Nowe abstrakcje programowania rozproszonego Wykad Map Reduce Laboratoria

Nowe abstrakcje programowania rozproszonego Wykład: Map Reduce Laboratoria: Hadoop Aftowicz Jakub Ciesielczyk Tomasz

Problemy Bi g D a t a Big Data

Ma p R e d u c e Map. Reduce Aftowicz Jakub Ciesielczyk Tomasz

Motywacje �Page Rank – mnożenie dużych macierzy przez wektor �Przeglądanie i przeszukiwanie sieci społecznościowych (facebook – ponad miliard użytkowników). Grafy z miliardem węzłów oraz miliardami (bilionami) krawędzi. �Analiza zawartości pobranych stron �Tworzenie indeksów odwrotnych

Przykład word count Ala ma kota. Ala ma psa. Pies ma Alę. słowo ilość Ala 2 Ma 3 Kota 1 Psa 1 Pies 1 Alę 1
;")
Word count – jedna maszyna Hash. Map<String, Integer> word. Count = new Hash. Map<>();
;")
Word count – jedna maszyna Hash. Map<String, Integer> word. Count = new Hash. Map<>(); for (Document document : document. Set){ String[] T = tokenize ( document ) ; }
;")
Word count – jedna maszyna Hash. Map<String, Integer> word. Count = new Hash. Map<>(); for (Document document : document. Set){ String[] T = tokenize ( document ) ; for(String token: T){ if (!word. Count. contains. Key(token)){ word. Count. put(token, 1); } else{ word. Count. put(token, word. Count. get(token)+1); } } }
;")
Word count – wiele maszyn Hash. Map<String, Integer> word. Count = new Hash. Map<>(); for (Document document : document. Sub. Set){ String[] T = tokenize ( document ) ; for(String token: T){ if (!word. Count. contains. Key(token)){ word. Count. put(token, 1); } else{ word. Count. put(token, word. Count. get(token)+1); } } } send. Second. Step(word. Count);

Word count – wiele maszyn Second step: Hash. Map<String, Integer> global. Word. Count; for ( Hash. Map<String, Integer> word. Count : received. Word. Count) { add(global. Word. Count , word. Count); }

Word count – wiele maszyn Aby procedura mogła zadziałać na grupie maszyn, musimy spełnić następujące funkcjonalności: �Składowanie plików (fragmentów danych) na dyskach maszyn (document. Sub. Set) �Zapisywanie dane do tabeli hashowych opartych o dyski twarde tak by nie być ograniczonym pamięcią RAM �Podzielenie danych pośrednich (word. Count) z kroku pierwszego. �Rozdysponowanie fragmentów danych do odpowiednich maszyn �Sprawdzanie poprawności

Word count – wiele maszyn �Co się stanie w przypadku awarii jednej ze stacji roboczych? �Co się stanie w przypadku awarii zarządcy? �Co się stanie w przypadku natrafienia na wadliwe dane? �Jak należy rozproszyć dane? �W jaki sposób zebrać wyniki?

Map. Reduce - Założenia �Automatyczna dystrybucja danych programista tylko definiuje w jaki sposób odczytywać dane (np. podziel wiersz w pliku po średniku) �Automatyczne zrównoleglenie zadań programista tylko pisze co chce zrobić (reducer) �Automatyczne zarządzanie zadaniami zrównoleglenie wątków jest transparentne dla programisty

Map. Reduce - Założenia �Odporność - implementacja powinna być niewrażliwa na awarię maszyn �Automatyczna komunikacja �„Load balancing” �Skalowalność – skalowalny liniowo poprzez dodawanie kolejnych maszyn �Dostępność – użycie na grupie normalnych maszyn (PC), chmura obliczeniowa typu Amazon, Beyond

Map. Reduce - Idea �Map Generowanie pary klucz-wartość �Reduce Łączy wartości związane z wcześniej wygenerowanymi kluczami „Dziel i zwyciężaj”
 List<key")
Map. Reduce - Idea Input Output Map Raw data-> (<key 1, value 1>) List<key 2, value 2> Reduce <key 2, (List<value 2>) List<key 3, val 3>

