Information Retrieval Methods for Social Media 600 466



 – More than 100")







 • Property of")

 – Rich become")

 • RSS/Atom feeds (blogs) • API driven (Twitter,")
. get. Instance(twitter. ID, twitter. Password); List<Status> statuses =")

")
")


 pairs and")
 •")


 • Page. Rank update with dampening parameter α where")
 { r_old = k. rank;")




 Compute() { r_old = r; r = 0; for")





- Slides: 39
Information Retrieval Methods for Social Media 600. 466
Social Media?
Properties of Social Media : Scale • Twitter (Chirp 2010) – More than 100 M user accounts – more than 600 M search queries a day – 55 M tweets a day • Facebook – More than 400 M active users – More than 25 billion pieces of content (web links, news stories, blog posts, notes, photo albums, etc. ) shared each month.
Properties of Social Media: Immediacy • Need to share breaking news • Search : Content vs. Peer recommendation
Properties of Social Media: Duplication • Duplication of content – Blogs: Copy-Paste – Twitter: “Re-tweet” – Groups: Cross-posting – Email: Signature lines, Inline Replies
Properties of Social Media: Semi-structuredness • Informal but structured – Informal != low quality (eg. Wikipedia) • Structure – Metadata – Connectivity
Suggested Reading “Towards a People. Web”, Raghu Ramakrishnan & Andrew Tomkins, IEEE Computer, Aug 2007 “Important properties of users and objects will move from being tied to individual Web sites to being globally available. The conjunction of a global object model with portable user context will lead to a richer content structure and introduce significant shifts in online communities and information discovery. ”
Properties of Social Media • • • Scale Immediacy Heterogeneity Duplication Semi-structuredness
Properties of Social Media Graphs • Small-world property – Six-degrees of separation – Facebook : 5. 73 (Bunyan, 2009) – MS Messenger: ~7 (Leskovec & Horvitz, 2007) • Mathematically – Low Average Path length – High Clustering coefficient
Network Evolution and Path Size
Properties of Social Media Graphs • Power law degree distribution (asymptotically) • Property of most real world networks • Existence of “hubs” • Scale free networks
Probabilistic Modeling of Networks • Erdos-Renyi Model – Choose a pair of nodes uniformly at random and add an edge. – G(n, p) – Not Scale Free (small avg. Path but low clustering coefficient) – Scale Free networks don’t evolve by chance
Probabilistic Modeling of Networks • Preferential Attachment (Barabasi and Albert, 99) – Rich become richer – Stochastic process: Using Polya’s urn
Why model? • Study network evolution, degeneration – Develop algorithms • • Detect communities Who are the movers and shakers? Detect diffusion of ideas across networks Detect anomalies
Crawling Social Networks • HTML (Slashdot) • RSS/Atom feeds (blogs) • API driven (Twitter, Facebook, …) – Data liberation
Twitter twitter = new Twitter. Factory(). get. Instance(twitter. ID, twitter. Password); List<Status> statuses = twitter. get. Friends. Timeline(); System. out. println("Showing friends timeline. "); for (Status status : statuses) { System. out. println(status. get. User(). get. Name() + ": " + status. get. Text()); } http: //twitter 4 j. org
Storage and Indexing • Graph stores can be more efficiently designed traditional RDBMS or flat files (document IR) • A family of “triple stores” or graph databases (#No. SQL movement) – Neo 4 J – Couch. DB – Hypertable –…
Data is becoming more and more connected (Eifrem, OSCON 2009)
Social Media Graphs (Eifrem, OSCON 2009)
Social Media Graphs : Representation • • • Nodes Relationship between nodes Properties on Both Storing in Flat Files vs. Graph Databases Neo 4 J, disk based solution – works well for sizes up to a few billion (Single JVM)
