CUDA Lenovo Confidential 2010 Lenovo GPGPUCUDA CUDA Lenovo





 Lenovo Confidential | © 2010 Lenovo")

 CUDA有效结合CPU+GPU编程 • 串行部分在CPU上运行 • 并行部分在GPU上运行 CPU Serial Code GPU")
 (a) FFT")
 (a) (b) (c)")

 { for (d")



 – GRAPPA 自动校准 – 加速网格化 – 快速重建 Stone, UIUC •")

 – GROMACS (alpha release) –")






 A fully pipelined, single-issue, inorder microprocessor • 2 ALUs and a FPU")
 An array of SPs • 8 streaming processor • 2 Special Function")
 • 并行部分在GPU上运行(device) CPU Serial Code (host) GPU Parallel Kernel (device)")
![C扩展 • Declspecs – global, device, shared, local, constant __device__ float filter[N]; __global__ void](https://slidetodoc.com/presentation_image_h2/8de1038f6e75c97d27516681fc38ce18/image-32.jpg "C扩展 • Declspecs – global, device, shared, local, constant __device__ float filter[N]; __global__ void")
![CUDA程序的编译 • 使用nvcc编译 具 nvcc <filename>. cu [-o excutable] • 调试选项:-g(debug)、-deviceemu(CPU模拟GPU) Lenovo Confidential |](https://slidetodoc.com/presentation_image_h2/8de1038f6e75c97d27516681fc38ce18/image-33.jpg "CUDA程序的编译 • 使用nvcc编译 具 nvcc <filename>. cu [-o excutable] • 调试选项:-g(debug)、-deviceemu(CPU模拟GPU) Lenovo Confidential |")



 – 通过IDs确定处理的数据 • 线程可划分为不同的Block – 在同一个block中,可以通过share memory、atomic operation和")
 { for")
; – Barrier synchronization – 同步thread block之内的所有线程 – 避免访问共享内存时发生RAW/WAR/WAW 冒险 __shared__")

 – 分配显存中的global memory – 两个参数 • 对象数组指针 •")



; –")
 device __global__")

; dim 3 Dim. Grid(100,")

 host in double precision void")
 {")


 Nd k WIDTH for (int k = 0; k < Width; ++k) {")











; dim 3 dim.")

*width+m*TILE_WIDTH+tx N矩阵: 2 tx 0 1 2 TILE_WIDTH-1 m TILE_WIDTH bx (m*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx WIDTH")
![将数据读入Shared Memory并计算sub-sum __shared__ float Mds[TILE_WIDTH]; __shared__ float Nds[TILE_WIDTH]; Mds[ty][tx] = Md[(by*TILE_WIDTH+ty)*width+m*TILE_WIDTH+tx]; Nds[ty][tx] = Nd[(m*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx];](https://slidetodoc.com/presentation_image_h2/8de1038f6e75c97d27516681fc38ce18/image-74.jpg "将数据读入Shared Memory并计算sub-sum __shared__ float Mds[TILE_WIDTH]; __shared__ float Nds[TILE_WIDTH]; Mds[ty][tx] = Md[(by*TILE_WIDTH+ty)*width+m*TILE_WIDTH+tx]; Nds[ty][tx] = Nd[(m*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx];")
![将结果写回P矩阵 Pd[(by*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx] = Pvalue; 大约能达到峰值性能的15% Lenovo Confidential | © 2010 Lenovo](https://slidetodoc.com/presentation_image_h2/8de1038f6e75c97d27516681fc38ce18/image-75.jpg "将结果写回P矩阵 Pd[(by*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx] = Pvalue; 大约能达到峰值性能的15% Lenovo Confidential | © 2010 Lenovo")