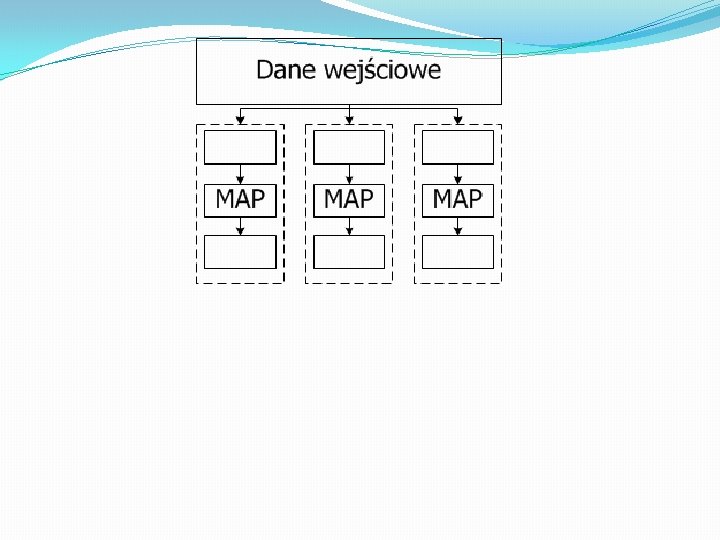
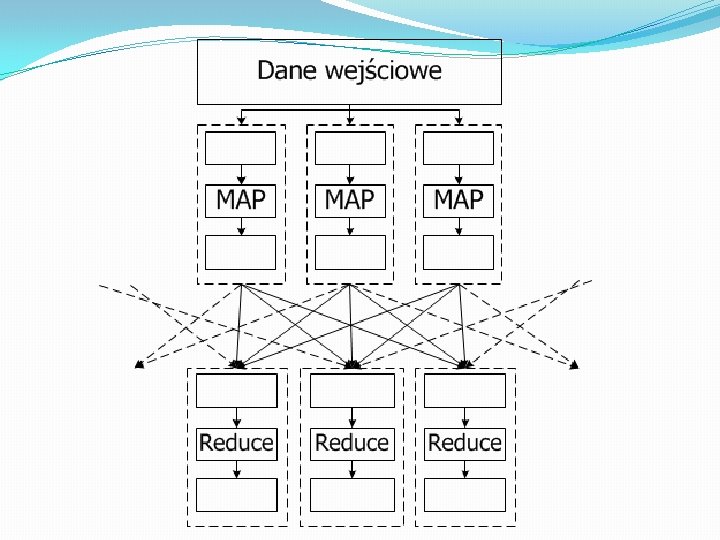
")
Word count – Map. Reduce public map ( String filename , String document ) { List<String> T = tokenize ( document ) ; for(String token: T){ emit (token , 1) ; } }
")
Word count – Map. Reduce public reduce ( String token , List<Integer> values ) { Integer sum = 0; for(Integer value : values) { sum = sum + value ; } emit (token , sum) ; }

Mnożenie macierzy przez wektor �Zdefiniujmy macierz M o rozmiarze n x n o elementach mij oraz wektor V o długości n o elementach vj �Wynikiem iloczynu M*V jest wektor X o długości n o elementach zdefiniowano: �Macierz M jest przechowywana za pomocą trójki liczb (i, j, mij )

Mnożenie macierzy przez wektor �Załóżmy, że n jest duże, ale nie na tyle, żeby wektor nie zmieścił się w pamięci i jest dostępny w każdym Mapperze

Mnożenie macierzy przez wektor �Map: �Przechowuje cały wektor v i fragment macierzy M. �Z każdego elementu mij produkuje parę klucz-wartość <i, mij*vj> component �Reduce �Sumowanie wszystkich wartości dla danego klucza i (komórka wektora x). Wyjście : <i, xi>

Mnożenie macierzy przez wektor �Załóżmy, że n jest na tyle duże że wektor nie zmieścił się w pamięci Mappera i musi nastąpić jego podział �Podzielmy zatem macierz na pionowe fragmenty o jednakowej szerokości, a następnie wektor na jednakową ilość poziomych fragmentów �i-ty fragment macierzy będzie mnożony jedyni z elementami z i-tego fragmentu wektora