Processing Large Scale Graph Data • Better representation • Parallel computation – Map. Reduce – BSP
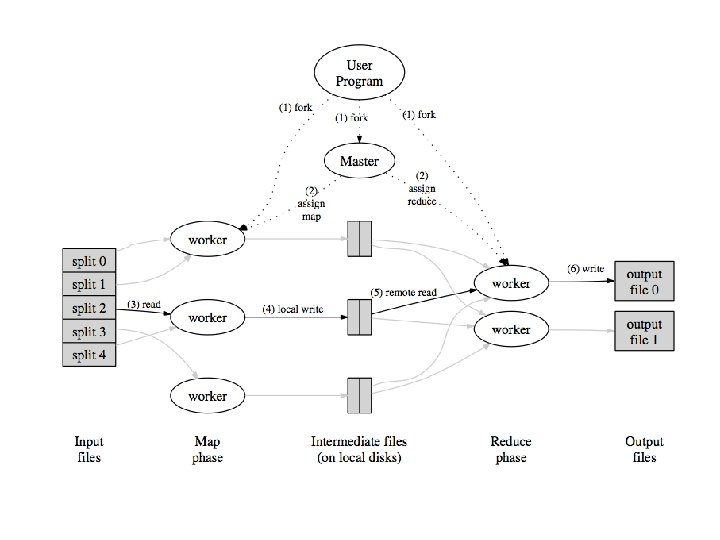
Parallelism via Map-Reduce • A paradigm to view input as (key, value) pairs and algorithms process these pairs in one of two stages – Map: Perform operations on individual pairs – Reduce: Combine all pairs with the same key – Functional programming origins – Abstracts away system specific issues – Manipulate large quantities of data
Parallelism via Map-Reduce • Input is a sequence of key value pairs (records) • Processing of any record is independent of the others • Need to recast algorithms and sometimes data to fit to this model – Think of structured data (Graphs!)
Example: Building inverted indexes Input: Collection of documents Output: For each word find all documents with the word def mapper(filename, content): foreach word in content. split(): output(word, filename) def reducer(key, values): output(key, unique(values))
Map-Reducing graph data • Note: By design the mappers cannot communicate with each other. • The graph representation should be such that all information (e. g. neighborhood) needed for processing a node should be locally available. • The adjacency list representation is perfectly suited. • Key: vertex in the graph • Value: neighbors of the vertex and their associated values
Computing Page. Rank (Map. Reduce) • Page. Rank update with dampening parameter α where P is the transition probability matrix. • One map-reduce per iteration
Map. Reduce: Page. Rank Iteration Map(Key k, Value v) { r_old = k. rank; r = 0; foreach node n in v. get. Neighbors() { r += p(n, k)*r_old + dampening_factor } v. rank = r; Emit(k, v); }
Processing Large Scale Graph Data • Map. Reduce is not the best model for large scale graph processing – Simple graph concepts (Pagerank, BFS, …) are not easy to program – Map. Reduce does not preserve data locality in consecutive operations
A New Paradigm to Process Large Scale Graph Data • Bulk Synchronous Parallel • Developed in the 80 s by Leslie Valiant • Introduced by Google for Graph computation “Pregel: a system for large-scale graph processing” (Malewicz et al, PODC 2009)
Bulk Synchronous Parallel • Sequence of steps – “Super. Steps” • Each Super. Step S – Execute a user defined Compute() function on every vertex in parallel – Input to Compute(): All messages from Super. Step S– 1 – Output of Compute(): Messages to other vertices 1 B vertices 80 B Edges 2000 Workers Bellman-Ford: 200 s (Malewicz et al, PODC 2009)
Why “Super. Step”? • Internally consists of three stages
Computing Page. Rank (BSP version) Compute() { r_old = r; r = 0; for each incoming message m { r += m. p* r_old + dampening_factor; } if(r – r_old < epsilon) done() }
Suggested Reading • “Truly, Madly, Deeply Parallel”, Robert Matthews, New Scientist, Feb 1996 • “Pregel: a system for large-scale graph processing” (Malewicz et al, PODC 2009)
Social Network Analysis • • Retrieving information from structure Example: Community Discovery Many practical applications One approach: “Edge Betweenness” – betweenness(e) = # triangles(e)/max(e) – iteratively prune edges with low betweenness
Book Networks, Crowds, and Markets: Reasoning About a Highly Connected World By David Easley and Jon Kleinberg http: //www. cs. cornell. edu/home/kleinber/networks-book/
Recap … • Properties of social media – – – Scale Immediacy Heterogeneity Duplication Semi-structuredness • Properties of social media graphs – Small-worldness – Scale free property – Evolution models • Crawling – API driven • Indexing & Retrieval – Graph databases • Processing large scale social networks – Map. Reduce – Bulk Synchronous Parallel • IR from structure – Social Network Analysis
Social Media Related Projects • Twitter