Reinforcement Learning Presented by Montecarlo Firstvisit MC Temporal

Reinforcement Learning Presented by 肖钦哲






Monte-carlo

First-visit MC
")
Temporal Difference/TD(0)
 Ø 当λ=1时,TD(1)就是MC;当λ=0时,也就是TD(0).")
Temporal Difference/TD(λ) Ø 当λ=1时,TD(1)就是MC;当λ=0时,也就是TD(0).

MC vs TD vs DP

MC vs TD vs DP

MC vs TD vs DP

On-policy vs off-policy 在当前状态S选择A的策略与为下一个状态S’选择的策略是否相同,如果相同,为onpolicy, 否则为off-policy。 Ø Off-policy: Q-learning Ø On-policy: Sarsa

Sarsa


参考 Ø UCL Course on RL : PPT: http: //www 0. cs. ucl. ac. uk/staff/D. Silver/web/Teaching. html Video: http: //search. bili. com/all? keyword=%E 5%A 2%9 E%E 5%BC%BA%E 5%AD %A 6%E 4%B 9%A 0%E 8%AF%BE%E 7%A 8%8 BDavid%20 Silver&from_source =banner_search Ø Book: 《reinforcement learning : an introduction》 Ø 其他博客

example Ø 如何从五个房间中走出去 http: //mnemstudio. org/path-finding-q-learning-tutorial. htm

![Steps Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)] Episode](http://slidetodoc.com/presentation_image/21cac2b62c271e50de4d64878bc73359/image-20.jpg "Steps Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)] Episode")
Steps Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)] Episode 1. (1) State=1,actions 3/5,select 5 Q(1, 5) = R(1, 5) + 0. 8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0. 8 * 0 = 100 Episode 2. (1) State=3, actions 1/2/4, select 1 Q(3, 1) = R(3, 1) + 0. 8 * Max[Q(1, 3), Q(1, 5)] = 0 + 0. 8 * Max(0, 100) = 80 (2) State=1, actions 3/5, select 5 Q(1, 5) = R(1, 5) + 0. 8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0. 8 * 0 = 100

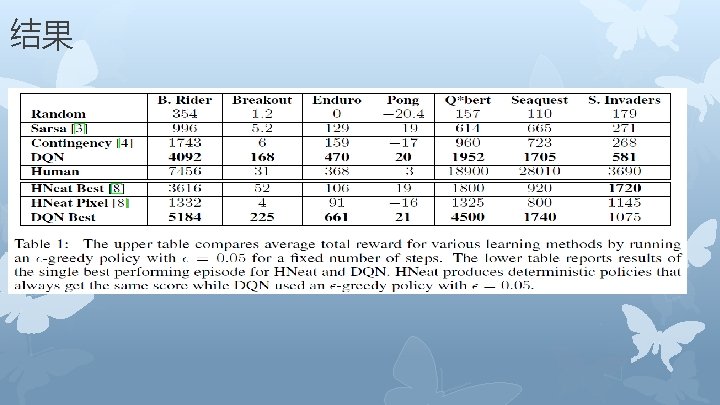
Results …. 归一





DQN

Preprocessing and Model Architecture Ø Preprocessing 1. 210*160 RGB -> gray-scale 110*84 2. Cropping: 84*84 3. Φ(s): 预处理函数,对过去的4帧做上述处理然后堆叠 Ø Architecture 有两种方式: 1. s, a作为输入,输出一个Q值 2. S作为输入, 输出所有action的Q值 第二种只需要计算一次,故使用 2

Experiments Ø Reward: 1, 0, -1 Ø RMSProp batch 32 Ø Ε-greedy 1 ~ 0. 1 linearly, fixed 0. 1 Ø Train: 10 million frames Ø Replay memory: 1 million most recent frames Ø Frame-skipping technique: every kth frame select actions. k=4/3

Training Ø Evaluation of progress of agent 1. 很多次游戏的平均回报; 2. 固定的状态集合,使用平均Q值评估; 1的方式会很抖动,small changes to the weights of a policy can lead to large changes in the distribution of states the policy visits.


- Slides: 32