IFT 3355 Infographie Pipeline graphique Victor Ostromoukhov Dp







 Mémoire")

 images (textures, masques) Traitement géométrie")
 begin. X( ); vertex (x, y, z); … end.")







; …; end. Display. List;")
 • Similaire aux vertex arrays, on peut stocker – les")

 •")






 • Calcul par pixel – Position 2 D, profondeur, couleur, coordonnées de")

 • Color map – Index (1 byte) dans une table")
 • True color, RGBA mode – 24 bits est satisfaisant")
 • Projection")







 •")


")


 32 cores x 16 single-precision float SIMD per core x 2 FLOPS")
- Slides: 50
IFT 3355: Infographie Pipeline graphique © Victor Ostromoukhov Dép. I. R. O. Université de Montréal
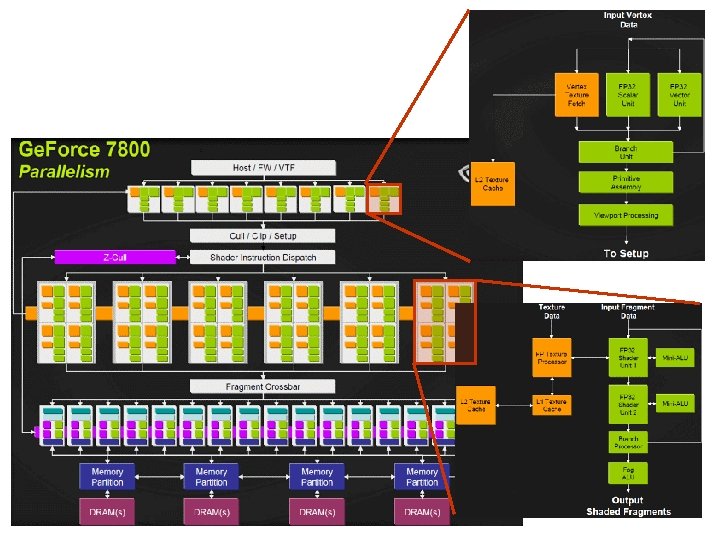
Hardware Graphique • Graphisme est passé des stations spécialisées coûteuses à tout ordinateur de base • L’industrie du jeu vidéo pousse pour des améliorations constantes des cartes graphiques • Performance du GPU double à chaque 12 mois • Les nouvelles cartes programmables sont même utilisables comme co-processeur mathématique…
State-of-the-Art Rendering 2001 Real-Time
n. VIDIA
Cry. Engine 2 Synthétique Réel
Système d’affichage CPU Périphériques bus (e. g. PCI/AGP/PCI-express) Mémoire
Système d’affichage CPU dans les deux sens CPU: GPU v 1: 16 lignes à 250 MB/sec v 2: 32 lignes à 500 MB/sec Périphériques bus (e. g. PCI/AGP/PCI-express) Mémoire Frame buffer Contrôleur vidéo Moniteur libère l’accès au bus avec un bus vidéo Dans une configuration double buffer, un multiplexeur alterne entre les deux frame buffers CPU fait tout le travail, mais il a toute la flexibilité
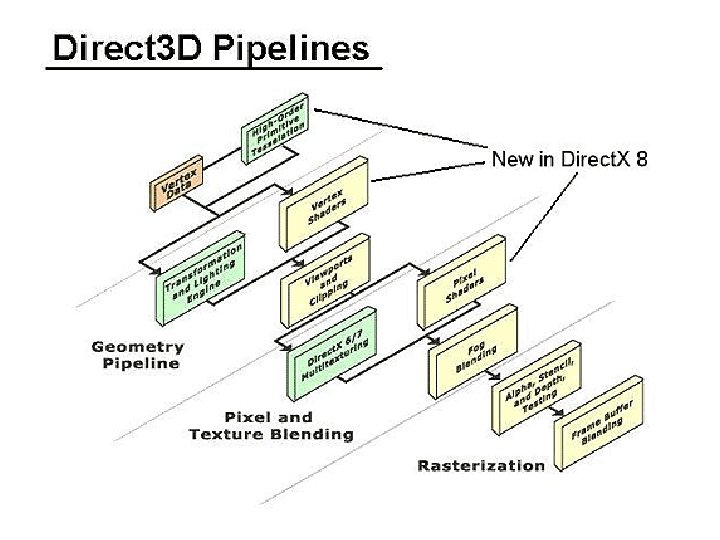
Pipeline de base Programme usager primitives (points, lignes, polygones) images (textures, masques) Traitement géométrie traitement par sommet 3 D à 2 D pixels à l’écran Traitement pixel rasterization couleur sortie au frame buffer
APIs (Open. GL, Direct. X) begin. X( ); vertex (x, y, z); … end. X( ); déclare et active l’état X attributs d’état: couleur, normale, uv, données par sommet inactive l’état X paramètres d’état: • lumières, géométries, textures, options de rendu, etc. • tout changement d’état réduit la performance • immediate mode (tout passe par le CPU) • optimisation d’états, stocké sur carte graphique
Améliorer la vitesse de rendu • Parallélisme – calcul de matrices, triangles, textures, etc. – complexité (logique et silicon) et coût • Pipeline – n étapes devrait être n fois plus rapide – chaque étape peut aussi être un pipeline elle-même, mais elle pourrait aussi être traitée en parallèle pour des besoins accrus en performance – vitesse du pipeline est déterminée par son étape la plus lente (bottleneck) – il est important de réduire le nombre de sommets transmis (triangle strips, triangle fans, quadrilatères…)
Triangle Strips v 1 T 3 T 1 v 0 v 5 v 3 T 0 T 4 T 2 v 2 T 0: v 0 v 1 v 2 T 1: v 1 v 2 v 3 T 2: v 2 v 3 v 4 T 3: v 3 v 4 v 5 T 4: v 4 v 5 v 6 T 5: v 5 v 6 v 7 T 5 v 4 v 6 v 7
Generalized Triangle Strips v 1 T 1 v 0 T 0 v 4 v 3 T 2 T 4 T 3 v 2 v 6 v 5 T 0: v 0 v 1 v 2 T 1: v 1 v 2 v 3 Swap v 3 v 2 (triangle dégénéré) T 2: v 3 v 2 v 4 T 3: v 2 v 4 v 5 peut même créer des T 4: v 4 v 5 v 6 strips déconnectés
