Hadoop Map Reduce Hadoop Map Reduce Hadoop Map





 • 預設使用FIFO scheduler依序執行Job • Fair scheduler – 多使用者排程策略 • Give")

 • Map Task在產生中間資料之前可先進行 Combine • 省下部分數據資料傳輸的頻寬需求 • 加快寫入硬碟 • 節省硬碟空間")











 編輯Word. Count. java的程式 • 可從網址下載檔案 http: //trac. nche. org. tw/cloud/attachment/wiki/j")
 import java. io. IOException; import java. util. *; import org. apache. hadoop.")
 public static class Reduce extends Map. Reduce. Base implements Reducer<Text, Int. Writable,")
![Word. Count範例程式(3/3) public static void main(String[] args) throws Exception { Job. Conf conf =](https://slidetodoc.com/presentation_image/3f3db0be19efbcca26f875a8ac3a15c9/image-24.jpg "Word. Count範例程式(3/3) public static void main(String[] args) throws Exception { Job. Conf conf =")
將Word. Count. java封裝及編譯成 Word. Count. jar 步驟: mkdir My. Java javac")
 查看執行結果: bin/hadoop dfs -cat output/part-00000 結果如下: bye 2 hadoop 2")
- Slides: 26
Hadoop Map. Reduce
Hadoop Map. Reduce • Hadoop Map. Reduce is a software framework for easily writing applications to process vast amounts of data in HDFS. – 提供高度的可靠性運算 – 提供容錯機制 – 降低網路傳輸的頻寬需求 – 提供負載平衡
Job 排程 (Job Scheduling) • 預設使用FIFO scheduler依序執行Job • Fair scheduler – 多使用者排程策略 • Give every user a fair share of the cluster capacity over time. As more jobs are submitted, free task slots are given to the jobs in such a way as to give each user a fair share of the cluster. – 支援搶占 (preemption) 機制 – If a pool has not received its fair share for a certain period of time, then the scheduler will kill tasks in pools running over capacity in order to give the slots to the pool running under capacity 6
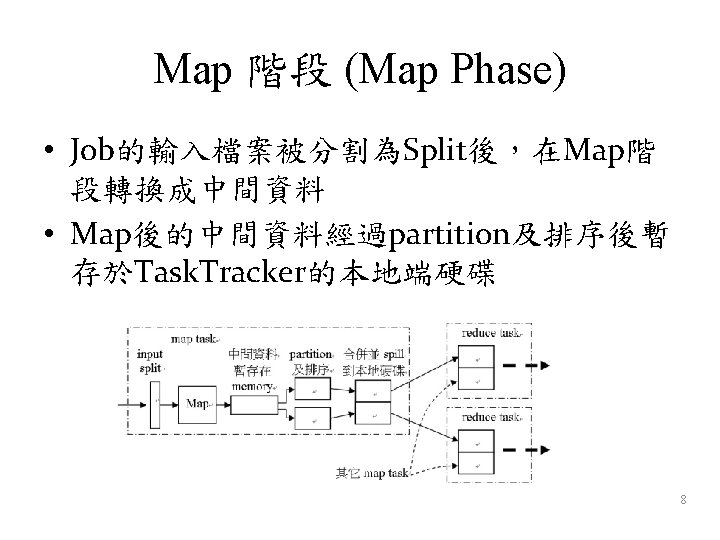
Combine 階段 (Combine Phase) • Map Task在產生中間資料之前可先進行 Combine • 省下部分數據資料傳輸的頻寬需求 • 加快寫入硬碟 • 節省硬碟空間 Map Task 1 (12, 30) (12, 15) (12, 19) Combine 1 (12, 30) Map Task 2 (12, 22) (12, 18) (12, 9) Combine 2 (12, 22) Reduce. Task (12, [30, 15, 19, 22, 18, (12, [30, 22]) 9
Map. Reduce 運作流程 11
Divide and Conquer Divide Job Conquer combine Map Task Reduce Task Map Task Reduce Tasks can more than Map Tasks Final Result
Architecture Map tasks and Reduce tasks are the HDFS Clients JT TT TT NN DN DN TT TT TT DN DN DN Cluster JT: Job. Tracker DN: Task. Tracker NN: Name. Node DN: Data. Node
Work Flow • A Map. Reduce job usually splits the input dataset into independent chunks • The chunks are processed by the map tasks • The framework shuffles the outputs of the maps, and then input to the reduce tasks • The reduce tasks combine the outputs of maps, and store the final output to file system
HDFS Input splitting Chunks Map Native File System Output of Map Shuffle Reduce Output Input of Reduce
hadoop running java programes in cluster - 跑JAVA簡單的程式在 Hadoop叢集安裝 17
