http www yolinux comTUTORIALSLinux Tut orial Posix Threads











![Як вводяться директиви? n Фортран q q n !$OMP PARALLEL [clause. . . ]](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-13.jpg "Як вводяться директиви? n Фортран q q n !$OMP PARALLEL [clause. . . ]")


![Приклад виконання [saa@cluster omp]$ icc -openmp for. cpp(7) : (col. 1) remark: Open. MP](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-16.jpg "Приклад виконання [saa@cluster omp]$ icc -openmp for. cpp(7) : (col. 1) remark: Open. MP")

![Приклад виконання [saa@cluster omp]$ icc -openmp section. cpp [saa@cluster omp]$ OMP_NUM_THREADS=4. /a. out 05](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-18.jpg "Приклад виконання [saa@cluster omp]$ icc -openmp section. cpp [saa@cluster omp]$ OMP_NUM_THREADS=4. /a. out 05")


{ #pragma omp")
![Приклад виконання критичного поділу n Без critical [saa@cluster omp]$ OMP_NUM_THREADS=10. /a. out 0756893241 n](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-22.jpg "Приклад виконання критичного поділу n Без critical [saa@cluster omp]$ OMP_NUM_THREADS=10. /a. out 0756893241 n")

![Приклад особливих та загальних даних #include <stdio. h> int alpha[10], beta[10], i; #pragma omp](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-24.jpg "Приклад особливих та загальних даних #include <stdio. h> int alpha[10], beta[10], i; #pragma omp")
![Приклад виконання [saa@cluster omp]$ icc -openmp. /threadprivate. c(9) : (col. 1) remark: Open. MP](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-25.jpg "Приклад виконання [saa@cluster omp]$ icc -openmp. /threadprivate. c(9) : (col. 1) remark: Open. MP")


![Результат виконання [saa@cluster omp]$ icc -openmp. /reduce. cpp(7) : (col. 1) remark: Open. MP](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-28.jpg "Результат виконання [saa@cluster omp]$ icc -openmp. /reduce. cpp(7) : (col. 1) remark: Open. MP")










![Приклад розщеплення #include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-39.jpg "Приклад розщеплення #include \"mpi. h\" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int")
![Компіляція і виконання [saa@cluster mpi]$ mpicc. /comm_split. c -o comm_split [saa@cluster mpi]$ mpirun -np](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-40.jpg "Компіляція і виконання [saa@cluster mpi]$ mpicc. /comm_split. c -o comm_split [saa@cluster mpi]$ mpirun -np")




![Приклад роботи з групами #include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub.](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-45.jpg "Приклад роботи з групами #include \"mpi. h\" int main(int argc, char* argv[]){ MPI_Comm sub.")
![Компіляція та виконання [saa@cluster mpi]$ mpicc. /comm_group. c -o comm_group [saa@cluster mpi]$ mpirun -np](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-46.jpg "Компіляція та виконання [saa@cluster mpi]$ mpicc. /comm_group. c -o comm_group [saa@cluster mpi]$ mpirun -np")
![Отримання ім’я машини, де працює процес char nm[4096]; int name_size = 4096; MPI_Get_processor_name(nm, &nm_size);](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-47.jpg "Отримання ім’я машини, де працює процес char nm[4096]; int name_size = 4096; MPI_Get_processor_name(nm, &nm_size);")




![#include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int size, rank,](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-52.jpg "#include \"mpi. h\" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int size, rank,")
![Приклад виконання [saa@cluster mpi]$ mpirun -np 10 -wd /net/s 1/$PWD. /reduce result. Vector[0]=4500 result.](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-53.jpg "Приклад виконання [saa@cluster mpi]$ mpirun -np 10 -wd /net/s 1/$PWD. /reduce result. Vector[0]=4500 result.")




