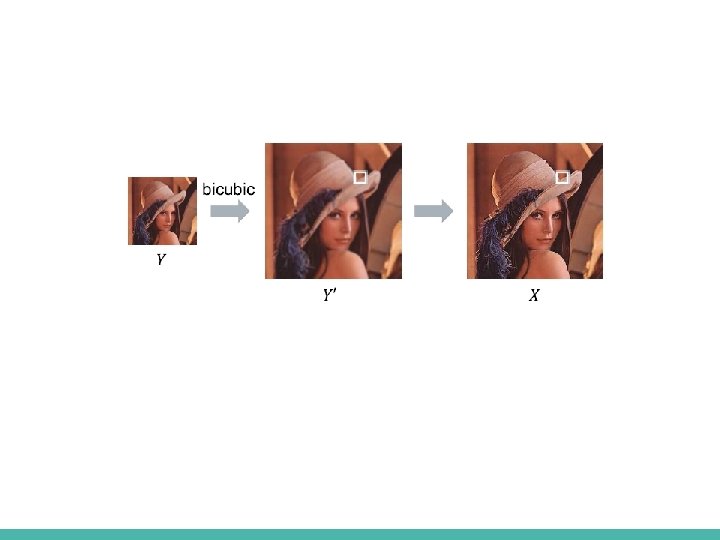
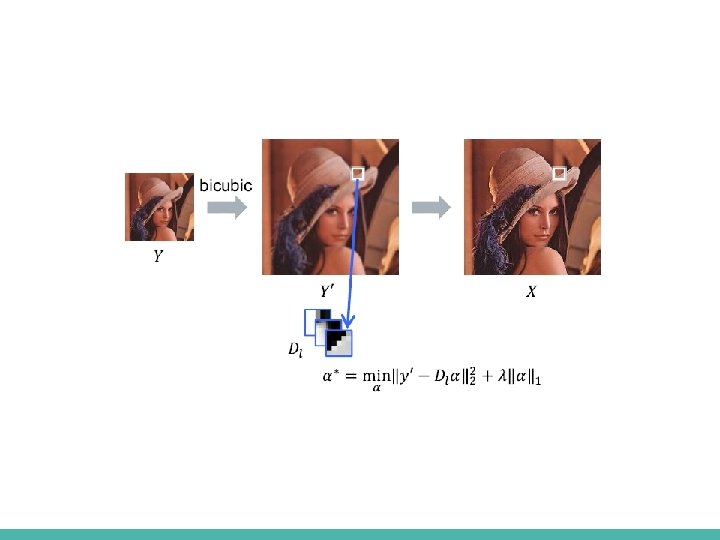
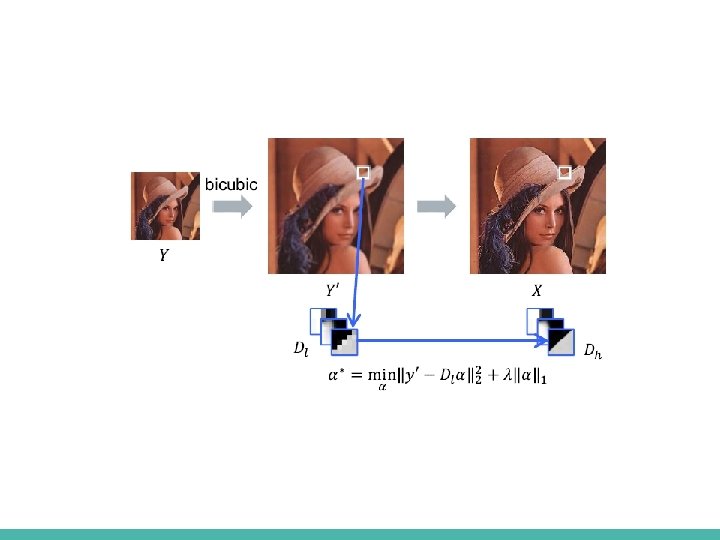
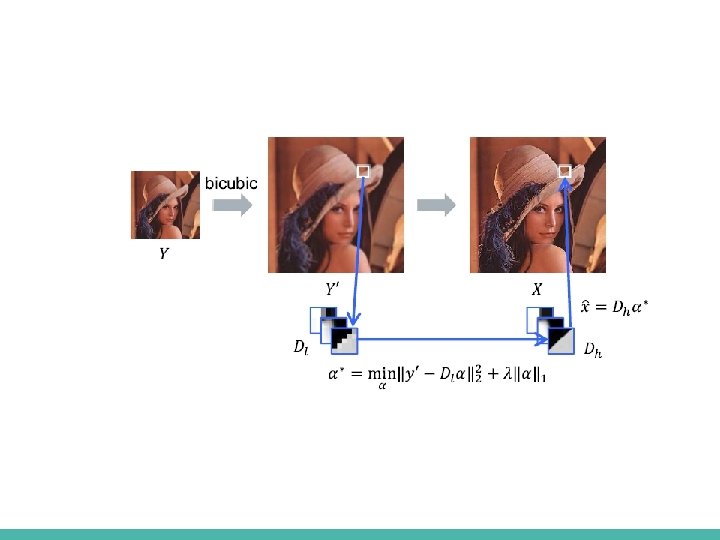
Previous work - Example based - Sparse Coding Suppose we have Jointly Pre-trained HR + LR Dictionaries Typical numbers - 512 9 x 9 patches ■ [*] J. Yang et al, Image SR via sparse representation, IEEE TIP 2010
Previous work - Example based - SC -Sparse code extraction ■ We want to solve – NP hard problem ■ Instead we will solve – Still Sparsity encourage … – Known problem with an iterative solution – ISTA (Iterative Shrinkage and Thresholding Algorithm
Previous work – Single Image Super resolutions ■ Interpolation based ■ Reconstruction based ■ Example based ■ NN – Image denoising – ■ MLP (2012) ■ Image Denoising and Inpainting (2012) – Image super-resolution – ■ Dong et al (2014) ■ Wang et al (2015) ■ Kim et al (2015)
Previous work – Single Image Super resolutions ■ Interpolation based ■ Reconstruction based ■ Example based ■ NN – Image denoising – ■ MLP (2012), ■ Image Denoising and Inpainting (2012) – Image super-resolution – ■ Dong et al (2014) ■ Wang et al (2015) ■ Kim et al (2015)
Metrics ■ MSE (Mean Square Error) ■ PSNR (Peak Signal to Noise Ratio) – Common in image restoration tasks – Partially related to perceptual quality ■ SSIM (Structural SIMilarity index)
Databases ■ Training – 91 images for training – Image. Net ■ Testing – Set 5 – 5 images ( factor 2 3 4) – Set 14 – 14 images (factor 3) – urban 100 – BDS 100 – Imagenet
NN #1 – (SR-CNN) ■ Based on two articles: – C. Dong et al, Learning a deep convolutional network for image SR, ECCV 2014 – C. Dong et al, Image SR using deep convolutional networks, TPAMI 2015
#1 - Contribution of the work
#1 - Super Resolution Pipeline ■ Patch Extraction and representation – extracts overlapping patches and represent each patch by a set of pre-trained bases (PCA, DCT, Haar) ■ Non linear mapping - each LR vector maps conceptually to a HR vector ■ Reconstruction – aggregates the HR vectors to generate HR image
#1 - Relationship to convolutional neural network SR creation stages SR-CNN ■ Patch Extraction and representation ■ Applying a convolutional layer with n 1 filters on the input image ■ Non linear mapping ……………. ■ One (or more) convolutional layers with a nonlinear activation……… ■ Reconstruction ■ Linear convolution on the n 2 feature maps