Mnożenie macierzy przez wektor

Mnożenie macierzy przez wektor �Map: �Przechowuje fragment wektora v i macierzy M. �Z każdego elementu mij produkuje parę klucz-wartość <i, mij*vj> component �Reduce �Sumowanie wszystkich wartości dla danego klucza i (komórka wektora x). Wyjście : <i, xi>

Korzyści… �Umożliwia programistom bez doświadczenia z dziedziny systemów równoległych i rozproszonych, korzystanie z zasobów dużego systemu rozproszonego �Ukrywa „niechlujne” szczegóły zrównoleglenia, obsługi błędów, rozproszenie danych i równoważenie obciążenia w bibliotece.

Awaria workera �Master periodycznie pinguje każdego workera �Master oznacza wadliwego workera �Wszystkie zadania Mapowania zlecone do tej pory danemu workerowi przywracane są do stanu Idle �Wyniki przechowywane są lokalnie na maszynie która uległa awarii �Ukończone zadania typu Reduce nie muszą być powtarzane �Wyniki zadań Reduce przechowywane są w GFS

Awaria workera �Kiedy zadanie Map zostaje przeniesione z workera A do B wszyscy workerzy wykonujący zadania typu Reduce zostają powiadomieni o zmianie �Powtórne wykonanie podstawowym mechanizmem obsługi błędów �Map. Reduce jest odporne na awarie wielu stacji roboczych naraz, przenosząc obliczenia na działające maszyny i kontynuąjąc przetwarzanie

Awaria Mastera �Master może wykonywać Checkpointy �Po awarii nowa kopia Mastera może wystartować z ostatniego Checkpointu �Jednak przy posiadaniu tylko jednego Mastera sznasa jego awarii jest niewielka… �… dlatego implementacje przerywają przetwarzanie w przypadku awarii mastera

Ciekawostki i zalecenia �Problem „Maruderów” �Wykonania „Pojedynczych” zadań się przeciągają �Backup Tasks �Do 44% wzrost czasu wykonania �Problem „Złych Rekordów” �Błędy w kodzie użytkownika powodujące awarie w wyniku przetwarzania pewnych danych �Błędy w zewnętrznych bibliotekach �Czasami dopuszczalne jest pominięcie niektórych rekordów
 mod R) �Użytkownika � Np. grupowanie po")
Ciekawostki i zalecenia �Partycjonowanie �Domyślne � (hash(key) mod R) �Użytkownika � Np. grupowanie po URL (hash(Hostname(urlkey)) mod R) � Zasoby na jednym serwerze odpytywane przez jednego workera � korzystamy z usprawnień protokołu HTTP i HTTPS � Sortowanie (Tera. Sort)

Ciekawostki i zalecenia �Combiner �Kierowanie danych w paczkach do Reducerów �Z reguły powiela kod Reducera �Potrafi znacząco przyspieszyć rozwiązywani niektórych problemów Map. Reduce �Np. word count � wiele <the, 1> zagregowane do <the, k> � Oszczędność przy wysyłaniu przez sieć

Map. Reduce: koszt i problemy �Wąskim gardłem dla Map. Reduce jest komunikacja danych po sieci �Ilość zadań powinna być dużo większa od ilości workerów

Map. Reduce koszt i problemy �Dla maksymalnego zrównoleglenia mappery i reducery powinny być stateless, nie powinny zależeć od żadnych danych w obrębie zadania Map. Reduce. Nie jest możliwym sterowania porządkiem wykonywania zadań map i reduce. �Faza reduce nie jest wykonywana przed zakończeniem fazy map �Zakłada się, że wynik reducera jest mniejszy od wejścia mappera

Map. Reduce: koszt i problemy Czy Map. Reduce/Hadoop rozwiąże moje problemy? � tak, jeśli umiesz przekształcić algorytm do postać Map-Reduce � „It is not a silver bullet to all the problems of scale, just a good technique to work on large sets of data when you can work on small pieces of that dataset in parallel „
 �t, t’ : krotki �s")
SQL a Map. Reduce �R, S – relacje (tabele) �t, t’ : krotki �s – warunek selekcji �A, B, C – podzbiór atrybutów �a, b, c – wartości atrybutów dla danego podzbioru atrybutów

