Hadoop Hadoop Hadoop Ecosystem LOGApache Flume Apache HBase


課程大綱 • Hadoop 起源與演進 • Hadoop特色與發展現況 • Hadoop Ecosystem 架構 – 收集LOG就靠Apache Flume – 分散式資料庫Apache HBase – Apache HBase別跟關聯式資料 搞混 – Apache HBase 架構 – Apache Pig後Map-Reduce簡單 多了 • – 原來Apache Hive 是這樣來的 – Hive和SQL 比較 – Pig vs Hive – Apache Sqoop幫你把SQL Data 導入到Hadoop – Apache Sqoop 邏輯架構 – Hadoop運行任務用Apache OOZIE管理 – Apache Zoo. Keeper來管理 Hadoop軍火 – 分析 具Apache Mahout和R Connector就綽綽有餘 結語 2


Hadoop 起源與演進 • Hadoop 這頭大象自 2006 年 2 月被 Doug Cutting 送進 Apache Software Foundation 餵養以來,已歷 經 8 又 1/2 個年頭 Yarn! 年度 發行次數 2007 5 2008 14 2009 5 2010 2 2011 6 2012 13 2013(截至 8. 24) 11 總計 年平均 56 ! Latest Version Hadoop 2. 4. 1 Latest Version Hadoop 1. 2. 1 8 資料來源:http: //www. slideshare. net/Hadoop_Summit/evans-june 27 -230 pmroom 210 c 4


Hadoop特色與發展現況 Yahoo案例 • 有40, 000個上線執行的Hadoop節點 • 每天約500, 000個Map/Reduce 作 • 超過350 Peta-bytes的儲存量 資料來源:http: //www. slideshare. net/ydn/hadoop-yahoo-internet-scale-data-processing 6
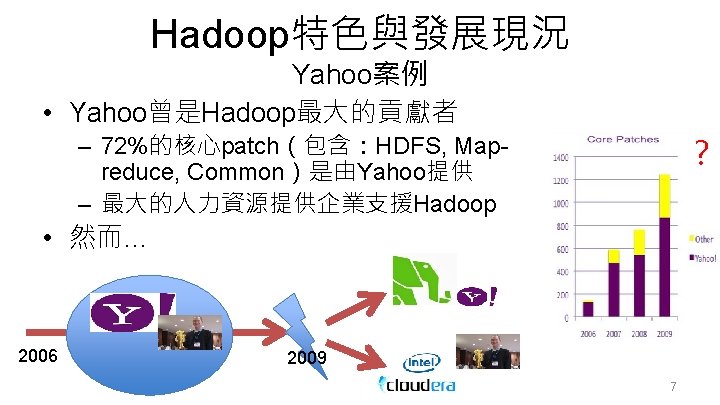

Hadoop ecosystem 架構 資料來源: http: //www. ahp-numerique. fr/index. php? title=Big_data 8

收集Log 就靠Apache Flume • 即時日誌收集系統 • 將分佈在不同節點、機器上的日誌收集到hdfs 中 • IBM Big. Insights 已經將Flume 作為產品的一 部分 資料來源: http: //www. ibm. com/developerworks/opensource/library/bd-flumews/index. html 9

分散式資料庫Apache HBase • HBase是參考谷歌Big. Table建模的No. SQL • Apache HBase最初是Powerset公司為了處理自然語言搜索產 生的海量數據而開展的項目 • Facebook在 2010年 11月選用了HBase來實作了”訊息平台” • 特性: – – 類似表格的資料結構 (Multi-Dimensional Map) 分散式 高可用性、高效能 很容易擴充容量及效能 Apache Hbase: http: //hbase. apache. org/ 資料來源: http: //zh. wikipedia. org/wiki/Apache_HBase 資料來源: http: //contest. trendmicro. com/2014/cn/material/hbase. pdf 10


