High Performance Computing Technologies Lecture 1 Parallel Computing



















 OS: Scientific Linux 7. 6 x. CAT FS: NFS")




 #!/bin/sh # Select partition name (default name")





 is an API that supports multi-platform shared memory")
 открытый стандарт для распараллеливания программ на языках Fortran,")
 is an API that supports multi-platform shared memory")
 is an API that supports multi-platform shared memory")

 Compiler Flag Information -fopenmp GNU")

 Compiler directive Thread 0 Thread 1 Thread 2 Master thread")
 Library routines Compiler directive export OMP_NUM_THREADS=3 Use flag")










 parallelism and High level parallelism: directive section Low level parallelism: the")


 { #pragma")



 { int i; double")
; Description:")
 parallelism and High level parallelism: directive section Low level parallelism: the")

{ int i; #pragma omp parallel")







> eps*3 && iter< Maxit ){")



")
")

- Slides: 80
High Performance Computing Technologies. Lecture 1 Parallel Computing with Open. MP : https: //indico-hlit. jinr. ru/event/124/ O. I. Streltsova, D. V. Podgainy, M. V. Bashashin Heterogeneous Computations Team, Hybri. LIT Laboratory of Information Technologies Joint Institute for Nuclear Research Dubna University 07 February 2019 Heterogeneous Computation Team, Hybri. LIT
Hybri. LIT: heterogeneous computation cluster Scientific Linux 6. 9 HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Hybri. LIT: heterogeneous computation cluster The cluster contains 10 computational nodes with graphical accelerators NVIDIA Tesla K 20 X, K 40, K 80, Intel Xeon Phi 7120 P, 5110 coprocessors. All computational nodes include two Intel Xeon E 5 -2695 v 2 and V 3 processors each. Computation component Hybri. LIT TOTAL RESOURCES 252 CPU cores; 77184 CUDA cores; 182 MIC cores; ~2, 5 Tb RAM; ~57 Tb HDD. HARDWARE Super. Blade Chassis including 10 calculation blades for run user tasks. 7 blades include specific GPU accelerator sets. Driven by NVIDIA CUDA software. 1 blade includes 2 PHI accelerators. Driven by Intel MPSS software. 1 blade includes 1 PHI and 1 GPU accelerators. Mixed NVIDIA CUDA and Intel MPSS software. 1 blade includes 2 multi-core CPU processors. Large ~7 Tb storage area
Hybri. LIT: heterogeneous computation cluster
NVIDIA Tesla K 40 “Atlas” GPU Accelerator NVIDIA Tesla K 80 GPU Accelerator Specifications Tesla K 40 2880 CUDA GPU cores Memory 12 GB GDDR 5 Peak precision floating point performance 4. 29 TFLOPS single-precision 1. 43 TFLOPS double-precision Tesla K 80 Number of GPUs: 2 x Kepler GK 210 4992 (2496 per GPU) CUDA GPU cores Memory 24 GB (12 GB per GPU) Peak precision floating point performance 8. 74 TFLOPS single-precision (with GPU Boost) 2. 91 TFLOPS double-precision (with GPU Boost) HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
From Hybri. LIT cluster to Hybri. LIT platform The supercomputer is a natural continuation of heterogeneous platform and leads to a significant increase in the performance of both CPU and GPU components. 2014 Total peak performance: 140 TFlops for single precision; 50 TFlops for double precision 2018 Total peak performance: 1000 TFlops for single precision; 500 TFlops for double precision
ГЕТЕРОГЕННАЯ ВЫЧИСЛИТЕЛЬНАЯ ПЛАТФОРМА Hybri. LIT СУПЕРКОМПЬЮТЕР «ГОВОРУН» Учебно-тестовый полигон Hybri. LIT CPU-компонента Intel Skylake, Intel Xeon Phi (KNL), Intel Omni-Path GPU-компонента GPU DGX-1 Volta (NVIDIA Tesla V 100), Infini. Band Intel Xeon Phi Intel Xeon Nvidia Tesla K 20 Nvidia Tesla K 40 Heterogeneous Computation Team, Hybri. LIT Nvidia Tesla K 80
Hybri. LIT СУПЕРКОМПЬЮТЕР ДЛЯ ЛТФ И ПРОТОТИПА ДЛЯ ПРОЕКТА NICA Производительность: 164 TFlops 2 x CPU: Intel Xeon Gold 6154 (Skylake-SP 18 -Core 3. 0 GHz) 40 nodes Intel® Omni-Path Architecture Intel Xeon Phi 7290 Processor (KNL): 72 cores, 386 GB Параллельная система хранения данных на серверах с 2 -мя процессорами Intel Skylake и с 24 дисками SSD NVMe Емкость 120 TB, Скорость 100 GB/s 21 nodes 5 nodes Intel® Omni-Path Architecture ПСХД планируется в конце 2018 Heterogeneous Computation Team, Hybri. LIT