Selekcja �Map Dla każdej krotki t w R sprawdź czy spełnia warunek selekcji s. Jeśli spełnia to produkuj parę klucz wartość: (t, t) �Reduce Po prostu przekazuje dane na wyjście

Projekcja �Map Dla każdej krotki t w R wyprodukuj krotkę t’ poprzez wyeliminowanie atrybutów spoza zbioru A. Wyjście (t, t’) �Reduce Dla każdego klucza może być wiele krotek t’. Wejście (t’, [t’, …t’]). Wyjście: dla każdej krotki t’ wyprodukuj (t’, t’)
 �Map wyjście: (t’, t’) dla każdej z relacji S i R �Reduce")
Suma (Union) �Map wyjście: (t’, t’) dla każdej z relacji S i R �Reduce Dla każdego klucza t wyprodukuj (t, t)
). Dla krotki t")
Różnica �Map Dla krotki t z relacji R wyprodukuj (t, name(R)). Dla krotki t z relacji S: (t, name(S)) � Reduce Dla każdego klucza t : -jeśli lista wartości zawiera tylko name(R) to wyporodukuj (t, t) -jeśli lista wartości zawiera: [name(R), name(S)] lub [name(s)] lub [name(S), name(R)] nie produkuj nic
 �Reduce Jeżeli klucz t")
Przecięcie �Map: dla każdej R lub S wyprodukuj (t, t) �Reduce Jeżeli klucz t ma parę wartości to wyprodukuj (t, t). W Przeciwnym wypadku nie produkuj nic
![Natural Join �Map dla każdej krotki (a, b) z R wyprodukuj (b, [name(R), a]).](http://slidetodoc.com/presentation_image/2c29b1e23027d44b040f18ebef72c4a9/image-44.jpg "Natural Join �Map dla każdej krotki (a, b) z R wyprodukuj (b, [name(R), a]).")
Natural Join �Map dla każdej krotki (a, b) z R wyprodukuj (b, [name(R), a]). Dla każdej krotki (b, c) z S wyprodukuj (b, [name(S), c]) �Reduce klucz b zawiązany jest z wartościami: [name(R), a] i [name(S), c]. Wygeneruj wszystkie możliwe pary: (b, a 1, c 1), (b, a 2, c 1), … , (b, an, cn).
. Aby pogrupować ją po")
Grupowanie i Agregacja �Map Dana relacja R (A, B, C). Aby pogrupować ją po atrybucie A i zagregować po atrybucie B wyprodukuj parę (a, b) �Reduce wejście: (a, [b 1, b 2 …]). Dla listy wartości przeprowadź funkcje agregacji, np. suma. Wyprodukuj parę (a, x) gdzie x to suma wszystkich wartości dla klucza a

Hadoop Aftowicz Jakub Ciesielczyk Tomasz

Hadoop �Implementacja Open. Source Map. Reduce �Pracuje w architekturze master/slave dla rozproszonych danych oraz rozproszonych obliczeń �Uruchomienie Hadoopa wiąże się z uruchomieniem szeregiem różnych usług na serwerach dostępnych w sieci: Name. Node, Data. Node, Secondary Name. Node, Job. Tracker, Task. Tracker

Hadoop
, kieruje niskopoziomowymi operacjami we/wyj na")
Hadoop - Name. Node �Zarządza Hadoop File System (HDFS), kieruje niskopoziomowymi operacjami we/wyj na Data. Node �Śledzi podział danych (plików) na bloki, wie gdzie te bloki się znajdują �Name. Node zazwyczaj nie przechowuje żadnych danych oraz nie robi żadnych obliczeń dla procesu Map. Reduce �W przypadku awarii Name. Node HDFS nie działa. Można opcjonalnie użyć Secondary. Name. Node
")
Hadoop – Secondary Name. Node �Odpowiada za monitorowanie stanu HDFS �Każda grupa komputerów/klaster? (cluster) ma jeden Secondary Name. Node, który znajduje się na osobnej maszynie �Różni się od Name. Node tym że nie dostaje ani nie rejestruje żadnych danych w czasie rzeczywistym od HDFS. W zamian za to komunikuje się z Name. Node, żeby zapisać stan HDFS (snapshot). Częstotliwość zapisu jest determinowana przez ustawienia klastra.