Triangle Fans v 5 v 6 T 4 v 0 v 1 T 0 T 2 T 1 v 2 T 0: v 0 v 1 v 2 T 1: v 0 v 2 v 3 T 2: v 0 v 3 v 4 T 3: v 0 v 4 v 5 T 4: v 0 v 5 v 6 v 4 T 3 v 3
Triangle Strips et Triangle Fans • Plus difficile de trouver des fans que des strips • Nombre de sommets envoyés au pipeling pour m triangles • Ex: m=10, tris=1. 2; m=5, tris=1. 4
Créer des strips: STRIPE Algorithm • Si on permet plus que des triangles, on peut trianguler un polygone de différentes façons • Patchification v 0 v 1, v 18 v 19 v 2 v 3, v 16 v 17 v 4 v 5, v 14 v 15 v 6 v 7, v 12 v 13 v 8 v 9, v 10 v 11 A chaque tournant, 3 swaps ou 2 sommets en extra
Vertex arrays • Passe au GPU un vecteur de sommets et un vecteur d’indices reliant ces sommets en triangles • On peut aussi encoder le vecteur d’indices en un strip • Si la géométrie n’est pas modifiée entre deux appels au vecteur, on peut la stocker directement en mémoire du GPU
Display Lists • display. ID = create. Display. List( ); …; end. Display. List; … draw. Display. List (display. ID); • Conserve simultanément – les données sur les triangles directement sur le GPU – les commandes graphiques (état, texture, etc. ) • Peut imbriquer des display lists dans des display lists + Optimise (compile) les commandes graphiques pour le hardware graphique - Ne permet pas de modifier n’importe quelle donnée sans briser (et donc recompiler) la display list - Limitations en nombre et en taille
Vertex Buffer Objects (VBO) • Similaire aux vertex arrays, on peut stocker – les données sur les triangles directement sur le GPU – les commandes graphiques par sommet (état, texture, etc. ) + Permet de modifier des sections des vecteurs (indices et contenu) - Commandes ne sont pas optimisées (compilées)
Pipeline graphique standard • Parcours et traitement de la scène – primitives, couleurs, transformations, textures – Détection/réaction aux collisions, morphing, frustum culling hiérarchique • Immediate mode – Flexible mais exigeant pour le CPU • Retained mode – Structure de forme display list – Optimisations dans l’organisation des données (compilateur) – CPU ne peut modifier que certaines parties données Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Espace objet à espace monde (ou pyramide de vue) • Sommet transformé par une matrice combinée • Normale transformée en fonction du shading (constant/flat ou Gouraud/Phong) Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Test avec le volume de vue • Si l’objet est à l’extérieur, ce test réduit le travail dans les étapes suivantes Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Si le shading est constant, il n’y a qu’une couleur par polygone et lumière • Pour le shading de Gouraud, une couleur par sommet • Pour le shading de Phong, il y aura plus de travail à faire lors de l’étape de rasterization Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Espace monde à espace normalisé de projection • Une partie des transformations peut être faite lors de l’étape de modeling transformation Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Un triangle peut alors résulter en plus de trois sommets • Primitives plus complexes peuvent être traitées par scissoring (ne dessine que si nonrejet trivial: rasterization