Hybri. LIT СУПЕРКОМПЬЮТЕР ДЛЯ ЛТФ И ПРОТОТИПА ДЛЯ ПРОЕКТА NICA Производительность: 500 TFlops Узлы с GPU DGX-1 Volta (8 GPU на узел) NVIDIA® Tesla® V 100 GPU 5 nodes NVIDIA® Tesla® V 100 GPU NVLink™ Производительность: 7, 5 Tflops (double precision) GPU Memory 16 GB HBM 2, Memory Bandwidth 900 GB/sec Heterogeneous Computation Team, Hybri. LIT
KNL: Intel’s Xeon Phi 14 nm ‘Knights Landing’ Processors The official launch of the new processor was announced at the ISC High Performance conference (ISC), which is taking place this week in Frankfurt. Intel® Xeon Phi™ Processor 7290 F (16 GB, 1. 50 GHz, 72 core) Source: http: //ark. intel. com/products/95831/Intel-Xeon-Phi-Processor-7290 F-16 GB-1_50 -GHz-72 -core/
Parallel technologies: levels of parallelism #node 1 In the last decade novel computational technologies and facilities becomes available: MP-CUDA-Accelerators? . . . How to control hybrid hardware: MPI – Open. MP – CUDA - Open. CL. . . #node 2
Intel: compilers, tools for developing, debugging and profiling parallel applications, mathematical library …. Intel Inspector Intel VTune Memory and Threading Checking Amplifier Performance Profiler Intel Math Kernel Library Intel Data Analytics Acceleration Library Optimized Routines for Science, Engineering, and Financial Optimized for Data Analytics & Machine Learning Intel Advisor Vectorization Optimization and Thread Prototyping Intel® Integrated Performance Primitives Image, Signal, and Compression Routines Intel Threading Building Blocks Task-Based Parallel C++ Template Library Source: https: //software. intel. com/enus/articles/intel-parallel-studio-xerelease-notes Heterogeneous Computation Team, Hybri. LIT
Some GPU-accelerated Libraries NVIDIA cu. BLAS NVIDIA cu. RAND NVIDIA cu. SPARSE Vector Signal Image Processing GPU Accelerated Linear Algebra Matrix Algebra on GPU and Multicore IMSL Library Building-block Array. Fire Matrix Algorithms for Computations CUDA Sparse Linear Algebra NVIDIA NPP NVIDIA cu. FFT C++ STL Features for CUDA Source: https: //developer. nvidia. com/cuda-education. (Will Ramey , NVIDIA Corporation)
GPU-accelerated application Over 300 applications are optimized for the GPUs computation Computational Finance Defense and Intelligence Machine Learning Manufacturing Media and Oil and Gas Research: Higher Education and Supercomputing (COMPUTATIONAL CHEMISTRY; BIOLOGY NUMERICAL ANALYTICS PHYSICS) • Safety and Security • • • NUMERICAL ANALYTICS: MATLAB – Mathworks GPU acceleration for MATLAB (high-level technical computing language) Support for 200+ of most used MATLAB functions (incl. Signal Processing, Image Processing, Communications Systems, etc) PHYSICS QUDA Library for Lattice QCD calculations using GPUs. CUDA supports the following fermion formulations: Wilson, Wilson-clover, Twisted mass, Improved staggered (asqtad or HISQ) and Domain wall. Molecular Dynamics: NAMD - Designed for highperformance simulation of large molecular systems; Source: http: //www. nvidia. com/content/gpu-applications/PDF/GPU-apps-catalog-mar 2015. pdf
Software for parallel calculations § Open. MPI 1. 8. 1, 2. 0. 1 -1, 2. 1. 2 -1 § Open. MP GCC, ICC § Intel Cluster Studio 2018, 2019 § CUDA 7. 0, CUDA 8. 0, CUDA 9. 2, CUDA 10. 0 § Python-modules HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Remote access to the cluster Remote access to the Hybri. LIT available only via SSH protocol. DNS address of cluster is hydra. jinr. ru For Linux users: Launch the terminal, type in the command line: $ ssh username@hydra. jinr. ru where username is your login home: ~ > ssh zuev@hydra. jinr. ru's password: Last login: Mon Oct 3 11: 25: 36 2016 from lxpub 01. jinr. ru ************************************* * Dear users! * * Hybri. LIT Cluster Maintenance. . . ************************************* [zuev@hydra ~]$
Remote access to the cluster Remote access to the Hybri. LIT available only via SSH protocol. DNS address of cluster is hydra. jinr. ru For Windows users: In order to connect from the Windows OS, it is necessary to use a special program – SSH-client, e. g. Pu. TTY. To install Pu. TTY, it is necessary to copy putty. exe file to your computer and launch it. 2. 1.