- Slides: 76
CUDA程序设计 Lenovo Confidential | © 2010 Lenovo
主要内容 • GPGPU及CUDA介绍 • CUDA编程模型 • 多线程及存储器硬件 Lenovo Confidential | © 2010 Lenovo
GPGPU及CUDA介绍 Lenovo Confidential | © 2010 Lenovo
GPGPU (General Purpose Computing on GPU) Lenovo Confidential | © 2010 Lenovo
CUDA (Compute Unified Device Architecture) CUDA有效结合CPU+GPU编程 • 串行部分在CPU上运行 • 并行部分在GPU上运行 CPU Serial Code GPU Parallel Kernel. A<<< n. Blk, n. Tid >>>(args); Grid 0. . . CPU Serial Code GPU Parallel Kernel. B<<< n. Blk, n. Tid >>>(args); Lenovo Confidential | © 2010 Lenovo Grid 1. . .
CUDA极大提高了现有应用的效果 MRI Reconstruction Cartesian Scan Data Spiral Scan Data Gridding 1 (b) (a) FFT (c) Iterative Reconstructi Spiral scan data + Gridding + FFT on Reconstruction requires little computation Based on Fig 1 of Lustig et al, Fast Spiral Fourier Transform for Iterative MR Image Reconstruction, IEEE Int’l Symp. on Biomedical Imaging, 2004 Lenovo Confidential | © 2010 Lenovo
Advanced MRI Reconstruction Cartesian Scan Data Spiral Scan Data Gridding (b) (a) (b) (c) Iterative Reconstructi on Spiral scan data + Iterative recon FFT Reconstruction requires a lot of computation Lenovo Confidential | © 2010 Lenovo
Advanced MRI Reconstruction Compute Q Acquire Data More than 99. 5% of time Compute F Hd • Q只和扫描参数有关 • FHd是数据相关的 • 使用线性求解器计算ρ Find ρ Haldar, et al, “Anatomically-constrained reconstruction from noisy data, ” MR in Medicine. Lenovo Confidential | © 2010 Lenovo
Code CPU for (p = 0; p < num. P; p++) { for (d = 0; d < num. D; d++) { exp = 2*PI*(kx[d] * x[p] + ky[d] * y[p] + kz[d] * z[p]); c. Arg = cos(exp); s. Arg = sin(exp); r. Fh. D[p] += r. Rho[d]*c. Arg – i. Rho[d]*s. Arg; i. Fh. D[p] += i. Rho[d]*c. Arg + r. Rho[d]*s. Arg; } } GPU __global__ void cmp. Fh. D(float* gx, gy, gz, gr. Fh. D, gi. Fh. D) { int