devient moins efficace) • On s’attend à un maximum de 10% des primitives à découper, sinon pénalité Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Après une transformation de perspective, w est en général différent de 1 • Changement d’échelle et translation pour le viewport Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Pipeline graphique standard • Scanconversion • Détermination de visibilité – Zbuffer • Shading (transparence et texture) Display traversal Modeling transformation Trivial accept/reject Lighting Viewing transformation Clipping Dividing by w Mapping to viewport Rasterization
Rasterization (scanconversion) • Calcul par pixel – Position 2 D, profondeur, couleur, coordonnées de texture – Visibilité • Double buffer – Rendu dans back buffer et swap en front buffer (affiché) • Transparence – Rendu des objets opaques – Rendu des objets transparents dans l’ordre derrière-àdevant
Buffers • • • Color buffer Zbuffer Single et double buffering Stéréo Stencil et accumulation
Color Buffer (Frame Buffer) • Color map – Index (1 byte) dans une table de couleurs • High color – 2 bytes: 32, 768 to 65, 536 colors • True color, RGBA mode – 3 -4 bytes: 16, 777, 216 colors – 32 bits est souvent optimisé pour le traitement des commandes en hardware
Color Buffer (Frame Buffer) • True color, RGBA mode – 24 bits est satisfaisant pour afficher les couleurs – Accumulation en rendu multi-passes produit de la discrétisation (quantisation) des couleurs résultant en des zones uniformes (banding) – SGI permet de calculer les couleurs en 12+ bits par canal, mais affiche avec 8 bits par canal • Overlay plane – 1 -8 bits, devant le buffer couleur pour menus, cursors, interfaces, highlighting, etc. – Affiche sans affecter le buffer couleur
Zbuffer • 16 -32 bits (récemment jusqu’à 96 bits en floating point) • Projection orthographique – Distance entre les séparateurs (zones) est la même • Projection perspective – Distance est plus petite près de la caméra que loin de la caméra – Essayer de borner d’aussi près que possible la scène entre l’avant-plan et l’arrière-plan
Buffering • Single buffer – Dessine les polygones, clear, dessine les polygons, … – Synchroniser le clear avec le vertical retrace du moniteur (Amiga) • Double buffer – Image précédente est affichée dans le front buffer pendant que dessine dans le back buffer – Swap buffers (adresse ou Bit. BLT) durant le vertical retrace
Stéréo • Rendu d’une image pour l’oeil gauche et une autre image pour l’oeil droit – Lunettes rouge-vert (images en niveau de gris, possible même en single buffer) – Head-mounted displays (casques) – Shutter glasses (bloque un oeil en synchronisation avec l’affichage de l’image)
Stencil et Accumulation Buffers • Même résolution en pixels que le frame buffer • Stencil – 1 -8 bits pour des opérations de masque – Volumes d’ombre de Crow (complexité de profondeurs de 256 valeurs) • Accumulation – Deux fois (typiquement) la résolution de profondeur – Couleurs de chaque image sont combinées avec un opérateur – Profondeur de champ, flou de mouvement, antialiassage, ombres douces, etc.