Remote access to the cluster For Windows users: 2. 1. 3. 4.
System Level SLURM (workload manager) OS: Scientific Linux 7. 6 x. CAT FS: NFS FS: ZFS FS: EOS (Cluster Administration Toolkit) Hybri. LIT Software and Information Environment Software for parallel computing: Open. MPI 1. 8. 8, 2. 0. 1, 2. 1. 2, 3. 1. 1. ; CUDA 7. 0, 8. 0, 9. 2, 10. ; GNU 4. 8. 5, 7. 2. 0 -1, 8. 2. 0 -1 Intel Parallel Studio XE 2018, 2019 Cern. VM-FS (Virtual Software Appliance) Free. IPA MODULES (identity manager solution) Hybri. LIT web-site User level http: //hybrilit. jinr. ru/ Indico: http: //indico-hybrilit. jinr. ru Git. Lab: https: //gitlab-hybrilit. jinr. ru Hybri. LIT user support: https: //pm. jinr. ru/projects/hybrilit-user-support Monitoring: https: //home-hlit. jinr. ru/ Monitoring (Mobi. LIT): http: //hybrilit. jinr. ru/mobilit/
System software Steps to run app Scientific Linux 7. 5. MODULES 3. 2. 10 To set environment variables; Parallel technologies for C/C++, Fortran: CUDA, MPI, Open. CL; SLURM 17. 02. 9 To run applications use batch mode; Step 1: $module add Step 2: compile application Step 3: run application
Run task Step 1: module add $ module avail $ module add openmpi/v 1. 8. 8 -1 $ module add cuda/v 9. 0 -2 $ module list Step 2: compile application $ mpicc source_mpi. c –o exec_mpi $ nvcc source_cuda. cu –o exec_cuda Step 3: run application $ sbatch script_name
Run task $ cat script_mpi. sh #!/bin/sh #SBATCH –p tut #SBATCH –n 4 #SBATCH –t 60 mpirun. /exec_mpi $ cat script_cuda. sh #!/bin/sh #SBATCH –p tut #SBATCH – –gres=gpu: 1 #SBATCH –t 60. /exec_cuda -p – Partition to run applications: interactive (default), cpu, gpu, long, tut; -n – Number of process. Maximum 48 or 56 per node; --gres=gpu: 1 – Allocation 1 GPU. Maximum 3 or 4 gpu per GPU node; -t – Calculation time (minutes). Default 60 minutes, maximum 24 hours or 14 days for “long” queue.
SLURM: main parameters of script file (1) #!/bin/sh # Select partition name (default name is “interactive”): #SBATCH -p tut # Number of nodes: #SBATCH -N 1 # Number of core (it is equal number of parallel process): #SBATCH -n 1 # Set max time of task. Default value is 60 minute. Available # following formats: # minutes, minutes: seconds, hours: minutes: seconds, # days-hours, days-hours: minutes: seconds. #SBATCH -t 60
Efficient parallelization of complex numerical problems in computational physics HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Goal: Efficient parallelization of complex numerical problems Triad of mathematical modeling * "model - algorithm - program” Model Object Program Algorithm Parallel Program *Самарский А. А. , Михайлов А. П. Математическое моделирование. Идеи, методы, примеры. М. : На ука, 2001. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Designing Parallel Algorithms and Building Parallel Programs PCAM: a design methodology for parallel programs * 1. Partitioning. The computation that is to be performed and the data operated on by this computation are decomposed into small tasks. . 2. Communication. The communication required to coordinate task execution is determined, and appropriate communication structures and algorithms are defined. 3. Agglomeration. The task and communication structures defined in the first two stages of a design are evaluated with respect to performance requirements and implementation costs. 4. Mapping. Each task is assigned to a processor in a manner that attempts to satisfy the competing goals of maximizing processor utilization and minimizing communication costs. *Foster I. Designing and Building Parallel Programs: Concepts and Tools for Software Engineering. Reading, MA: Addison Wesley, 1995 (http: //www. mcs. anl. gov/~itf/dbpp/ ) HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Designing Parallel Algorithms and Building Parallel Programs P r o b L E m Partitioning Agglomeration Communication Mapping HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