#1 - Relationship to convolutional neural network SR creation stages SR-CNN ■ Patch Extraction and representation ■ Applying a convolutional layer with n 1 filters on the input image ■ Non linear mapping ……………. ■ One (or more) convolutional layers with a nonlinear activation……… ■ Reconstruction ■ Linear convolution on the n 2 feature maps
#1 - Relationship to convolutional neural network SR creation stages SR-CNN ■ Patch Extraction and representation ■ Applying a convolutional layer with n 1 filters on the input image ■ Non linear mapping ……………. ■ One (or more) convolutional layers with a nonlinear activation……… ■ Reconstruction ■ Linear convolution on the n 2 feature maps
#1 - Relationship to the sparse coding based methods Sparse Coding SRCNN ■ Extract LR patch, Project on a LR dictionary, size n 1 ■ Applying n 1 linear filters on the input image ■ Sparse coding solver, transform to HR sparse code, size n 2 ■ Non linear mapping ………… …. . ■ Linear convolution on the n 2 feature maps ■ Project to HR dictionary, average HR patches
#1 - Pros & Cons ■ Pros – – End to end optimization scheme – Very flexible, standard building blocks ■ Cons – – A very simple network with 3 layers. Limited expressive power – Sparse coding techniques rely on sparsity – there isn’t any mechanism to ensure sparsity
#1 - Training ■ Loss function - MSE ■ Stochastic gradient descent ■ Training data: – 91 images, total of 24800 patches (33 x 33) – 396000 images (Image. Net), 5 million patches ■ Testing – Set 5 – Set 14 – BSD 200 ■ Data creation: – Image bluring – Subsampling – Bicubic interpolation
#1 - Training Data ■ More training data leads to better results ■ The effect of big data is less expressive than in high-level-vision problems – maybe because the relatively small network
#1 - Net Parameters - Filter Size, Net width
#1 - Net Parameters - deeper structure ● The performance was worse than before ● No convergence after a week of training
#1 - Comparison with existing methods ■ SR-CNN 9 -5 -5 (~60 K params) trained on Image. Net
