Acoustic Lexical Model Derk Geene Speech recognition p

= P(signal|words) P(words) / P(signal) P(signal|words): Acoustic model p P(words): Language")

 500 sentences of 6 – 10 words each from 5 to")
 p Word recognition errors: n n n Substitution Deletion Insertion Correct:")
 Correct: Recognised: The effect is clear Effect is not clear Error")
 p Modeling is language dependent. fixme p Modeling unit n")
 p Whole-word models n p Phone models n n p")
 p Recognition accuricy can be improved by using context-dependent parameters. p")

 p p Triphone model: phonetic model that takes into consideration both")
 p Stress n n n p Word-level stress n n p")

 Vary much triphones. 503 = 125. 000 p Many phonemes have")





- Slides: 20
Acoustic / Lexical Model Derk Geene
Speech recognition p P(words|signal)= P(signal|words) P(words) / P(signal) P(signal|words): Acoustic model p P(words): Language model p Idea: Maximize P(signal|words) P(words) p Today: Acoustic model p
Variability p Variation n n Speaker Pronunciation Environmental Context Static acoustic model will not work in real applications. p Dynamically adapt P(signal|words) while using the system. p
Measuring errors (1) 500 sentences of 6 – 10 words each from 5 to 10 different speakers. p 10% relative error reduction p p Training set / Development set p First decide optimal parameter settings.
Measuring errors (2) p Word recognition errors: n n n Substitution Deletion Insertion Correct: Did mob mission area of the Copeland ever go to m 4 in nineteen eighty one? Recognized: Did mob mission area ** the copy land ever go to m 4 in nineteen east one?
Measuring errors (3) Correct: Recognised: The effect is clear Effect is not clear Error Rate One by one: 75% p Word error rate=100% x Subs + Dels + Ins #words in correct sentence
Units of speech (1) p Modeling is language dependent. fixme p Modeling unit n n n Accurate Trainable Generalizable
Units of speech (2) p Whole-word models n p Phone models n n p Only suitable for small vocabulary recognition Suitable for large vocabulary recognition Problem: over-generalize less accurate Syllable models
Context dependency (1) p Recognition accuricy can be improved by using context-dependent parameters. p Important in fast / spontanious speech. p Example: the phoneme /ee/
p Peat p Wheel
Context dependency (2) p p Triphone model: phonetic model that takes into consideration both the left and the right neightbouring phones. If two phones have the same identity, but different left or right contexts, there are considered different triphones. Interword context-dependent phones. Place in the word: n n n Beginning Middle End
Context dependency (3) p Stress n n n p Word-level stress n n p Longer duration Higher pitch More intensity Import – Import Italy – Italian Sentence-level stress n n I did have dinner.
p Radio
Context dependency (4) Vary much triphones. 503 = 125. 000 p Many phonemes have the same effects p /b/ & /p/ labial (pronounces by using lips) /r/ & /w/ liquids Clustered acoustic-phonetic units Is the left-context phone a fricative? Is the right-context phone a front vowel? p
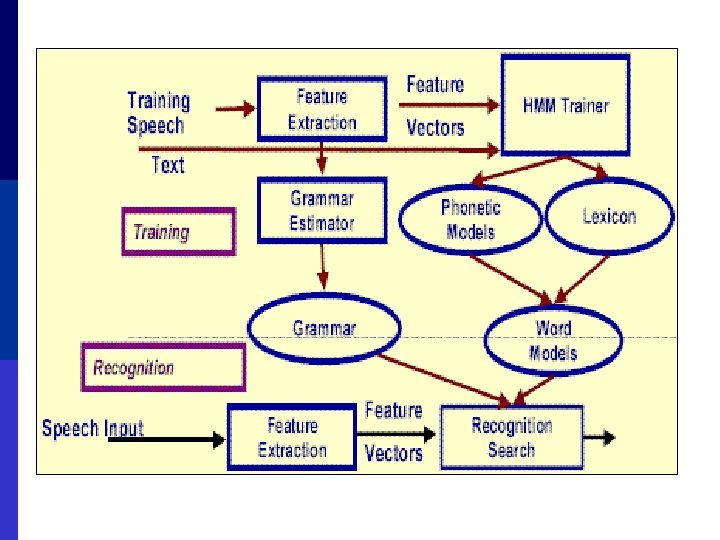
Acoustic model p After feature extraction, we have a sequence of feature vectors, such as the MFCC vector, as input data. Feature stream Segmentation and labeling Phonemes / units Lexical access problem Words
Acoustic model p Signal Phonemes p Problem: phonemes can be pronounced differently n n n Speaker differences Speaker rate Microphone
Acoustic model p Phonemes Words p The three major ways to do this: n n n Vector Quantization Hidden Markov Models Neural Networks
Acoustic model p Problem: Multiple pronunciations: n Dialect variation 0, 5 t ow m 0, 5 n Coarticulation 0, 2 ow t aa 0, 5 ow t ow ey aa m 0, 8 ax t ey
The End