Reinforcement Learning and Understanding Alpha Go Ms Hadar


 – Model parameters – Solution")


 •")
 1 1 2 3 4")
 1 1 2 3 • S = squares • A =")
 • 1 2 3 4 1 0 0 0 +1 2")
 • 1 2 3 4 1 -0. 02 +1 2 -0.")
 1 • Transition Psa - ? 1 2 3 4")














:")











- Slides: 38
Reinforcement Learning and Understanding Alpha. Go Ms. Hadar Gorodissky Mr. Niv Haim
• Check that there are board markers! • Write topics on the board
Lecture I Flow • MDP (review of Ng lecture) – Model parameters – Solution concepts – Value iteration – Policy iteration – Q-Learning • RL in Neural Networks – Approximating functions: policy, V, Q – How to train policy network – How to train value network
Motivation • • • Classic: Inverted pendulum Helicopter control Alpha. Go Playing Attari Space. X landing (Modern inverted pendulum) https: //www. youtube. com/watch? v=RPGUQy. SBik. Q
MDP • Stands for: Markov Decision Process
MDP (Simple example) •
MDP (Robot example) 1 1 2 3 4
MDP (Robot example) 1 1 2 3 • S = squares • A = {N, S, W, E} 2 3 4
MDP (Robot example) • 1 2 3 4 1 0 0 0 +1 2 0 0 -1 3 0 0
MDP (Robot example) • 1 2 3 4 1 -0. 02 +1 2 -0. 02 -1 3 -0. 02
MDP (Robot example) 1 • Transition Psa - ? 1 2 3 4
MDP - Dynamics • 1 1 2 3 4
MDP - Dynamics •
MDP - Solution concepts • 1 2 3 4 1 +1 2 -1 3
MDP – Value function •
MDP - Value function • Bellman’s equation:
MDP - Value function • 1 2 3 4 1 1 2 3 4 2 5 6 7 3 8 9 10 11 1 2 3 4 1 +1 2 -1 3
MDP - Solution concepts • Optimal value function Bellman: • Optimal policy
MDP – Solution concepts • Optimal policy for robot 1 2 3 4 1 +1 2 -1 3
MDP – Solving • Value iteration • Policy iteration • Q-Learning
MDP – Solving • Value iteration
MDP – Solving • Policy iteration
MDP – Q-Learning • Value iteration • Policy iteration Both assumed domain knowledge: Accurately knowing P and R (not model-free) • Q-Learning – model-free
MDP – Using Experience • Infer P and R: • R – average reward observed in state s
MDP – Q-Learning •
MDP – Q-Learning Importance of storing values for state-action (vs. just state values):
Q-Learning – Choosing actions
RL – classic summary https: //www. youtube. com/watch? v=Xiig. TGKZfk s
RL in DNN •
Policy network example
How to train a Value Network •
How to train a Value Network • White wins! 14 states
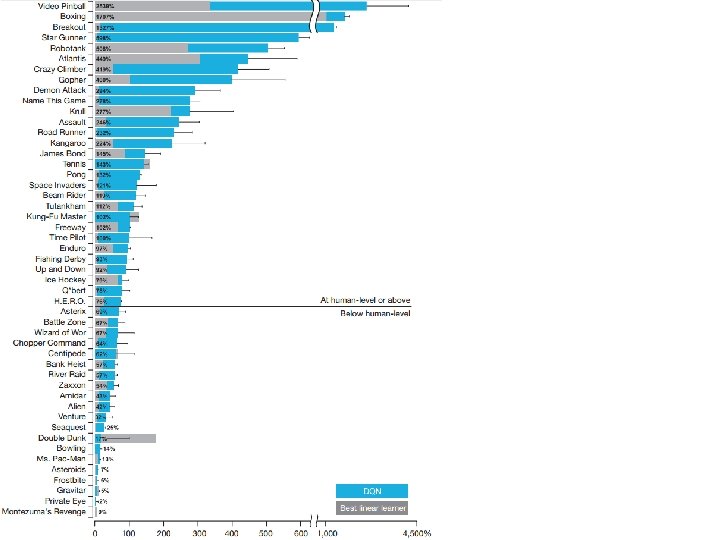
DQN - Playing Atari • Human-level control through deep reinforcement learning (Mnih et al. 2015)
DQN - Playing Atari • Action-value: • Loss function: • Gradient:
DQN - Playing Atari
DQN - Playing Atari
References • CS 229 Lecture notes - Andrew Ng • Reinforcement Learning: A Tutorial - Harmon • Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning - Williams • Human-level control through deep reinforcement learning - Mnih et al. • http: //www. iclr. cc/lib/exe/fetch. php? media=iclr 2015: silvericlr 2015. pdf • http: //uhaweb. hartford. edu/compsci/ccli/projects/QLearning. pdf • http: //www 2. econ. iastate. edu/tesfatsi/RLUsers. Guide. ICAC 2005. pdf • https: //webdocs. ualberta. ca/~sutton/book/ebook/thebook. html - Sutton RL book