p = block. Idx. x * THREADS_PB + thread. Idx. x; // register allocate image-space inputs & outputs x = gx[p]; y = gy[p]; z = gz[p]; r. Fh. D = gr. Fh. D[p]; i. Fh. D = gi. Fh. D[p]; for (int d = 0; d < SCAN_PTS_PER_TILE; d++) { // s (scan data) is held in constant memory float exp = 2 * PI * (s[d]. kx * x + s[d]. ky * y + s[d]. kz * z); c. Arg = cos(exp); s. Arg = sin(exp); r. Fh. D += s[d]. r. Rho*c. Arg – s[d]. i. Rho*s. Arg; i. Fh. D += s[d]. i. Rho*c. Arg + s[d]. r. Rho*s. Arg; } gr. Fh. D[p] = r. Fh. D; gi. Fh. D[p] = i. Fh. D; } Lenovo Confidential | © 2010 Lenovo
性能提升情况 S. S. Stone, et al, “Accelerating Advanced MRI Reconstruction using GPUs, ” ACM Computing Frontier Conference 2008, Italy, May 2008. Lenovo Confidential | © 2010 Lenovo
计算结果对比 Lenovo Confidential | © 2010 Lenovo
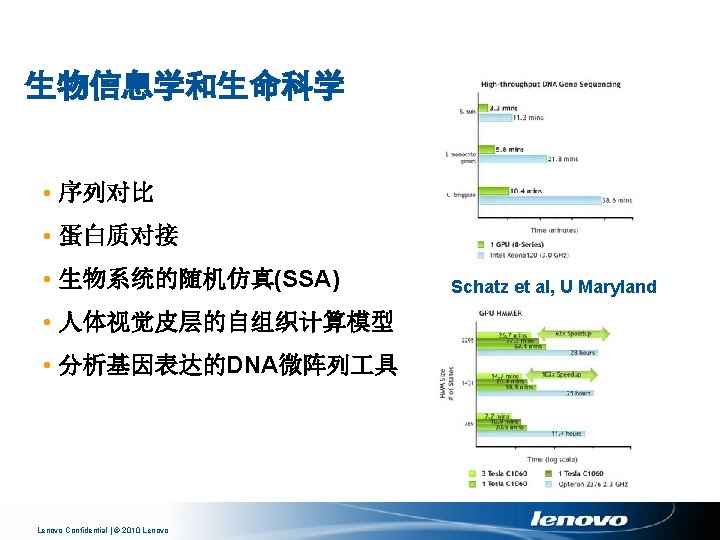
医疗成像 • MRI (磁共振成像) – GRAPPA 自动校准 – 加速网格化 – 快速重建 Stone, UIUC • Computed Tomography (CT) – GE – Digisens Snap. CT Batenburg, Sijbers et al Lenovo Confidential | © 2010 Lenovo
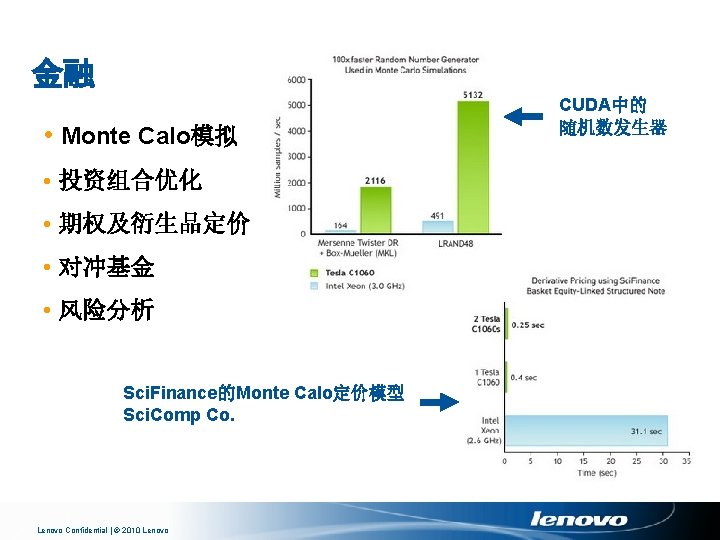
量子化学 双电子积分 K Yasuda, Nagoya U, Japan Lenovo Confidential | © 2010 Lenovo RI-MP 2 correlation energy in Q-Chem 3. 1 Leslie Vogt, Harvard
分子动力学 • 现有的分子动力学软件 – NAMD / VMD (alpha release) – GROMACS (alpha release) – HOOMD • Open. MM: 分子建模 – https: //simtk. org/home/openmm Lenovo Confidential | © 2010 Lenovo
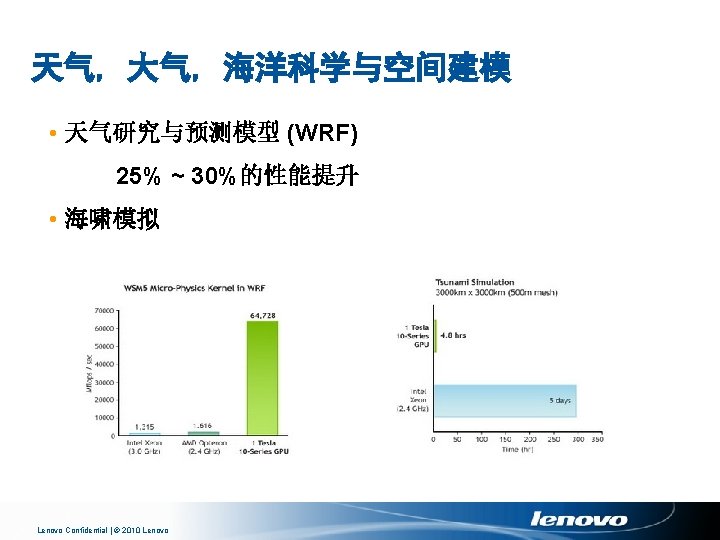
流体动力学 • 3 D Lattice-Boltzman解算器 • 基于Lattice-Boltzman的PDE解算器 • 用于照明的Lattice Boltzman Thibault and Senocak • Navier-Stokes解算器 • 等离子体湍流建模 Tolke and Krafczy Lenovo Confidential | © 2010 Lenovo
电磁学和电磁力学 • GPMAD: 离子束动力学模拟 • FDTD法进行的光散射模拟 • Acceleware的解算器 FDTD加速 Accelerware Lenovo Confidential | © 2010 Lenovo
加密编码 Lenovo Confidential | © 2010 Lenovo
模式匹配 Lenovo Confidential | © 2010 Lenovo
