Distributed Computing for Big Data Apache Hadoop Distributed

Distributed Computing for Big Data 박영택 컴퓨터학부

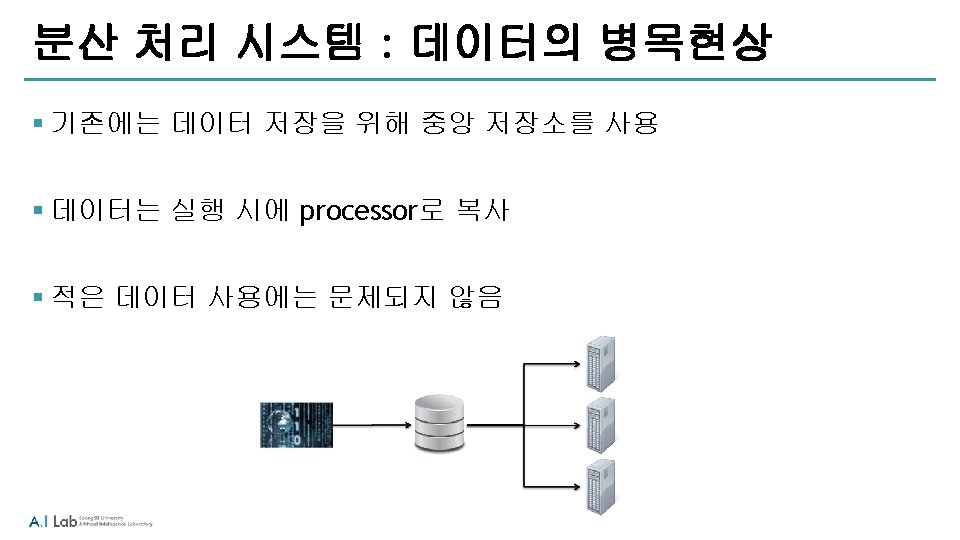
Apache Hadoop이란? § 빅데이터를 저장, 처리, 분석할 수 있는 소프트웨어 프레임워크 ‐Distributed ‐Scalable ‐Fault-tolerant ‐Open source
















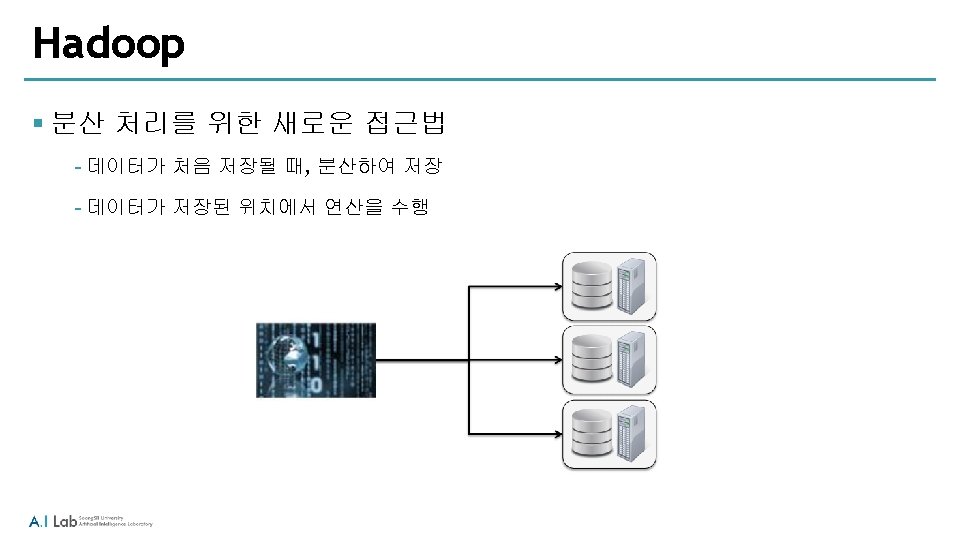

Core Hadoop Concepts § 애플리케이션은 high-level code로 작성 § Node들은 가능한 최소한의 통신을 수행 § 데이터는 미리 분산 되어 저장됨 ‐Computation to Data § 데이터의 replication 생성하여, availability와 reliability 향상 § Hadoop은 scalable하며 fault-tolerant를 지원함