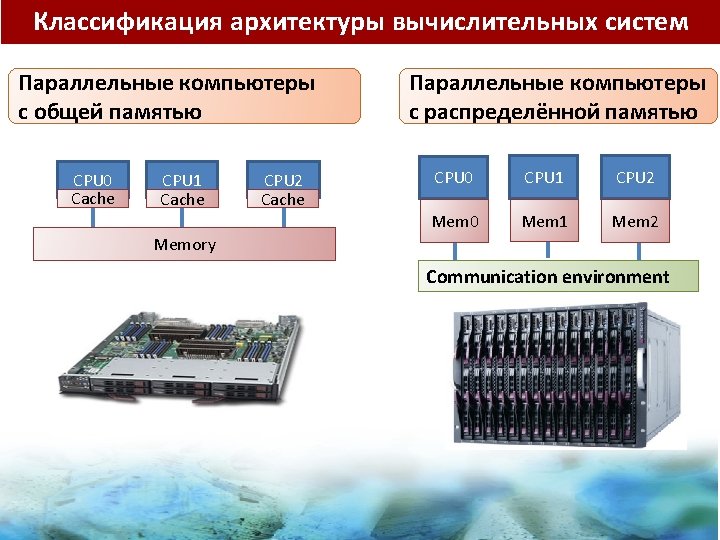
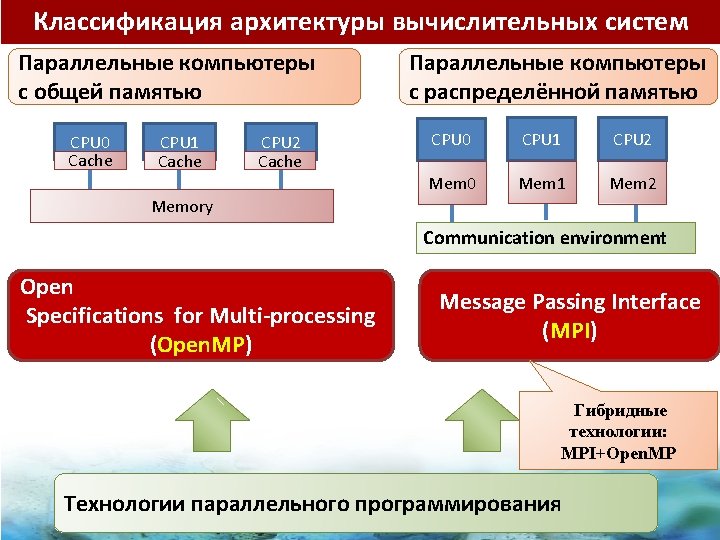
Классификация архитектуры вычислительных систем Классификация по способу организации памяти: Shared-Memory Parallel Computers Uniform Memory Access CPU 0 Cache CPU 1 Cache CPU 2 Cache Memory Non-Uniform Memory Access (cc. NUMA) CPU CPU CPU Bus Interconnect CPU Memory CPU 0 CPU 1 CPU 2 Mem 0 Mem 1 Mem 2 Memory Communication environment Memory Параллельные компьютеры с распределённой памятью Параллельные компьютеры с общей памятью
Open. MP (Open specifications for Multi-Processing) is an API that supports multi-platform shared memory multiprocessing programming in Fortran, C, C++. • Compiler directives • Library routines • Environment variables Open. MP is managed by consortium Open. MP Architecture Review Board (or Open. MP ARB) from 1997 Open. MP website: http: //openmp. org/ Open. MP for Fortran 1. 0, in 1997 С/C++ in 1998 Open. MP for Fortran 2. 0, in 2000 С/C++ in 2002 Version 3. 0 was released in May 2008. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT Version 4. 0 July 2013
Open. MP (Open specifications for Multi-Processing) открытый стандарт для распараллеливания программ на языках Fortran, C, C++. Open. MP работает в системах с общей памятью и основан на понятии «легковесного процесса» или нити (thread). Open. MP website: http: //openmp. org/ • Compiler directives (набор директив компилятора) • Library routines (набор библиотечных процедур ) • Environment variables (набор переменных среды) Open. MP is managed by consortium Open. MP Architecture Review Board (or Open. MP ARB) from 1997 Open. MP for Fortran 1. 0, in 1997 С/C++ in 1998 Open. MP for Fortran 2. 0, in 2000 С/C++ in 2002 Version 3. 0 was released in May 2008. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT Version 4. 0 July 2013
Open. MP (Open specifications for Multi-Processing) is an API that supports multi-platform shared memory multiprocessing programming in Fortran, C, C++. • Library routines • Compiler directives • Environment variables export OMP_NUM_THREADS=3 Master-thread #pragma omp parallel thread-0 thread-1 thread-2 Master-thread http: //openmp. org/wp/
Open. MP (Open specifications for Multi-Processing) is an API that supports multi-platform shared memory multiprocessing programming in Fortran, C, C++. Library routines Compiler directives Environment variables Master-thread #pragma omp parallel thread-0 thread-1 export OMP_NUM_THREADS=3 thread-2 Master-thread http: //openmp. org/wp/
Open. MP compilers (Full list at http: //openmp. org/wp/openmp-compilers/) Compiler Flag Information -fopenmp GNU gcc 4. 2 – Open. MP 2. 5 gcc 4. 4 – Open. MP 3. 0 gcc 4. 7 – Open. MP 3. 1 gcc -fopenmp start_openmp. c -o test 1 gcc 4. 9 – Open. MP 4. 0 Intel C/C++ and Fortran -qopenmp on Linux or Mac OSX -Qopenmp on Windows icc -qopenmp start_openmp. c -o test 1 Portland Group Compilers and Tools -mp • Open. MP 3. 1 API Specification • Support for most of the new features in the Open. MP* 4. 0 API Specification Full support for Open. MP 3. 1 pgcc -mp start_openmp. c -o test 1 HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
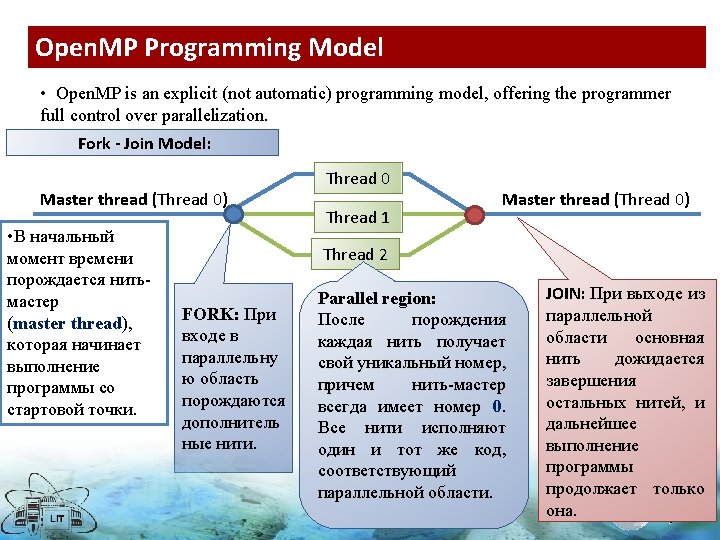
Master thread (Thread 0) Compiler directive Thread 0 Thread 1 Thread 2 Master thread (Thread 0) Compiler directive Thread 0 Thread 1 Master thread (Thread 0) Thread 2
Open. MP (Open specifications for Multi-Processing) Library routines Compiler directive export OMP_NUM_THREADS=3 Use flag -qopenmp to compile using Intel compilers: icc –qopenmp code. c –o code