CUDA编程模型 Lenovo Confidential | © 2010 Lenovo
Streaming Processor(SP) A fully pipelined, single-issue, inorder microprocessor • 2 ALUs and a FPU • Register file • 32 -bit scalar processing • No instruction fetch and scheduling • No cache Lenovo Confidential | © 2010 Lenovo
Streaming Multiprocessor(SM) An array of SPs • 8 streaming processor • 2 Special Function Units (SFU) • A 16 KB read/write shared memory – Not a cache – But a software-managed data store • Multithreading issuing unit • Instruction and constant cache Lenovo Confidential | © 2010 Lenovo
CUDA 程序基本结构 • 串行部分在CPU上运行(host) • 并行部分在GPU上运行(device) CPU Serial Code (host) GPU Parallel Kernel (device) Kernel. A<<< n. Blk, n. Tid >>>(args); Grid 0. . . CPU Serial Code (host) GPU Parallel Kernel(device) Kernel. B<<< n. Blk, n. Tid >>>(args); Lenovo Confidential | © 2010 Lenovo Grid 1. . .
C扩展 • Declspecs – global, device, shared, local, constant __device__ float filter[N]; __global__ void convolve (float *image) __shared__ float region[M]; . . . • Keywords region[thread. Idx] = image[i]; – thread. Idx, block. Idx __syncthreads(). . . • Intrinsics – __syncthreads • Runtime API – Memory, symbol, execution management • Function launch Lenovo Confidential | © 2010 Lenovo image[j] = result; } // Allocate GPU memory void *myimage = cuda. Malloc(bytes) // 100 blocks, 10 threads per block convolve<<<100, 10>>> (myimage); {
CUDA程序的编译 • 使用nvcc编译 具 nvcc <filename>. cu [-o excutable] • 调试选项:-g(debug)、-deviceemu(CPU模拟GPU) Lenovo Confidential | © 2010 Lenovo
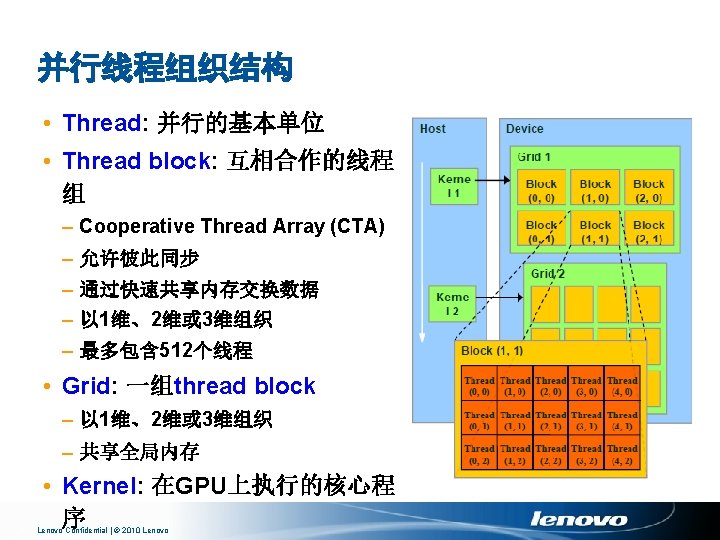
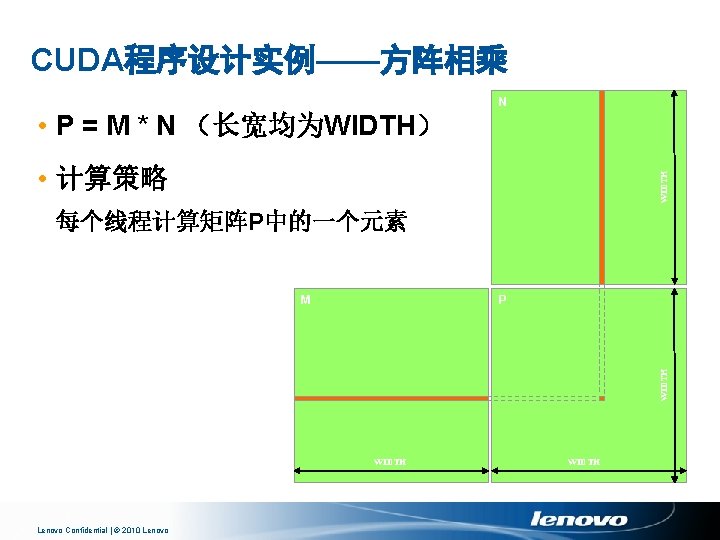
并行线程组织 并行性的维度 • 一维 y=a+b • 二维 P=M N • 三维 CT or MRI Lenovo Confidential | © 2010 Lenovo
线程层次 Lenovo Confidential | © 2010 Lenovo
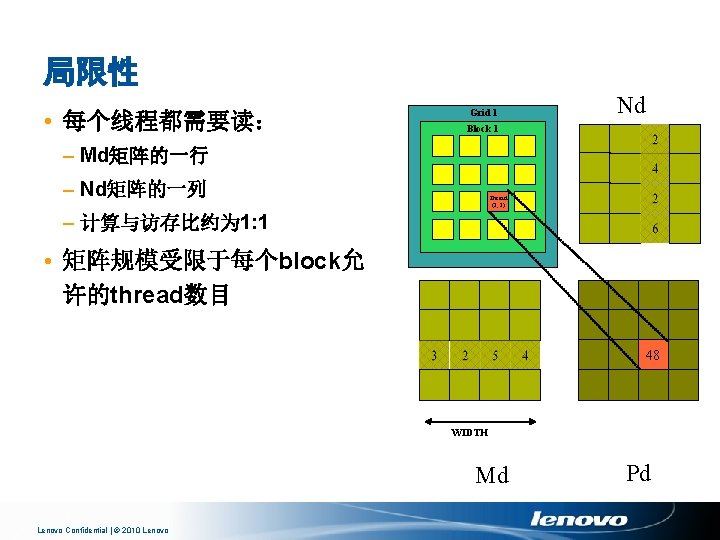