Hadoop의 문제점 § 데이터의 특성 ‐Volume ‐Velocity ‐Variety § 데이터 분석의 특징 ‐Batch processing ‐Parallel execution ‐Distributed data
 § Map.")
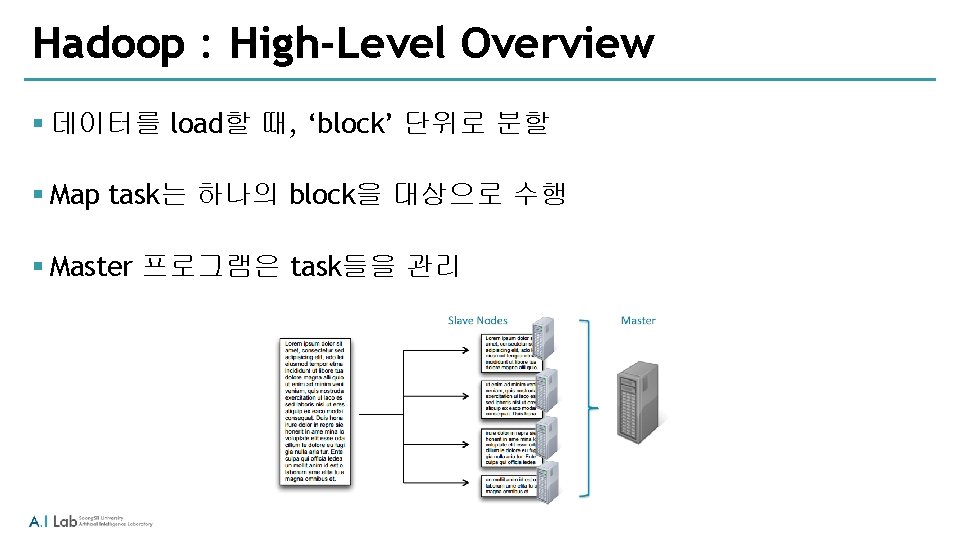
Hadoop : Basic Concepts § Hadoop이란? § Hadoop Distributed File System (HDFS) § Map. Reduce 프로그램 § Hadoop 클러스터의 운영

Hadoop Project § Hadoop은 Apache 소프트웨어의 open-source 프로젝트 § 2003년과 2004년의 Google 논문을 기반으로 함 § 전세계의 다양한 조직들의 Hadoop committer들이 활동 ‐Cloudera, Yahoo, Facebook, Linked. In
 ‐")
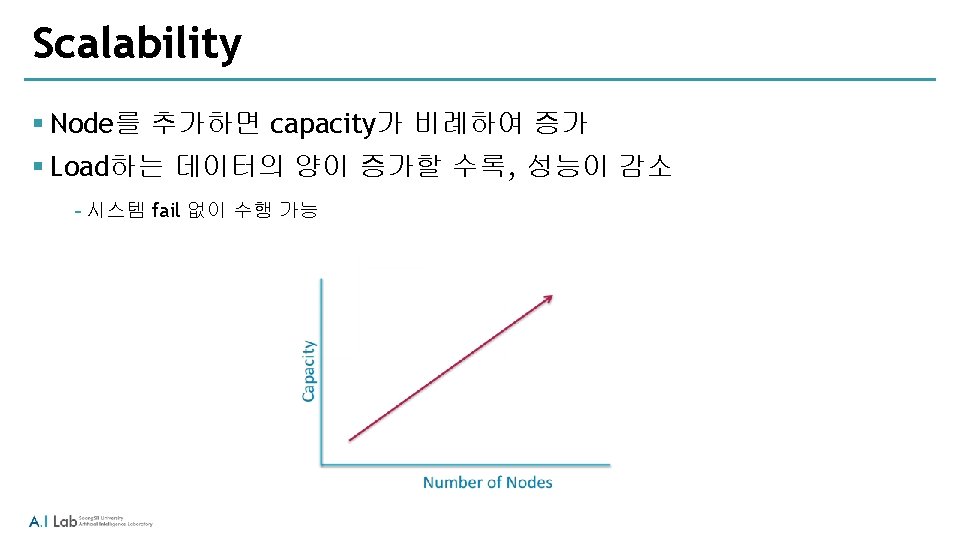
Hadoop Components § Hadoop은 주요 구성 요소 ‐ Hadoop Distributed File System (HDFS) ‐ Map. Reduce § Hadoop을 기반으로 하는 다른 프로젝트 ‐ ‘Hadoop Ecosystem’이라고 하는 Pig, Hive, HBase, Flume, Oozie, Sqoop 등이 있음 § Hadoop 클러스터는 HDFS와 Map. Reduce를 사용할 수 있도록 구성된 여러 개의 machine들 을 말함 ‐ 각각의 개별 machine은 node ‐ A cluster can have as few as one node, as many as several thousand ‐ 하나의 클러스터는 최소 1개의 node에서 수 천개의 node로 구성될 수 있음 ‐ 더 많은 node를 사용할 수록 더 좋은 성능을 얻을 수 있음