' */ typedef struct")
 Упакування– запис різнотипних структур даних в один масив int MPI_Pack(void *buf,")

![Приклад упакування-розпакування #define msg. Tag 10 struct { int i; float f[4]; char c[8];](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-61.jpg "Приклад упакування-розпакування #define msg. Tag 10 struct { int i; float f[4]; char c[8];")


 q n Статус може")
![Приклад асинхронної операції MPI_Request reqs[4]; MPI_Status stats[4]; MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag 1, MPI_COMM_WORLD,](https://slidetodoc.com/presentation_image_h/2ba4c247a3583944461c2329e40fcebb/image-65.jpg "Приклад асинхронної операції MPI_Request reqs[4]; MPI_Status stats[4]; MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag 1, MPI_COMM_WORLD,")


- Slides: 67
Література Навчальний посібник по багатопотоковому програмуванню http: //www. yolinux. com/TUTORIALS/Linux. Tut orial. Posix. Threads. html n Навчальний посібник по Open. MP http: //www. llnl. gov/computing/tutorials/open. MP/ n
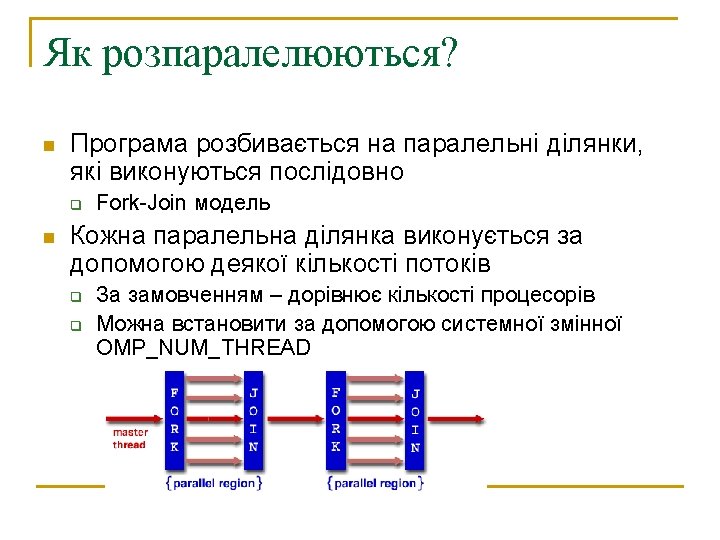
Як вводяться директиви? n Фортран q q n !$OMP PARALLEL [clause. . . ] IF (scalar_logical_expression) PRIVATE (list) SHARED (list) DEFAULT (PRIVATE | SHARED | NONE) FIRSTPRIVATE (list) REDUCTION (operator: list) COPYIN (list) block !$OMP END PARALLEL C/C++ q #pragma omp parallel [clause. . . ] newline if (scalar_expression) private (list) shared (list) default (shared | none) firstprivate (list) reduction (operator: list) copyin (list) structured_block
Розпаралелення циклів for n #pragma omp parallel for #include <iostream> #include <cmath> using namespace std; int main (void){ #pragma omp parallel for (int i =0; i<10; i++) cout << i<<endl<<flush; return 0; }
Приклад виконання [saa@cluster omp]$ icc -openmp for. cpp(7) : (col. 1) remark: Open. MP DEFINED LOOP WAS PARALLELIZED. [saa@cluster omp]$. /a. out 05 1 2 3 4 6 7 8 9 [saa@cluster omp]$
Ділянки паралельного виконання n n #pragma omp parallel sections #pragma omp section q Кожна секція буде виконуватись в своєму потоці #include <iostream> #include <cmath> using namespace std; int main (void){ #pragma omp parallel sections { #pragma omp section for (int i =0; i<5; i++) cout << i<<endl<<flush; #pragma omp section for (int i =5; i<10; i++) cout << i<<endl<<flush; } return 0; }
Приклад виконання [saa@cluster omp]$ icc -openmp section. cpp [saa@cluster omp]$ OMP_NUM_THREADS=4. /a. out 05 1 2 3 4 6 7 8 9
Приклад critical #include <iostream> #include <cmath> using namespace std; int main (void){ #pragma omp parallel for (int i =0; i<10; i++){ #pragma omp critical cout << i<<endl<<flush; } return 0; }
Приклад виконання критичного поділу n Без critical [saa@cluster omp]$ OMP_NUM_THREADS=10. /a. out 0756893241 n З вказуванням critical [saa@cluster omp]$ icc -openmp. /single. cpp(7) : (col. 1) remark: Open. MP DEFINED LOOP WAS PARALLELIZED. [saa@cluster omp]$ OMP_NUM_THREADS=10. /a. out 0 5 2 7 9 3 6 1 4 8
