Hadoop Map Reduce Hadoop v Apache Lucene v







 -> list (k 2, v 2)")
























- Slides: 36
Hadoop / Map. Reduce 讨论与学习
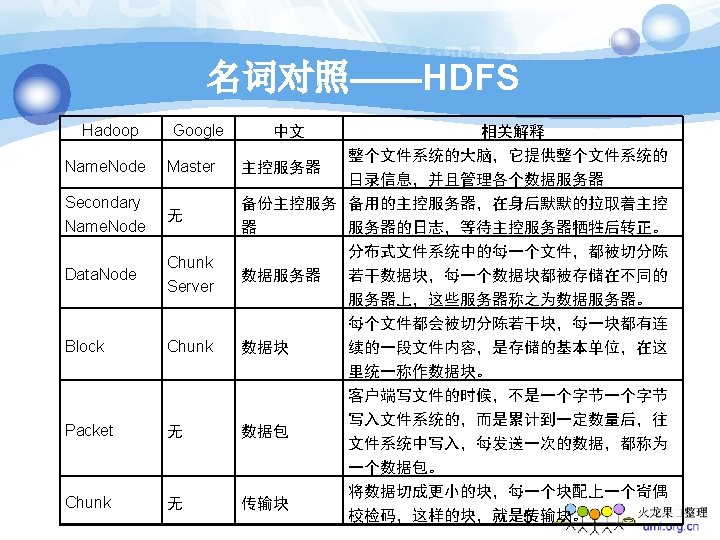
Hadoop 源起 v Apache Lucene § 开源的高性能全文检索 具包 v Apache Nutch § 开源的 Web 搜索引擎 v Google 三大论文 § Map. Reduce / GFS / Big. Table v Apache Hadoop § 大规模数据处理 2
Hadoop 生态系统 v Hadoop 核心 § Hadoop Common § 分布式文件系统HDFS § Map. Reduce框架 v 并行数据分析语言Pig v 列存储No. SQL数据库 Hbase v 分布式协调器Zookeeper v 数据仓库Hive(使用SQL) v Hadoop日志分析 具Chukwa 3
Hadoop VS. Google v 技术架构的比较 § § 数据结构化管理组件:Hbase → Big. Table 并行计算模型:Map. Reduce → Map. Reduce 分布式文件系统:HDFS → GFS Hadoop缺少分布式锁服务Chubby Hadoop云计算应用 HBase Map. Reduce HDFS Google云计算应用 Big. Table Map. Reduce GFS 4 Chubby
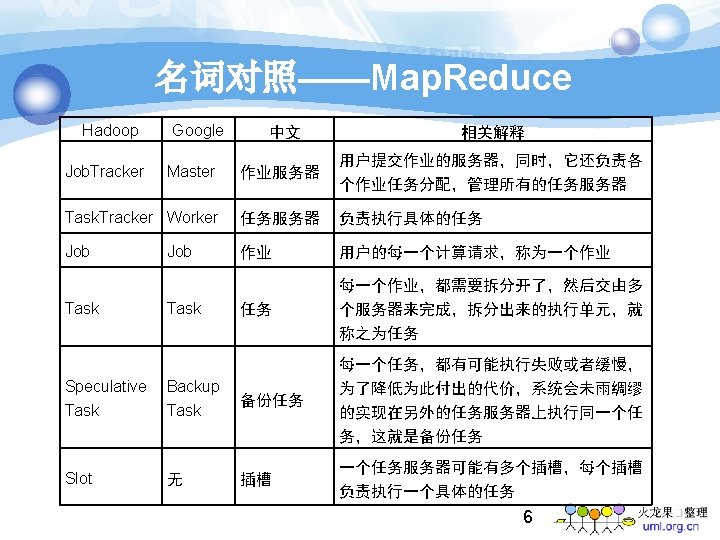
Map. Reduce 作原理 Map: (k 1, v 1) -> list (k 2, v 2) Reduce: (k 2, list(v 2)) -> list (k 3, v 3) 10
Map. Reduce 模型 交换 Input split shuffle output 11
Map. Reduce 作步骤 12
统计单词数 The weather is good Today is good This guy is a good man Good man is good the weather is good 1 1 today 1 is 1 good 1 this guy is a good man 1 1 1 good man is good 1 1 a 1 good good 1 1 1 a 1 good 5 guy 1 is 1 is 4 man 2 the 1 man 1 this 1 the 1 today 1 this 1 weather 1 today 1 weather 1 13
分布存储与并行计算 Data Hadoop Cluster Data data data data data Data data data data data Data data DFS Block 1 DFS Block 2 MAP Results MAP Data data data data Data data data data Data data Reduce DFS Block 2 Data data data Data data MAP DFS Block 3 15
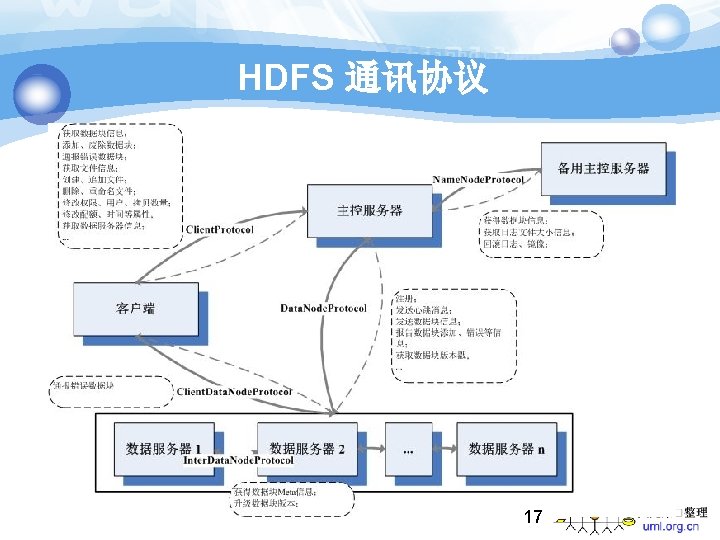
HDFS Architecture 16