Hadoop Components Note: CDH is Cloudera’s open source Apache Hadoop distribution
 ‐클러스터에")
Core Components : HDFS and Map. Reduce § HDFS (Hadoop Distributed File System) ‐클러스터에 데이터를 저장 § Map. Reduce ‐클러스터의 데이터를 처리




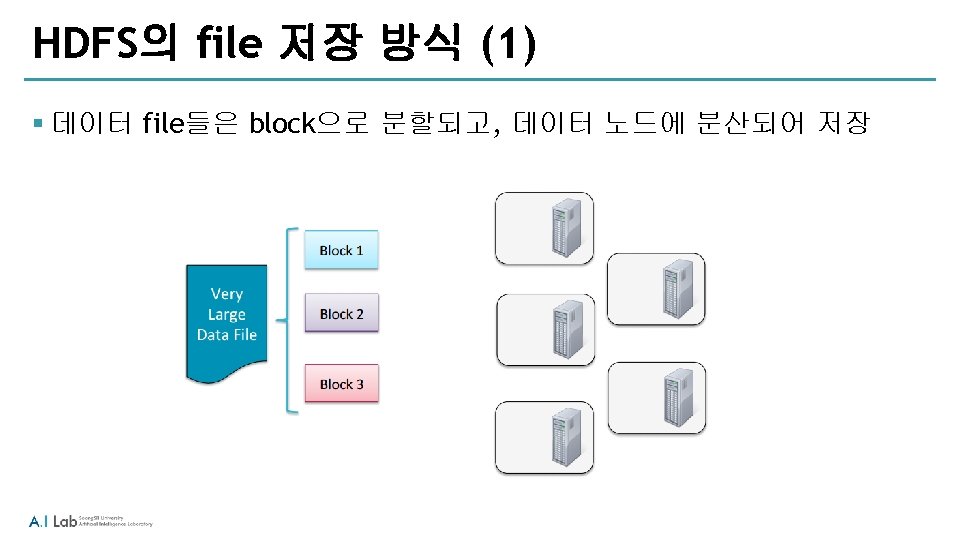
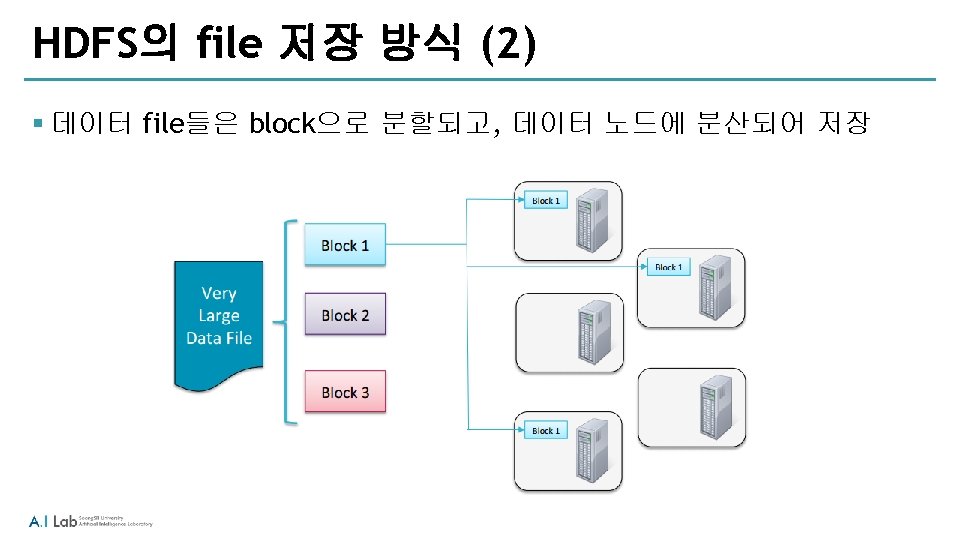
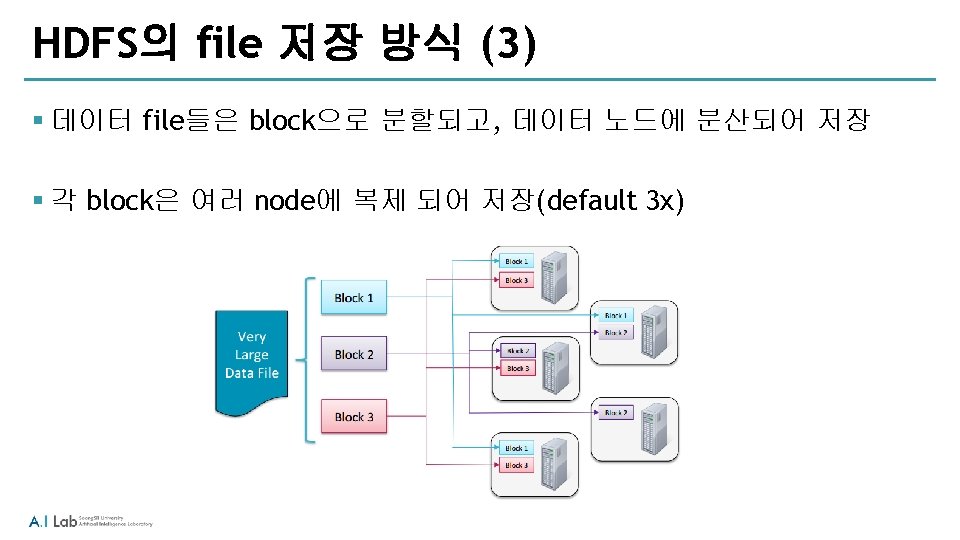
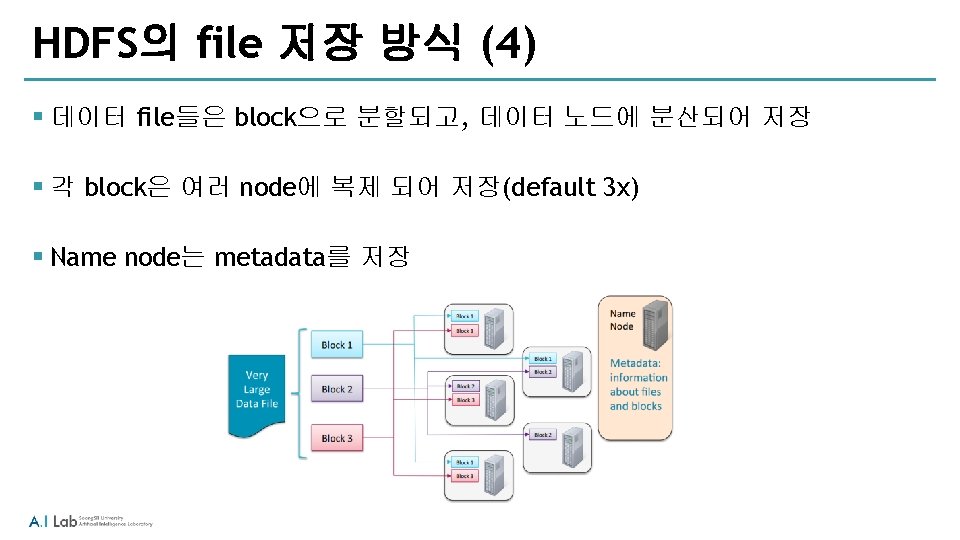