Open. MP: Construct parallel C / C++ , General Code Structure : #include <omp. h> main () { // Serial code ……… //Fork a team of threads: #pragma omp parallel {. . . structured block. . . } //Resume serial code ……. . } Fortran , General Code Structure: PROGRAM Start !Serial code !. . ! //Fork a team of threads: !$OMP PARALLEL. . . structured block. . . !$OMP END PARALLEL ! Resume serial code END • The parallelism has to be expressed explicitly. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Open. MP: Construct parallel #pragma omp parallel { structured block } #pragma omp parallel [clause. . . ] newline if (scalar_expression) private (list) shared (list) default (shared | none) firstprivate (list) reduction (operator: list) copyin (list) num_threads (integer-expression) { structured block } Meaning: • The entire code block following the parallel-directive is executed by all threads concurrently • This includes: - creation of team of ”worker” threads - thread executes a copy of the code within the structured block - barrier synchronization (implicit barrier) - termination of worker threads. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Private variables and Shared variables Shared: the data within a parallel region is shared, which means visible and accessible by all threads simultaneously. Private: the data within a parallel region is private to each thread, which means each thread will have a local copy and use it as a temporary variable. ……… int a; // shared automatic int j; int k=3; #pragma omp parallel private (j, k) { int b; //private automatic b=j ; What if we need to initialize a private variable? firstprivate: private variables with initial values copied from the master thread’s copy //b is not defined foo (j, b, k); } HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Specification of number of threads Setting Open. MP environment variables is done the same way you set any other environment variables, and depends upon which shell you use. sh/tcsh setenv OMP_NUM_THREADS 4 sh/bash export OMP_NUM_THREADS=4 Via runtime functions: omp_set_num_threads(4); Other useful function to get information about threads: Runtime function omp_get_num_threads() • Returns number of threads in parallel region • Returns 1 if called outside parallel region Runtime function omp_get_thread_num() • Returns id of thread in team (Value between [0, Nthreads-1] ) • Master thread always has id 0 HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Example 1: start_openmp. c Location: /nfs/store 2. jinr. ru/scratch/2017 -Tutorial-University/Open. MPstart File: start_openmp. c $ module add intel/v 2018. 1. 163 -9 1. Compilation: icc -qopenmp start_openmp. c -o test 1 3. cat script_openmp. sh ( in it see export OMP_NUM_THREADS=5) 4. sbatch script_openmp. sh Exercise #1: change the value num_threads(2) (line 39) Exercise #2: comment #pragma omp barrier (line 32) HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Open. MP: script_openmp 2 env. sh - output OPENMP DISPLAY ENVIRONMENT BEGIN _OPENMP='201511' https: //gcc. gnu. org/onlinedocs/libgomp [host] OMP_CANCELLATION='FALSE' /Environment-Variables. html [host] OMP_DEFAULT_DEVICE='0' [host] OMP_DISPLAY_ENV='TRUE' [host] OMP_DYNAMIC='FALSE' [host] OMP_MAX_ACTIVE_LEVELS='2147483647' [host] OMP_MAX_TASK_PRIORITY='0' [host] OMP_NESTED='FALSE' [host] OMP_NUM_THREADS='5' [host] OMP_PLACES: value is not defined [host] OMP_PROC_BIND='false' [host] OMP_SCHEDULE='static' [host] OMP_STACKSIZE='4 M' [host] OMP_THREAD_LIMIT='2147483647' [host] OMP_WAIT_POLICY='PASSIVE‘ OPENMP DISPLAY ENVIRONMENT END HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Explicit (low level) parallelism and High level parallelism: directive section Low level parallelism: the work