Block and Thread IDs Blocks 和 Threads 具有IDs • thread. Idx, block. Idx • Block ID: 1 D or 2 D • Thread ID: 1 D, 2 D or 3 D • 由此决定相应处理数据 Lenovo Confidential | © 2010 Lenovo
CUDA线程组织 • CUDA kernel函数由一系列线程组成 – 单指令多数据流(SPMD) – 通过IDs确定处理的数据 • 线程可划分为不同的Block – 在同一个block中,可以通过share memory、atomic operation和 barrier synchronization进行协同 Thread Block 1 Thread Block 0 thread. ID 0 1 2 3 4 5 6 … float x = input[thread. ID]; float y = func(x); output[thread. ID] = y; … Lenovo Confidential | © 2010 Lenovo 7 0 1 2 3 4 5 6 … float x = input[thread. ID]; float y = func(x); output[thread. ID] = y; … Thread Block N - 1 7 0 … 1 2 3 4 5 6 … float x = input[thread. ID]; float y = func(x); output[thread. ID] = y; … 7
一个简单的例子——Increment Array Elements //CPU program void inc_cpu(float *a, float b, int N) { for (intidx = 0; idx<N; idx++) a[idx] = a[idx] + b; } //CUDA program __global__ void inc_gpu(float *a, float b, int N) { intidx =block. Idx. x* block. Dim. x+ thread. Idx. x; if (idx < N) a[idx] = a[idx] + b; } void main() { … inc_cpu(a, b, N); } void main() { … dim 3 dim. Block (blocksize); dim 3 dim. Grid( ceil( N / (float)blocksize) ); inc_gpu<<<dim. Grid, dim. Block>>>(a, b, Lenovo Confidential | © 2010 Lenovo
CUDA线程的同步 • void __syncthreads(); – Barrier synchronization – 同步thread block之内的所有线程 – 避免访问共享内存时发生RAW/WAR/WAW 冒险 __shared__ float scratch[256]; scratch[thread. ID] = begin[thread. ID]; __syncthreads(); int left = scratch[thread. ID -1]; 在此等待,直至所有�程到达 才开始�行下面的代� Lenovo Confidential | © 2010 Lenovo
存储器模型与内存分配 • R/W per-thread registers – 1 -cycle latency • R/W per-thread local memory – Slow – register spilling to global memory • R/W per-block shared memory – 1 -cycle latency – But bank conflicts may drag down • R/W per-grid global memory – ~500 -cycle latency – But coalescing accessing could hide latency • Read only per-grid constant and texture memories – ~500 -cycle latency – But cached Lenovo Confidential | © 2010 Lenovo