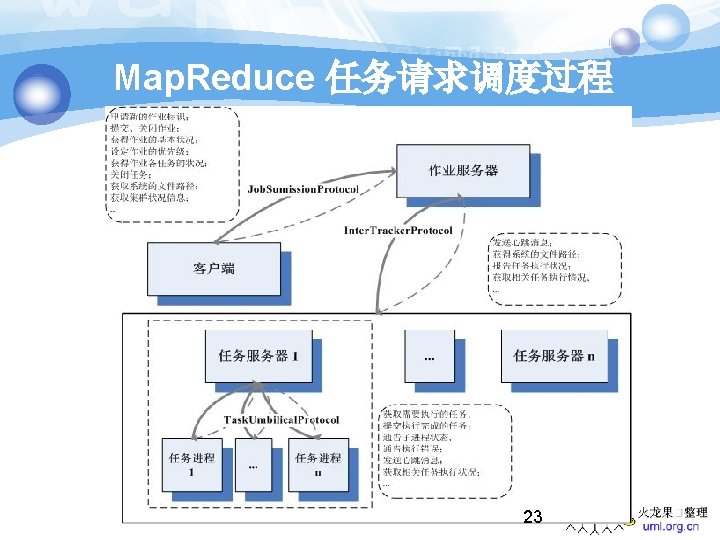
Hadoop 中的 Map. Reduce 架构 21
Map. Reduce 作业执行流程 22
Hadoop安装配置与编写 Map. Reduce程序 24
系统配置 v 环境变量 § 设置java虚拟机路径 v 节点角色 § masters: 第二名称节点 § slaves: 数据节点、tasktracker v Hadoop配置 § core-site. xml § hdfs-site. xml § mapred-site. xml 28
启动系统 • 格式化HDFS § Hadoop namenode -format • 运行脚本 § start-all. sh § start-dfs. sh § start-mapred. sh • jps命令查询java进程 29
运行状态查看 v 内置web服务器 § § Job. Tracker. IP: 50030 Task. Tracker. IP: 50060 Namenode. IP: 50070 Datanode. IP: 50075 v 日志文件 § Job. Tracker/Task. Tracker § Namenode/Datanode 30
安装常见问题 v Incompatible namespace. IDs v Could not obtain block v Java heap space v ssh密码问题 v Incompatible build versions v Cannot delete // Namenode is in safe mode v connect to host master port 22: Conncetion timed out 31
举例:单词计数 § Page 1:the weather is good. § Page 2 : good weather is good. Map 1 (key, value) (the, 1) (good, 1) (weather, 1) (is, 1) (good, 1) Map 2 (key, value) (the, 1) Reduce (weather, 2) (is, 2) (good, 3) 32
Map函数 v void map(Long. Writable key, Text value, Output. Collector<Text, Int. Writable> output, Reporter reporter) { String line = value. to. String(); String. Tokenizer t= new String. Tokenizer(line); while (t. has. More. Tokens()) { word. set(t. next. Token()); output. collect(word, one); } } 33
Reduce函数 v void reduce(Text key, Iterator<Int. Writable> values, Output. Collector<Text, Int. Writable> output, Reporter reporter) { int sum = 0; while (values. has. Next()) { sum += value. next(). get(); } output. collect(key, new Int. Writable(sum)); } 34