is distributed between threads by means functions omp_get_thread_num (Returns the thread number of the thread executing within its thread team. ) omp_get_num_threads (returns the number of threads in the parallel region. ). #pragma omp parallel { if(omp_get_thread_num()) ==3 ) { < code for the thread number 3 >; } else { < code for all another threads >; } } EXAMPLE of high level parallelism (parallel independent sections): #pragma omp sections […[parameters…]] { #pragma omp section Each of block 1 { and block 2 < block 1> in this example } will be carried #pragma omp section out by one of { parallel treads. < block 2> } } HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Work Sharing Constructs in Open. MP The for directive specifies that the iterations of the loop immediately following it must be executed in parallel by the team. This assumes a parallel region has already been initiated, otherwise it executes in serial on a single processor. #pragma omp for [clause. . . ] newline shedule ( type [ chunk]) ordered private (list) firstprivate (list) lastprivate (list) shared (list) reduction (operator: list) collapse ( n ) nowait int i; #pragma omp parallel private(i) { #pragma omp for (i=0; i<N; i++) { array[i] =foo(i); } } for_loop HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Work Sharing Constructs in Open. MP int i; #pragma omp parallel private(i) { #pragma omp for (i=0; i<N; i++) { array[i] =foo(i); } } int i; #pragma omp parallel for private(i) for (i=0; i<N; i++) { array[i] =foo(i); } Directive for: • distributes loop iterations among (already running) threads • does not start / stop any threads • performs a synchronization barrier • Implicit barrier at the end of the for loop, can be disabled with the nowait clause HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Reductions The reduction clause performs a reduction on the variables that appear in its list. reduction (operator : list) • the variable has a local copy in each thread, but the values of the local copies will be summarized (reduced) into a global shared variable operator init() values + (addition) 0 - (subtraction) 0 *(multiplication) 1 &(bitwise and) ~0 |(bitwise or) 0 ^(bitwise exclusive or) 0 && (conditional and) 1 || (conditional or) 0 C and C++ reduction applies to the following directives: • for • parallel • sections HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Example 3: Reduction Scalar product: File: …/Open. MP/scalar. Dot_openmp. c Exercise #4: optimize the program to include in parallel part of the initialization vectors Exercise #5: Create a program that computes the Pi. Use Open. MP directives to make it run in parallel. Heterogeneous Computation Team, Hybri. LIT
Reduction #include <stdio. h> #include <stdlib. h> #include <omp. h> #define Nvec 20000000 int main(){ //. . . Initialization. . . // int i; double* A; double* B; variables for timing double sum; double Time_start, Time_stop ; A = (double*) malloc(Nvec*sizeof(double)); B = (double*) malloc(Nvec*sizeof(double)); sum = 0. 0; //. . . . . // printf("Number of threads = %dn", omp_get_max_threads()); Time_start = omp_get_wtime(); //. . . . . // #pragma omp parallel private (i) shared (A, B) { #pragma omp for (i=0; i < Nvec; i++){ A[i] = 2. 0 ; B[i] = (double) i / (double) (Nvec -1); } #pragma omp for reduction(+: sum) for (i=0; i < Nvec; i++) { sum = sum + A[i]*B[i]; } sum = sum + exp(-(sin(A[i])*si } //. . . . . // Time_stop = omp_get_wtime(); sum); printf("Scalar product (A, B) = %f n", printf("Computation Time(sec): %. 5 fn", Time_stop- Time_start); free(A); free(B); } Heterogeneous Computation Team, Hybri. LIT