Приклад особливих та загальних даних #include <stdio. h> int alpha[10], beta[10], i; #pragma omp threadprivate(alpha) main () { /* First parallel region */ #pragma omp parallel private(i, beta) for (i=0; i < 10; i++) alpha[i] = beta[i] = i; /* Second parallel region */ #pragma omp parallel printf("alpha[3]= %d and beta[3]= %dn", alpha[3], beta[3]); }
Приклад виконання [saa@cluster omp]$ icc -openmp. /threadprivate. c(9) : (col. 1) remark: Open. MP DEFINED REGION WAS PARALLELIZED. . /threadprivate. c(14) : (col. 1) remark: Open. MP DEFINED REGION WAS PARALLELIZED. [saa@cluster omp]$ OMP_NUM_THREADS=2. /a. out alpha[3]= 3 and beta[3]= 0 Beta[] – дані загубились Alpha[] – дані не загубились
Приклад редукції #include <iostream> #include <cmath> using namespace std; int k=0, l=0; int main (void){ #pragma omp parallel for shared(l) reduction(+: k) for (int i =0; i<100000; i++){ k++; l++; } cout << "k="<<k<<endl<<flush; cout << "l="<<l<<endl<<flush; return 0; }
Результат виконання [saa@cluster omp]$ icc -openmp. /reduce. cpp(7) : (col. 1) remark: Open. MP DEFINED LOOP WAS PARALLELIZED. [saa@cluster omp]$ OMP_NUM_THREADS=10. /a. out k=100000 l=60000 L потеряно
Приклад розщеплення #include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int size, rank, subsize; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); //розбиваємо набір процесів на 3 групи //нумерація процесів в кожній групі 0 -2 MPI_Comm_split(MPI_COMM_WORLD, rank/3, rank%3, &sub. Comm); MPI_Comm_rank( sub. Comm, &subrank ); MPI_Comm_size( sub. Comm, &subsize ); printf("old size = %d new size %d ", size, subsize); printf("old rank = %d new rank %dn", rank, subrank); MPI_Comm_free(&sub. Comm); MPI_Finalize(); return 0; }
Компіляція і виконання [saa@cluster mpi]$ mpicc. /comm_split. c -o comm_split [saa@cluster mpi]$ mpirun -np 10 -wd /net/s 1/$PWD. /comm_split old size = 10 new size 1 old rank = 9 new rank 0 old size = 10 new size 3 old rank = 8 new rank 2 old size = 10 new size 3 old rank = 6 new rank 0 old size = 10 new size 3 old rank = 7 new rank 1 old size = 10 new size 3 old rank = 0 new rank 0 old size = 10 new size 3 old rank = 1 new rank 1 old size = 10 new size 3 old rank = 2 new rank 2 old size = 10 new size 3 old rank = 4 new rank 1 old size = 10 new size 3 old rank = 5 new rank 2 old size = 10 new size 3 old rank = 3 new rank 0
Створення нового коммунікатора на базі групи MPI_Comm sub. Comm; MPI_Group subgroup; MPI_Comm_create(MPI_COMM_WORLD, subgroup, &sub. Comm);
Приклад роботи з групами #include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int size, rank, subsize, i; int ranks[5]; MPI_Group group, subgroup; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_group(MPI_COMM_WORLD, &group); for(i = 0; i<5; i++) ranks[i]=i; MPI_Group_excl(group, 5, ranks, &subgroup); MPI_Comm_create(MPI_COMM_WORLD, subgroup, &sub. Comm); if( sub. Comm == MPI_COMM_NULL) { printf ("%d not in communicatorn", rank); } else { MPI_Comm_rank( sub. Comm, &subrank ); MPI_Comm_size( sub. Comm, &subsize ); printf("old size = %d new size %d ", size, subsize); printf("old rank = %d new rank %dn", rank, subrank); } if( sub. Comm != MPI_COMM_NULL) MPI_Comm_free(&sub. Comm); MPI_Group_free(&subgroup); MPI_Group_free(&group); MPI_Finalize(); return 0; }