GPU Global Memory分配 • cuda. Malloc() – 分配显存中的global memory – 两个参数 • 对象数组指针 • 数组尺寸 • cuda. Free() – 释放显存中的global memory – 一个参数 • 对象数组指针 Lenovo Confidential | © 2010 Lenovo
GPU Global Memory分配 代码实例 • 分配64 64单精度浮点数组 • 数组指针Md • 建议用“d”表示GPU显存数据结构 int BLOCK_SIZE = 64; float* Md; int size = BLOCK_SIZE * sizeof(float); cuda. Malloc((void**)&Md, size); cuda. Free(Md); Lenovo Confidential | © 2010 Lenovo
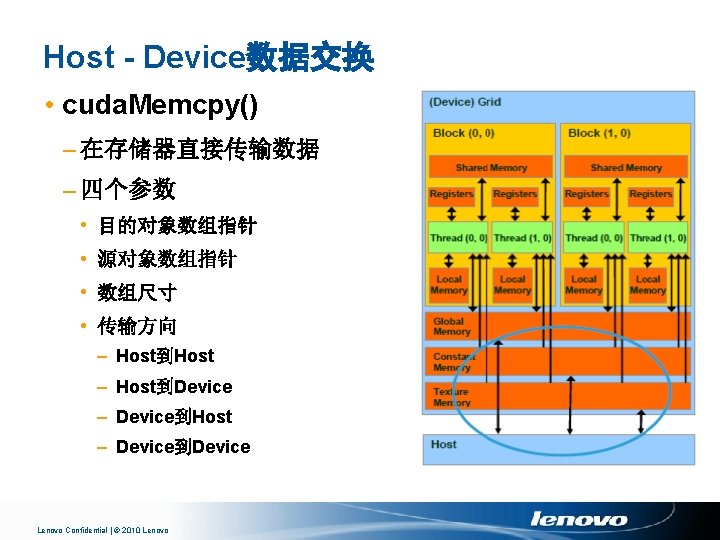
Host - Device数据交换 代码实例 • M. elements: CPU主存 • Md: GPU显存 • 符号常数: cuda. Memcpy. Host. To. Device和cuda. Memcpy. Device. To. Host cuda. Memcpy(Md, M. elements, size, cuda. Memcpy. Host. To. Device); cuda. Memcpy(M. elements, Md, size, cuda. Memcpy. Device. To. Host); Lenovo Confidential | © 2010 Lenovo
Built-in dim 3 Type • 定义grid和thread block的组织 – dim 3 dim. Grid(2, 2); – dim 3 dim. Block(4, 2, 2); – kernel. Function<<< dim. Grid, dim. Block>>>(…); Lenovo Confidential | © 2010 Lenovo
CUDA函数定义 Executed on the: Only callable from the: __device__ float Device. Func() device __global__ void Kernel. Func() device host __host__ float Host. Func() host • __global__定义kernel函数 – 必须返回void • __device__和__host__ 可以组合使用 – 则被定义的函数在CPU和GPU上都被编译 Lenovo Confidential | © 2010 Lenovo
Kernel函数调用 • 调用时必须给出线程配置方式 __global__ void Kernel. Func(. . . ); dim 3 Dim. Grid(100, 50); // 5000 thread blocks dim 3 Dim. Block(4, 8, 8); // 256 threads per block size_t Shared. Mem. Bytes = 64; // 64 bytes of shared memory Kernel. Func<<< Dim. Grid, Dim. Block, Shared. Mem. Bytes >>>(. . . ); Lenovo Confidential | © 2010 Lenovo