Word. Count Example
Word. Count範例程式 • 步驟: mkdir input cd input echo "hello world bye world" > file 1. txt echo "hello hadoop bye hadoop" > file 2. txt cd /opt/hadoop bin/hadoop dfs -copy. From. Local ~/input bin/hadoop dfs -ls input 20
Word. Count範例程式 • (二) 編輯Word. Count. java的程式 • 可從網址下載檔案 http: //trac. nche. org. tw/cloud/attachment/wiki/j azz/Hadoop_Lab 6/Word. Count. java? format=ra w 21
Word. Count範例程式(1/3) import java. io. IOException; import java. util. *; import org. apache. hadoop. fs. Path; import org. apache. hadoop. conf. *; import org. apache. hadoop. io. *; import org. apache. hadoop. mapred. *; import org. apache. hadoop. util. *; public class Word. Count { public static class Map extends Map. Reduce. Base implements Mapper<Long. Writable, Text, Int. Writable> { private final static Int. Writable one = new Int. Writable(1); private Text word = new Text(); public void map(Long. Writable key, Text value, Output. Collector<Text, Int. Writable> output, Reporter reporter) throws IOException { String line = value. to. String(); String. Tokenizer tokenizer = new String. Tokenizer(line); while (tokenizer. has. More. Tokens()) { word. set(tokenizer. next. Token()); output. collect(word, one); } 22 }
Word. Count範例程式(2/3) public static class Reduce extends Map. Reduce. Base implements Reducer<Text, Int. Writable, Text, Int. Writable> { public void reduce(Text key, Iterator<Int. Writable> values, Output. Collector<Text, Int. Writable> output, Reporter reporter) throws IOException { int sum = 0; while (values. has. Next()) { sum += values. next(). get(); } output. collect(key, new Int. Writable(sum)); } } 23
Word. Count範例程式(3/3) public static void main(String[] args) throws Exception { Job. Conf conf = new Job. Conf(Word. Count. class); conf. set. Job. Name("wordcount"); conf. set. Output. Key. Class(Text. class); conf. set. Output. Value. Class(Int. Writable. class); conf. set. Mapper. Class(Map. class); conf. set. Combiner. Class(Reduce. class); conf. set. Reducer. Class(Reduce. class); conf. set. Input. Format(Text. Input. Format. class); conf. set. Output. Format(Text. Output. Format. class); File. Input. Format. set. Input. Paths(conf, new Path(args[0])); File. Output. Format. set. Output. Path(conf, new Path(args[1])); Job. Client. run. Job(conf); } } 24
Word. Count範例程式 • (三)將Word. Count. java封裝及編譯成 Word. Count. jar 步驟: mkdir My. Java javac -classpath hadoop-*-core. jar -d My. Java Word. Count. java jar -cvf wordcount. jar -C My. Java. bin/hadoop jar wordcount. jar Word. Count Input/ Output/ 25
Word. Count範例程式 • (四) 查看執行結果: bin/hadoop dfs -cat output/part-00000 結果如下: bye 2 hadoop 2 hello 2 world 2 參考: http: //www. slideshare. net/waue/hadoop-map-reduce-3019713 26