Компіляція та виконання [saa@cluster mpi]$ mpicc. /comm_group. c -o comm_group [saa@cluster mpi]$ mpirun -np 10 -wd /net/s 1/$PWD. /comm_group 2 not in communicator 0 not in communicator 1 not in communicator 4 not in communicator 3 not in communicator old size = 10 new size 5 old rank = 8 new rank 3 old size = 10 new size 5 old rank = 9 new rank 4 old size = 10 new size 5 old rank = 5 new rank 0 old size = 10 new size 5 old rank = 6 new rank 1 old size = 10 new size 5 old rank = 7 new rank 2
Отримання ім’я машини, де працює процес char nm[4096]; int name_size = 4096; MPI_Get_processor_name(nm, &nm_size);
#include "mpi. h" int main(int argc, char* argv[]){ MPI_Comm sub. Comm; int size, rank, subsize; int vector[16], i; int result. Vector[16]; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); for( i=0; i<16; i++ ) vector[i] = rank*100 + i; MPI_Reduce( vector, /* кожна задача в коммунікаторі дає вектор */ result. Vector, /* задача номер 'root' збирає дані сюди */ 16, /* кількість комірок в початковому та результуючому масивах */ MPI_INT, /* тип елемента даних */ MPI_SUM, /* описувач операції: поелементне складання векторів */ 0, /* номер задачі, збираючої результати в 'result. Vector' */ MPI_COMM_WORLD /* описувач області св’язку */ ); if( rank==0 ) for(i=0; i<16; i++) printf("result. Vector[%d]=%d ", i, result. Vector[i]); MPI_Finalize(); return 0; }
Приклад виконання [saa@cluster mpi]$ mpirun -np 10 -wd /net/s 1/$PWD. /reduce result. Vector[0]=4500 result. Vector[1]=4510 result. Vector[2]=4520 result. Vector[3]=4530 result. Vector[4]=4540 result. Vector[5]=4550 result. Vector[6]=4560 result. Vector[7]=4570 result. Vector[8]=4580 result. Vector[9]=4590 result. Vector[10]=4600 result. Vector[11]=4610 result. Vector[12]=4620 result. Vector[13]=4630 result. Vector[14]=4640 result. Vector[15]=4650
Вбудовані типи даних C MPI_CHAR MPI_SHORT MPI_INT MPI_LONG MPI_UNSIGNED_CHAR MPI_UNSIGNED_SHORT MPI_UNSIGNED_LONG MPI_UNSIGNED MPI_FLOAT MPI_DOUBLE MPI_LONG_DOUBLE MPI_BYTE MPI_PACKED Fortran MPI_CHARACTER MPI_INTEGER MPI_REAL MPI_DOUBLE_PRECISION MPI_COMPLEX MPI_DOUBLE_COMPLEX MPI_LOGICAL MPI_BYTE MPI_PACKED
Приклад створення типу структури #include <stddef. h> /* підключення макрос 'offsetof()' */ typedef struct { int i; double d[3]; long l[8]; char c; } Any. Struct; Any. Struct st; MPI_Datatype any. Struct. Type; int len[5] = { 1, 3, 8, 1, 1 }; MPI_Aint pos[5] = { offsetof(Any. Struct, i), offsetof(Any. Struct, d), offsetof(Any. Struct, l), offsetof(Any. Struct, c), sizeof(Any. Struct) }; MPI_Datatype typ[5] = { MPI_INT, MPI_DOUBLE, MPI_LONG, MPI_CHAR, MPI_UB }; MPI_Type_struct( 5, len, pos, typ, &any. Struct. Type ); MPI_Type_commit( &any. Struct. Type ); /* підготовка завершена */ MPI_Send( st, 1, any. Struct. Type, . . . );