CUDA数学函数 • pow, sqrt, cbrt, hypot, exp 2, expm 1, log 2, log 10, log 1 p, sin, cos, tan, asin, acos, atan 2, sinh, cosh, tanh, asinh, acosh, atanh, ceil, floor, trunc, round, etc. – 只支持标量运算 – 许多函数有一个快速、较不精确的对应版本 • 以“__”为前缀,如__sin() • 编译开关-use_fast_math强制生成该版本的目标码 • 每个多处理器包含两个超越函数计算单元 Lenovo Confidential | © 2010 Lenovo
第一步:CPU实现 k WIDTH // Matrix multiplication on the (CPU) host in double precision void Matrix. Mul. On. Host(float* M, float* N, float* P, int Width) { N for (int i = 0; i < Width; ++i) for (int j = 0; j < Width; ++j) { double sum = 0; for (int k = 0; k < Width; ++k) { j double a = M[i * width + k]; double b = N[k * width + j]; sum += a * b; } P[i * Width + j] = sum; } M P } WIDTH i k WIDTH Lenovo Confidential | © 2010 Lenovo WIDTH
第二步:将矩阵数据传给显存 void Matrix. Mul. On. Device(float* M, float* N, float* P, int Width) { int size = Width * sizeof(float); float* Md, Nd, Pd; … 1. // Allocate and Load M, N to device memory cuda. Malloc(&Md, size); cuda. Memcpy(Md, M, size, cuda. Memcpy. Host. To. Device); cuda. Malloc(&Nd, size); cuda. Memcpy(Nd, N, size, cuda. Memcpy. Host. To. Device); // Allocate P on the device cuda. Malloc(&Pd, size); Lenovo Confidential | © 2010 Lenovo
第三步:将计算结果传回内存 2. // Kernel invocation code – to be shown later … 3. // Read P from the device cuda. Memcpy(P, Pd, size, cuda. Memcpy. Device. To. Host); // Free device matrices cuda. Free(Md); cuda. Free(Nd); cuda. Free (Pd); } Lenovo Confidential | © 2010 Lenovo
第四步:kernel函数 // Matrix multiplication kernel – per thread code __global__ void Matrix. Mul. Kernel(float* Md, float* Nd, float* Pd, int Width) { // 2 D Thread ID int tx = thread. Idx. x; int ty = thread. Idx. y; // Pvalue is used to store the element of the matrix // that is computed by the thread float Pvalue = 0; Lenovo Confidential | © 2010 Lenovo