Rendu en multi-passes • Une passe: calcule les couleurs et affiche l’image • Multi-passes: plusieurs itérations des opérations (calcule les couleurs et modifie les couleurs précédentes), ensuite affiche l’image • Ex: diffus et texture, spéculaire selon texture
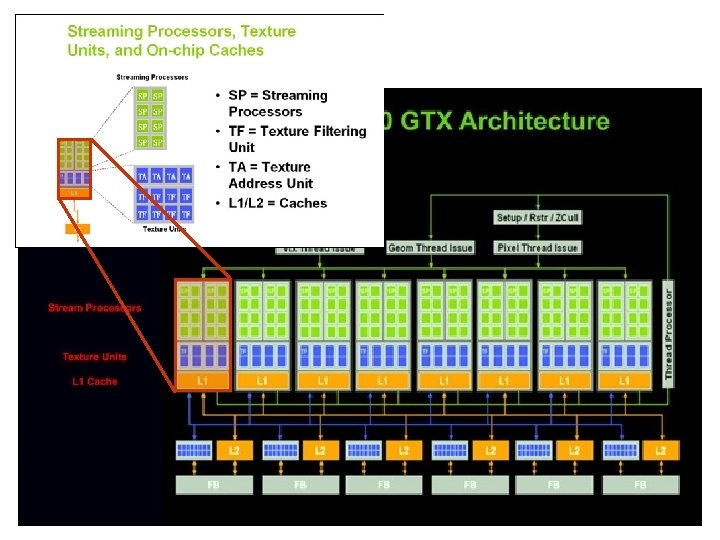
Quelques percées Mémoire sur carte – Store géométrie – Store textures 1998: multi-textures 1999: transformation et illumination 2001: shader programmable 2002: shader pixel 2003: langage de programmation high-level 2004: conditions dans les shaders 2006: floating point 2007: shader géométrique 2008: Larrabee (a multi-core architecture)
Direct 3 D 10 Features Input Assembler Vertex Buffer Index Buffer Vertex Shader Texture Geometry Shader Texture Stream Output Rasterizer/ Interpolator Pixel Shader Output Merger Texture Depth/Stencil Render Target
Unified shader architecture to redistribute shader loads
Cg de n. VIDIA • (vs. HLSL pour Microsoft, GLSL pour Open. GL) • Langage similaire à C • Un programme Cg est compilé en – Direct. X 8, 9, 10 – Open. GL arb, nvidia • Utilisé pour les vertex et fragment shaders • Particularités du langage – Opérateurs acceptent/retournent des scalaires et vecteurs – Swizzling de. xyzw et. rgba • v 3 = s. xxy; // v 3. x = s. x; v 3. y = s. x ; v 3. z = s. y • v 3. xw = s; // assignation seulement aux composantes xw – Fonctions spéciales (abs, dot, log 2, reflect, rsqrt, …) – Aucun: pointeurs, opérations sur bits, unions, aucun C++ avancé, …
Vertex Shader • Programmes pour modifier – Forme: movements, motion blur, blend, morph, déformations, skinning, volumes d’ombre, etc. – Couleur/texture: réflexion, bump map, textures projetées • Un sommet : vertex shader : un sommet – On doit alors transformer et illuminer le sommet nousmêmes – Ne permet pas de créer de nouveaux sommets (avant la venue du geometry shader) – Impossible de modifier d’autres sommets
Vertex Shader • Un programme plus long ralentit le pipeline • SIMD: chaque instruction sur un vecteur (r. x, r. y, r. z, r. w) est traitée en parallèle • Ge. Force 3+4 and Radeon 8500/9700: – 128/256 instructions par vertex shader
Exemples de Pixel Shaders • Réflexion par pixel • Illumination par pixel (Phong, BRDF) • Textures procédurales
GPGPU - General Purpose GPU • Les premiers environnements de GPGPU – Les tableaux deviennent des textures, le calcul devient une opération de rendu; il faut connaître le graphique – Le pixel shader est souvent préféré pour effectuer autant d’opérations en parallèle • GPGPU langages: – CUDA (n. VIDIA), CAL (AMD), Rapid. Mind platform, Brook project, Microsoft Accelerator • GPU est utilisé comme un stream processor • Pas tous les problèmes s’implémentent efficacement sur GPU – calcul en précision float, pas encore en double – accès mémoire sont limités
GPGPU - Exemples d’applications • Ray tracing, radiosity, photon mapping • Simulations physiques dans les jeux (havok) • Simulations selon les équations de Navier-Stokes, Smoothed-particle hydrodynamics, Lattice Boltzmann, équations d’Euler (fluides, nuages, etc. ) • Librairies de FFT et transformées en ondelettes • Alignements de protéines • Chimie quantique • etc.
Larrabee (Intel) 32 cores x 16 single-precision float SIMD per core x 2 FLOPS x 2 GHz per core = 2 TFLOPS