Exercise #5 Serial code: #define N 200000 void main () { int i; double x, pi, h; sum = 0. 0; h = 1. 0/(double) N; for (i=0; i< N; i++){ x = (i+0. 5)*h; sum = sum + 4. 0/(1. 0+x*x); } pi = h * sum; } Heterogeneous Computation Team, Hybri. LIT
Open. MP Time Measurement Function signature: #include <omp. h> double omp_get_wtime( void ); Description: Elapsed wall clock time in seconds. //………… double start, end, Time; start = omp_get_wtime(); //beginning of computation. . . //end of computation end = omp_get_wtime(); //Measuring the elapsed time (in seconds) Time = end-start; omp_get_wtick () – Get timer precision Description: Gets the timer precision, i. e. , the number of seconds between two successive clock ticks. C/C++ prototype: double omp_get_wtick(void); Heterogeneous Computation Team, Hybri. LIT
Explicit (low level) parallelism and High level parallelism: directive section Low level parallelism: the work is distributed between threads by means functions omp_get_thread_num (Returns the thread number of the thread executing within its thread team. ) omp_get_num_threads (returns the number of threads in the parallel region. ). #pragma omp parallel { if(omp_get_thread_num()) ==3 ) { < code for the thread number 3 >; } else { < code for all another threads >; } } EXAMPLE of high level parallelism (parallel independent sections): #pragma omp sections […[parameters…]] { #pragma omp section Each of block 1 { and block 2 < block 1> in this example } will be carried #pragma omp section out by one of { parallel treads. < block 2> } } HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Clause SCHEDULE: Describes how iterations of the loop are divided among the threads in the team. The default schedule is implementation dependent. - STATIC - Loop iterations are divided into pieces of size chunk and then statically assigned to threads. If chunk is not specified, the iterations are evenly (if possible) divided contiguously among the threads. - DYNAMIC - RUNTIME - AUTO - GUIDED #define N 12 0 1 2 3 4 5 6 7 8 9 10 11 int main(){ int i; Thread 0 Thread 1 Thread 2 Thread 3 Thread 0 Thread 1 #pragma omp parallel private (i) { #pragma omp for schedule (static, 2) ordered for( i= 0; i<=N; i++){ #pragma omp ordered { printf("Threads %d i= %dn", omp_get_thread_num(), i); } } HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Example 2: schedule_openmp. c #define N 12 int main(){ int i; #pragma omp parallel private (i) { #pragma omp for schedule (static, 2) ordered for( i= 0; i<=N; i++){ #pragma omp ordered { printf("Threads %d i= %dn", omp_get_thread_num(), i); } } 0 1 2 3 4 5 6 7 8 9 10 11 Thread 0 Thread 1 Thread 2 Thread 3 Thread 0 Thread 1 Exercise #3: change the size chunk: 1, 3, 4 HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Goal: Efficient parallelization of complex numerical problems Mode l Triad of mathematical modeling * "model - algorithm - program” Object Program Algorith m Parallel Algorithm Parallel Program *Самарский А. А. , Михайлов А. П. Математическое моделирование. Идеи, методы, примеры. М. : На ука, 2001. HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Model HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
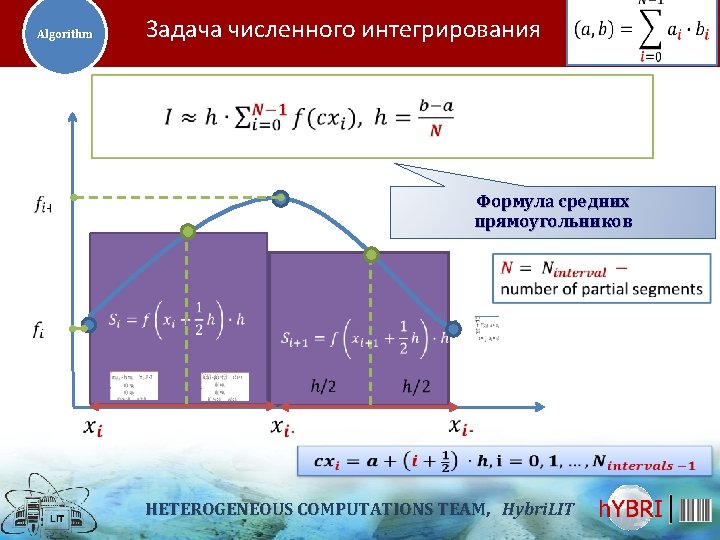
Consistent integration using the trapezoidal rule Calculate a double integral: We will compute the double integral as the iterated integral. The method of re-use of quadrature formulas: Trapezoidal rule: Heterogeneous Computation Team, Hybri. LIT
Consistent integration using the trapezoidal rule Trapezoidal rule: Heterogeneous Computation Team, Hybri. LIT
Consistent integration using the trapezoidal rule Rule of C. Runge - the methods for estimating errors in numerical integration Heterogeneous Computation Team, Hybri. LIT