#1 - Conclusions ■ Nice results ■ Pure learning scheme with the simplest architecture exists ■ The comparison to the sparse coding algorithm is not needed ■ Experienced bad convergence properties, that are not usual in classification CNN anymore – probably because no regularizations: – No dropouts, – no batch normalization, – no proper initialization, – no pre-processing
NN #2 – (SCN) ■ Based on: – Z. Wang, et al, Deep networks for image super-resolution with sparse prior. ICCV, 2015
#2 - Contribution of the work ■ Combine the domain expertise of sparse coding and the merits of deep ■ Use network cascading for large and arbitrary scaling factors; ■ Conduct a subjective evaluation on several recent state-of-the-art methods. learning to achieve better SR performance with faster training and smaller model size;
#2 - Reminder – Sparse coding
#2 - Network implementation of sparse coding ■ Based on: – K. Gregor and Y. Le. Cun, Learning fast approximations of sparse coding, ICML 2010 ■ Main idea: – ISTA can be easily implemented as a recurrent network – Adding end-to-end learning (LISTA) – a good approximation can be obtained within a fixed (and small) number of recurrent stages
#2 - Sparse coding based Network ■ Now: – Sparse coding solver – learnable block – Patch wise processing – convolutional layers – Combining all together
#2 - Advantages over previous models ■ Architecture follows exactly the SC based SR method, enabling end-to-end training ■ Net’s block are meaningful – can be initialized by previously learned dictionaries - and further improve by training
#2 - Network cascade ■ SCN - A separate model is needed to be trained for each scaling factor ■ CSCN – cascade of SCNs
#2 - Training ■ Loss function - MSE ■ Stochastic gradient descent ■ Training data: – 91 images, total of 24800 patches (33 x 33), data augmentation Testing – Set 5 – Set 14 – BSD 100 ■ ■ Data creation: – Image bluring – Subsampling – Bicubic interpolation
#2 - Comparison with existing methods
#2 - Subjective evaluation
#2 - Conclusions
NN #3 – (VDSR) ■ Based on: – J. Kim et al, Accurate Image Super-Resolution Using Very Deep Convolutional Networks, ar. Xiv: 1511. 04587, 2015
#3 - Contribution of the work ■ Highly accurate SR method based on a very deep convolutional network ■ Boosting convergence rate using residual learning and gradient clipping ■ Extension to multi-scale SR