HDFS 접근 방법 § Shell 커맨드 라인을 사용: haddop fs § Java API § Ecosystem 프로젝트 ‐Flume ‐ network sourc로 부터 데이터 수집 ‐Sqoop ‐ HDFS와 RDBMS 사이의 데이터 전송 ‐Hue ‐ Web 기반의 interactive UI로 browse, upload, download, file view 등이 가능
")
Example: Storing and Retrieving Files (1)
")
Example: Storing and Retrieving Files (2)
")
Example: Storing and Retrieving Files (3)
")
Example: Storing and Retrieving Files (4)

HDFS Name. Node Availability § Name. Node daemon은 반드시 항상 실행되고 있어야 함 ‐Name. Node가 중단되면, 클러스터는 접근이 불가능 § High Availability mode (in CDH 4 and later) ‐ 2개의 Name. Node : Active와 Standby § Classic mode ‐ 1개의 Name. Node ‐또 다른 “helper” node는 Secondary. Name. Node ‐ backup이 목적이 아니며, 장애 발생 시 Name. Node를 대신하는 것이 불가능 ‐ Name. Node를 복구 할 수 있는 정보를 제공

 § HDFS의 경로 /user/fred/bar. txt의 내용을 출력 § HDFS의 baz.")
hadoop fs Examples (2) § HDFS의 경로 /user/fred/bar. txt의 내용을 출력 § HDFS의 baz. txt file을 로컬 디렉토리로 복사
- Slides: 47