Упакування даних (серіалізація) Упакування– запис різнотипних структур даних в один масив int MPI_Pack(void *buf, int count, MPI_Datatype dtype, void *packbuf, int packsize, int *packpos, MPI_Comm comm) n INPUT PARAMETERS n q q q n INPUT/OUTPUT PARAMETER q n buf - input buffer start (choice) count - number of input data items (integer) dtype - datatype of each input data item (handle) packsize - output buffer size, in bytes (integer) comm - communicator for packed message (handle) packpos - current position in buffer, in bytes (integer) OUTPUT PARAMETER q packbuf - output buffer start (choice)
Розпакування даних n int MPI_Unpack(void *packbuf, int packsize, int *packpos, void *buf, int count, MPI_Datatype dtype, MPI_Comm comm) n INPUT PARAMETERS packbuf - input buffer start (choice) packsize - size of input buffer, in bytes (integer) count - number of items to be unpacked (integer) dtype - datatype of each output data item (handle) comm - communicator for packed message (handle) n n n n n INPUT/OUTPUT PARAMETERS packpos - current position in bytes (integer) OUTPUT PARAMETER buf - output buffer start (choice)
Приклад упакування-розпакування #define msg. Tag 10 struct { int i; float f[4]; char c[8]; } s; n Передача int buf. Pos = 0; char temp. Buf[ sizeof(s) ]; MPI_Pack(&s. i, 1, MPI_INT, temp. Buf, sizeof(temp. Buf), &buf. Pos, MPI_COMM_WORLD ); MPI_Pack( s. f, 4, MPI_FLOAT, temp. Buf, sizeof(temp. Buf), &buf. Pos, MPI_COMM_WORLD ); MPI_Pack( s. c, 8, MPI_CHAR, temp. Buf, sizeof(temp. Buf), &buf. Pos, MPI_COMM_WORLD ); MPI_Send( temp. Buf, buf. Pos, MPI_BYTE, target. Rank, msg. Tag, MPI_COMM_WORLD ); Прием int buf. Pos = 0; char temp. Buf[ sizeof(s) ]; MPI_Recv( temp. Buf, sizeof(temp. Buf), MPI_BYTE, source. Rank, msg. Tag, MPI_COMM_WORLD, &status ); MPI_Unpack( temp. Buf, sizeof(temp. Buf), &buf. Pos, &s. i, 1, MPI_INT, MPI_COMM_WORLD); MPI_Unpack( temp. Buf, sizeof(temp. Buf), &buf. Pos, s. f, 4, MPI_FLOAT, MPI_COMM_WORLD); MPI_Unpack( temp. Buf, sizeof(temp. Buf), &buf. Pos, s. c, 8, MPI_CHAR, MPI_COMM_WORLD); n
Перевірка стану n Перевірка MPI_Test(MPI_Request *req, int *flag, MPI_Status *stat) q n Статус може бути MPI_STATUS_IGNORE Очікування завершення MPI_Wait(MPI_Request *preq, MPI_Status *stat) n Очікування завершення декількох запросів int MPI_Waitall(int count, MPI_Request *reqs, MPI_Status *stats)
Приклад асинхронної операції MPI_Request reqs[4]; MPI_Status stats[4]; MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag 1, MPI_COMM_WORLD, &reqs[0]); MPI_Irecv(&buf[1], 1, MPI_INT, next, tag 2, MPI_COMM_WORLD, &reqs[1]); MPI_Isend(&rank, 1, MPI_INT, prev, tag 2, MPI_COMM_WORLD, &reqs[2]); MPI_Isend(&rank, 1, MPI_INT, next, tag 1, MPI_COMM_WORLD, &reqs[3]); { do some work } MPI_Waitall(4, reqs, stats);