Hadoop – Job Tracker �Łączy aplikację użytkownika z Hadoopem �Jak tylko kod jest dostarczony do klastra, Job. Tracker planuje wykonanie poprzez wybór plików do przetwarzania, przydziela różne zadania do węzłów. �Monitoruje wykonywujące się zadania. �W przypadku awarii Job. Tracker przydziela zadanie do innego węzła. �Jest tylko jeden Job. Tracker na klaster Hadoopa �Kiedy zadanie zostanie skończone przez maszynę, Job. Tracker aktualizuje status �Jeśli padnie, wszystkie zadania zostają zatrzymane

Hadoop - Data. Node �Każda maszyna slave robi podstawowe zadania związane z HDFS: czytanie i pisanie bloków HDFS na lokalny system �Nie ma replikacji danych w obrębie jednego Data. Node �Data. Node może komunikować się z innymi Data. Nodami w celu replikowania bloków danych �Data. Nodes ciągle informują Name. Node o blokach danych, które aktualnie posiadają �Aplikacja użytkownika może bezpośrednio odwoływać się do Data. Node

Hadoop – Task Tracker �Task. Trackers zarządza wykonywanie pojedynczego zadania na maszynie slave �Pomimo, że jest tylko jeden Task. Tracker na jeden węzeł to może stworzyć wiele JVM dla obsługi wielu mapperów czy reducerów równolegle �Task. Tracker cały czas komunikuje się Job. Trackerem �Jeśli Job. Tracker nie odbierze sygnału ‘hearbeat’ od Task. Trackera przez określony przedział czasowy to zakładana jest awaria maszyny slave i zadanie zostaje przekazane do innej maszyny
 na zbiorach danych 3.")
Plan laboratorium 1. Word. Count 2. Proste działania (średnie, sumy) na zbiorach danych 3. Zapytania SQL � Selection � Group by � Order by � Natural join

WC w hadoopie public class Word. Count extends Configured implements Tool{ public static class Map. Class extends Map. Reduce. Base implements Mapper<Long. Writeable, Text, Int. Writeable> { private final static Int. Writeable one = new Int. Writeable(1); private Text word = new Text(); public void map(Long. Writeable key, Text value, Output. Collextor<Text, Int. Writeable> output, Reporter reporter) throws IOException{ String line=value. to. String(); String. Tokennizer itr = new String. Tokenizer(line); while(itr. has. More. Tokens()){ word. set(itr. next. Token()); output. collect(word, one); } } }

WC w hadoopie public static class Reduce extends Map. Reduce. Base implements Text, Int. Writeable, Text, Int. Writeable> { public void reduce (Text key, Iterator<Int. Writable> values, Output. Collextor<Text, Int. Writeable> output, Reporter reporter) throws IOException{ int sum =0; while(values. has. Next()){ sum+=values. next(). get(); } output. collect(key, new Int. Writable(sum)); } } }

Pytania? ?

Dziękujemy za uwagę i zapraszamy na zajęcia laboratoryjne

Materiały �https: //www. usenix. org/legacy/event/osdi 04/tech/full_papers/ dean/dean. pdf �http: //www. manning. com/lam/Sample. Ch 10. pdf �http: //wiki. apache. org/hadoop/Project. Description �http: //wiki. apache. org/hadoop/Hadoop. Is. Not �http: //wiki. apache. org/hadoop/Map. Reduce �http: //infolab. stanford. edu/~ullman/mmds/ch 2. pdf �http: //userpages. unikoblenz. de/~laemmel/Map. Reduce/paper. pdf �http: //sortbenchmark. org/Yahoo. Hadoop. pdf
- Slides: 59