#3 - Proposed network ■ Inspired by the VGG net (Simonyan & Zisserman) ■ 20 layers, each consists of 64 feature maps using 3 x 3 filters
#3 - The deeper – the better ■ Deeper network results in: – Larger receptive field per output pixel (more information) – More expressive functions
#3 - Residual Learning ■ Much faster convergence ■ Superior performance
#3 - Training ■ Loss function - MSE ■ Stochastic gradient descent ■ Training data: – 291 images, data augmentation ■ Testing – Set 5 – Set 14 – B 100 – Urban 100 ■ Data creation: – Image bluring – Subsampling – Bicubic interpolation
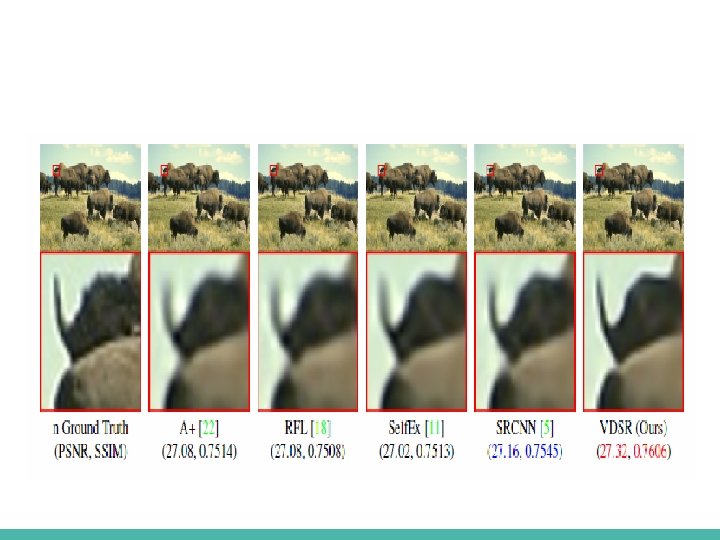
#3 - Comparison with existing methods
#3 - Conclusions ■ Better results than the former method ■ Elegantly organized work, the residual prediction is a nice idea ■ Can be easily applied to other image restoration domains
just another last slide Domain Expertise vs. End-to-End optimization How to utilize Neural Networks for algorithmic challenges? One possible approach, is to try to combine the network with existing wellengineered algorithms (“physically” or by better initialization). On the other hand, there is a “pure” learning approach which looks at the NN as a “black box”. That is, one should build a network with some (possibly customized) architecture and let it optimize its parameters jointly in an end-to-end manner. In this talk we will discuss those two approaches for the task of image restoration.
references ■ ■ A. Beck and M. Teboulle, A fast iterative shrinkage-thresholding algorithm with application to wavelet based image deblurring, ICASSP 2009 D. Glasner, S. Bagon, and M. Irani. Super-resolution from a single image. In ICCV, 2009 ■ K. Gregor and Y. Le. Cun, Learning fast approximations of sparse coding, ICML 2010 ■ J. Yang et al, Image SR via sparse representation, IEEE TIP 2010 ■ C. Dong et al, Learning a deep convolutional network for image SR, ECCV 2014 ■ C. Dong et al, Image SR using deep convolutional networks, TPAMI 2015 ■ J. Kim et al, Accurate Image Super-Resolution Using Very Deep Convolutional Networks, ar. Xiv: 1511. 04587, 2015 ■ Z. Wang, et al, Deep networks for image super-resolution with sparse prior. ICCV, 2015
Any questions?