Open. MP realization: while ( fabs(sum 2 -sum 1)> eps*3 && iter< Maxit ){ // Integration(); ………. } program variant 1 (may be optimized) #pragma omp parallel for reduction(+: sum 2) private (i, j) for( i= 0; i<=Npoint; i+= 2){ for( j= 1; j<=Npoint; j+= 2){ sum 2 +=fcomp(a+i*hx, c+j*hy)*Qij(i, j, Npoint)*hx*hy; } } #pragma omp for reduction(+: sum 2) private (i, j) for( i= 1; i<=Npoint; i+= 2){ for( j= 0; j<=Npoint; j++){ sum 2 += fcomp(a+i*hx, c+j*hy)*Qij (i, j, Npoint)*hx*hy; } } Heterogeneous Computation Team, Hybri. LIT
Open. MP realization: optimizations 1. Сombine the two into a single parallel region 2. Сreate a single parallel region, which means to parallelize while ( boolean condition) {…. . } while ( fabs(sum 2 -sum 1)> eps*3 && iter< Maxit ){ // Integration(); ………. } Heterogeneous Computation Team, Hybri. LIT
Open. MP environment variables: script_openmp 2 env. sh Location: nfs/store 2. jinr. ru/scratch/Tutorials/2017/Open. MP File: script_openmp 2 env. sh 1. 2. 3. 4. 5. 6. 7. #!/bin/sh # Example with 5 cores for Open. MP #SBATCH -p tut # Number of cores per task #SBATCH -c 5 #Set OMP_NUM_THREADS to the same# value as –c if [ -n "$SLURM_CPUS_PER_TASK" ]; then omp_threads=$SLURM_CPUS_PER_TASK 8. else omp_threads=1 9. fi 10. export OMP_NUM_THREADS=$omp_threads 11. export OMP_DISPLAY_ENV=TRUE 12. . /test 1 13. # End of submit file HETEROGENEOUS COMPUTATIONS TEAM, TEAM Hybri. LIT
Predicting and Measuring Parallel Performance The success of parallelization is typically quantified by measuring the speedup of the parallel version relative to the serial version. Speedup of parallel execution: One computed number that offers a tangible comparison of serial and parallel execution time is speedup: Efficiency of parallel execution: Speedup is a metric to determine how much faster parallel execution is versus serial execution. Efficiency indicates how well software utilizes the computational resources of the system. [1] Predicting and Measuring Parallel Performance: https: //software. intel. com/sites/default/files/m/d/4/1/d/8/1 -1 -App. Thr_-_Predicting_and_Measuring_Parallel_Performance. pdf [2] Гергель В. П. Теория и практика параллельных вычислений. - М. : БИНОМ. Лаборатория знаний: ИНТУИТ. РУ, 2010. - 423 с. Heterogeneous Computation Team, Hybri. LIT
Predicting and Measuring Parallel Performance The estimation of the amount of performance increase (speedup) that can be realize. Amdahl’s Law: Heterogeneous Computation Team, Hybri. LIT
Predicting and Measuring Parallel Performance The estimation of the amount of performance increase (speedup) that can be realize. Gustafson- Barsis’s Law: Gustafson-Barsis’s Law, also known as scaled speedup, speedup takes into account an increase in the data size in proportion to the increase in the number of cores and computes the (upper bound) speedup of the application, as if the larger data set could be executed in serial. [1] Predicting and Measuring Parallel Performance: https: //software. intel. com/sites/default/files/m/d/4/1/d/8/1 -1 -App. Thr_-_Predicting_and_Measuring_Parallel_Performance. pdf [2] Гергель В. П. Теория и практика параллельных вычислений. - М. : БИНОМ. Лаборатория знаний: ИНТУИТ. РУ, 2010. - 423 с. Heterogeneous Computation Team, Hybri. LIT
Open. MP materials: 1. THE OPENMP® API SPECIFICATION FOR PARALLEL PROGRAMMING: http: //openmp. org/wp/ 2. Антонов А. С. Технологии параллельного программирования MPI и Open. MP: Учебное пособие для вузов. МГУ им. М. В. Ломоносова; Суперкомпьютерный консорциум университетов России; - М. : Издательство Московского университета, 2012. - 344 с. - (Суперкомпьютерное образование). - ISBN 9785211063433. 3. Alexey Kolosov, Andrey Karpov, Evgeniy Ryzhkov. 32 Open. MP Traps For C++ Developers: http: //www. viva 64. com/en/a/0054/#ID 0 EOAAE Heterogeneous Computation Team, Hybri. LIT