Apache HBase 架構 Region Row Keys 00000……. . Region 1 ……. . Column Family “Content: ” ……. . 09999……. . 10000……. . Region 2 ……. . 29999……. . • 表格是由一或多個 region 所構成 • Region 是由其 start. Key 與end. Key 所指定 • 每個 region 可能會存在於多個不同 節點上,而且是由數個HDFS 檔案與 區塊所構成,這類 region ……. . Apache Pig: http: //pig. apache. org/ 資料來源: http: //contest. trendmicro. com/2014/cn/material/hbase. pdf 12

有Apache Pig~Map-Reduce簡單了 ! • Apache Pig 適合於使用 Hadoop 和Map. Reduce 平台來 查詢大型半結構化數據集 $ pig –x local • Pig元件. . . - Connecting to. . . 2014年 8月0. 13. 0最 今版 2011年 07月 0. 9. 0 python UDF – Pig Shell (Grunt) grunt> A = LOAD ‘file 1’ AS (x, y, z); 2010年 12月 0. 8. 0 python UDF – Pig Language (Latin) 2010年成為 Apache 的主要項目 – Libraries (Piggy Bank) 2008年 Yahoo將Pig移 – User Defined Functions (UDF): 交給Apache團隊,並 release Pig 0. 1 使用者定義操作Pig 2008 資料來源:http: //www. ithome. com. tw/node/73980 13

Apache Pig後Map-Reduce簡單了 x y z t u v 王 北 10$ Tel 林 21$ 李 中 11$ Mo 李 32$ Map-Reduce 李 中 11$ Mo 32$ 1 Java Code in Eclipse 14
 A = LOAD ‘file")
Apache Pig後Map-Reduce簡單了 Logical Plan Pig Latin LOAD (x, y, z) A = LOAD ‘file 1’ AS (x, y, z); LOAD (t, u, v) B = LOAD ‘file 2’ AS (t, u, v); FILTER (x, y, z) C = FILTER A by y > 0; D = JOIN C BY x, B BY u; (x, y, z, t, u, v) JOIN E = GROUP D BY z; (group, {(x, y, z, t, u, v)}) F = FOREACH E GENERATE group , COUNT(D); STORE F INTO ‘output’; GROUP FOREACH (group, count) STORE (group, count) 李 中 11$ Mo 資料來源: http: //www. slideshare. net/hbshashidhar/apache-pig-v-62? next_slideshow=1 32$ 1 15

Apache Pig後Map-Reduce簡單了 • Pig無法像SQL DBMS 具,提供導入資料庫功能 功能 指令 讀取 LOAD 儲存 STORE 資料處理 FILTER, FOREACH, GROUP, COGROUP, inner JOIN, outer JOIN, UNION, SPLIT, … 彙總運算 AVG, COUNT, MAX, MIN, SIZE, … 數學運算 ABS, RANDOM, ROUND, … 字串處理 INDEXOF, SUBSTRING, REGEX EXTRACT, … Debug DUMP, DESCRIBE, EXPLAIN, ILLUSTRATE HDFS cat, ls, cp, mkdir, … 資料來源: http: //fenriswolf. me/2012/03/22/apache-pig-%E 7%B 0%A 1%E 4%BB%8 B/ 16

原來Apache Hive 是這樣來的 • Hive在Hadoop中扮演數據倉庫的角色 • 相似SQL操作語法 • 起源於Face. Book,為了解決March 2008 每天有 200 GB資料在成長的資料倉儲的問題 • 缺點: – Hive無法有效OLAP – 不能操作SQL的INSERT資料方法 – 不能提共TRANSACTION方法 Apache Hive:http: //hive. apache. org/ 資料來源: http: //www. slideshare. net/zshao/hive-data-warehousing-analytics-on-hadooppresentation 17

Hive和SQL 比較 Hive RDMS �詢語法 HQL SQL 儲存體 HDFS Raw Device or Local FS 運算方法 Map. Reduce Excutor 延遲 高 低 處理數據規模 大 小 索引 0. 8版本後加入位 圖 複雜健全的索引機 制 資料來源:http: //sishuok. com/forum/blog. Post/list/6220. html 18

