HDFS Tutorial HADOOP hadoop HADOOP hadoop fs ls








 $ gunzip -c access_log. gz | hadoop fs")
 $ hadoop fs –mkdir testlog $ gunzip -c")



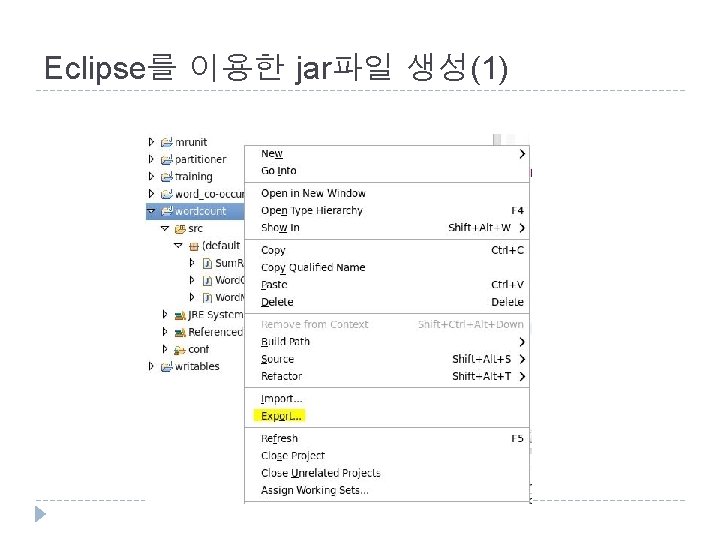
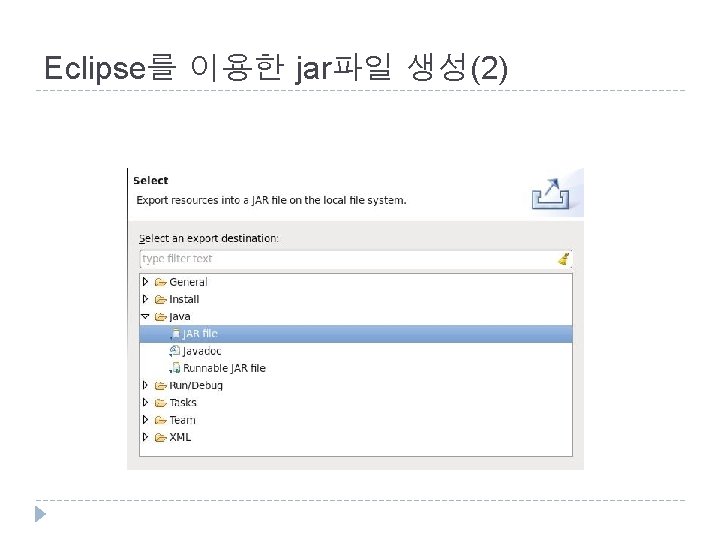
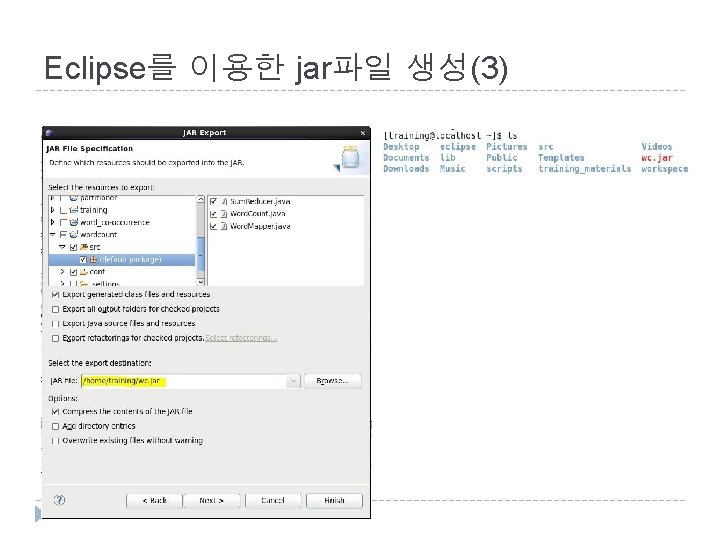




")
")
 http: //localhost: 50030")
 http: //localhost: 50030")
")
")
- Slides: 26
HDFS Tutorial
HADOOP 실행 커맨드 $ hadoop
HADOOP 실행 커맨드 $ hadoop fs
ls 명령어 $ hadoop fs –ls /
Sample Data 압축 해제 $ cd ~/training_materials/developer/data $ tar zxvf shakespeare. tar. gz
Local에서 HDFS로 data 복사 $ hadoop fs -put shakespeare /user/training/shakespeare
HDFS Architecture
HDFS에 디렉토리 생성 $ hadoop fs –mkdir weblog
파이프를 통해 stdout의 출력을 HDFS에 저장(stdin) $ gunzip -c access_log. gz | hadoop fs -put - weblog/access_log
파이프를 통해 stdout의 출력을 HDFS에 저장(stdin) $ hadoop fs –mkdir testlog $ gunzip -c access_log. gz | head -n 5000 | hadoop fs –put - testlog/test_access_log
HDFS의 파일 삭제 $ hadoop fs -ls shakespeare $ hadoop fs –rm shakespeare/glossary
HDFS의 파일 내용 확인 $ hadoop fs -cat shakespeare/histories | tail -n 50
HDFS에서 Local로 파일 복사 $ hadoop fs -get shakespeare/poems ~/shakepoems. txt
Wordcount 예제 실행 $hadoop jar wc. jar Word. Count shakespeare wordcounts
Map. Reduce의 Job Flow
HDFS상의 실행 결과 확인 $hadoop fs –ls wordcounts $hadoop fs –cat wordcounts/part-r-0000 | tail –n 20
Name. Node의 웹 인터페이스 http: //localhost: 50070
Filesystem Browsing을 통해 output 확인(1)
Filesystem Browsing을 통해 output 확인(2)
Jobtracker의 웹 인터페이스(1) http: //localhost: 50030
Jobtracker의 웹 인터페이스(2) http: //localhost: 50030
Jobtracker의 웹 인터페이스에서 jobid를 통해 job status 확인(1)
Jobtracker의 웹 인터페이스에서 jobid를 통해 job status 확인(2)