Pig vs Hive • Hive更適合於數據倉庫的任務,用於靜態的 結構及需要經常分析的 作 • Pig賦予開發人員在Big Data中,具備更多 的靈活性,並允許開發簡潔腳本 – 用於轉換資料流,以便嵌入到較大的應用程序 Feature Pig Language SQL-LIKE Pig. Latin Schemas/ Yes Types (explicit) Yes (implicit) Partitions Yes No Optional( Thrift) No Yes(limite d) No • Pig比Hive輕量,Pig可採用Java API串接,,Server 因此,Pig較吸引軟體開發人員 Web • Hive和Pig都可以與HBase組合使用,Hive Interface 和Pig還為HBase提供了高階語言支援,在 JDBC/OD HBase上進行數據統計處理變的非常簡單 BC 資料來源:http: //blog. csdn. net/devtao/article/details/14213481 資料來源: http: //f. dataguru. cn/thread-33553 -1 -1. html Hive 19
")
Apache Sqoop幫你把 SQL Data導入到Hadoop • Apache Sqoop = SQL to Hadoop • Apache Sqoop允許使用者從關聯式資料庫(RDBMS) 中擷取資料到 Hadoop 資料來源: http: //hive. 3 du. me/slide. html 資料來源: https: //blogs. apache. org/sq oop/entry/apache_sqoop_gr aduates_from_incubator 20
 (import-args) 案例 Sqoop import –connect jdbc: mysql:")
Apache Sqoop 邏輯架構 Mysql到HDFS Sqoop import (generic-args) (import-args) 案例 Sqoop import –connect jdbc: mysql: //localhost: 3306/sqoop_test – direct –table adpv –username root -P 資料來源: http: //baiyunl. iteye. com/blog/964254 Apache Sqoop 21 http: //sqoop. apache. org/
中 •")
Hadoop運行任務用 Apache Oozie管理 • 它讓我們可以把多個Map/Reduce作業組合 到一個邏輯 作單元中,從而完成更大型 的任務 • Oozie是一種Java Web應用程序,它運行 在Java servlet容器(即Tomcat)中 • Apache Oozie:http: //oozie. apache. org/ 資料來源: http: //www. infoq. com/cn/articles/introduction. Oozie 22


Apache Zoo. Keeper來管理Hadoop軍火 Performance 資料來源:http: //tutorialshadoop. com/what-is-apache-zookeeper-and-it-uses/ 資料來源:http: //zookeeper. apache. org/doc/trunk/zookeeper. Over. html 24


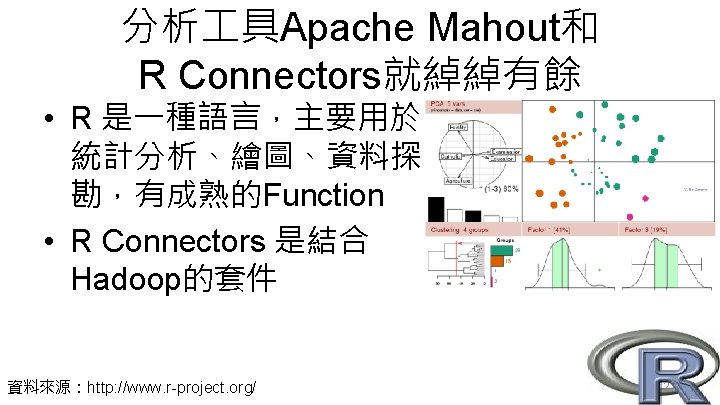
分析 具Apache Mahout和 R Connectors就綽綽有餘 • • 分類 分群 推薦 降維 Classification Examples Regression Clustering Non-MR Algorithms Evolution Dimension Reduction Freq. Pattern Mining Recommenders Vector Similarity 26

- Slides: 28