第四步:kernel函数(续) Nd k WIDTH for (int k = 0; k < Width; ++k) { float Melement = Md[ty * Width + k]; float Nelement = Nd[k * Width + tx]; Pvalue += Melement * Nelement; } Pd[ty * Width + tx] = Pvalue; tx } Md Pd ty tx k WIDTH Lenovo Confidential | © 2010 Lenovo WIDTH ty WIDTH
第五步:调用kernel函数 2. // Kernel invocation code // Setup the execution configuration dim 3 dim. Block(Width, Width); dim 3 dim. Grid(1, 1); // Launch the device computation threads! Matrix. Mul. Kernel<<<dim. Grid, dim. Block>>>(Md, Nd, Pd); Lenovo Confidential | © 2010 Lenovo
参考资料——CUDA SDK • SDK中包含许多CUDA范例 Lenovo Confidential | © 2010 Lenovo
多线程及存储器硬件 Lenovo Confidential | © 2010 Lenovo
Streaming Multiprocessor执行Thread Blocks • 线程以block为单位分配到SM – 视资源需求, 一个SM分配至多 8个block – SM in G 80可以接受 768个线程 • 256 (threads/block) * 3 blocks • 128 (threads/block) * 6 blocks, etc • 线程并发运行 – SM分配并维护线程ID – SM管理并调度线程 Lenovo Confidential | © 2010 Lenovo
Thread Block Size Considerations • 对于矩阵乘法, 哪个thread block尺寸最好: 8 X 8, 16 X 16或 者32 X 32? – 8 X 8: 64 threads/block. 每个SM至多接受 768 threads, 即 12 blocks。但是, SM至多接受 8 blocks, 所以实际上仅有512 threads – 16 X 16: 256 threads/block. 每个SM至多接受 768 threads, 即 3 blocks → 只要其它计算资源许可,可以满负荷 作 – 32 X 32: 1024 threads/block. SM无法处理 Lenovo Confidential | © 2010 Lenovo
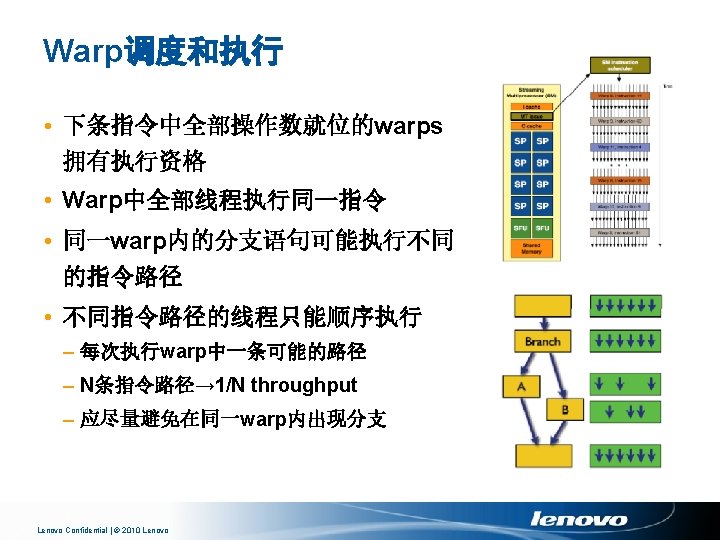
线程调度和执行 • Thread block内部线程组织为 32 -thread warps – An implementation decision - not part of CUDA • Warp是SM调度的基本单位 – Warp就是一条 32路SIMD指令 – Half-warp是warp的前一半或后一半 • 访问存储器的基本单位 Lenovo Confidential | © 2010 Lenovo
SM存储器资源 • Register and local memory: per-thread – 线程私有 – 编译器自行分配 – e. g. float a; • Shared memory: per-block – Block内所有线程共享 – 使数据尽量靠近处理器 – 动态分配到blocks – e. g. __shared__ float region[M]; • Constant cache • Texture cache Lenovo Confidential | © 2010 Lenovo
利用Shared Memory提高性能 • 存储器模型回顾 – R/W per-block shared memory • 1 -cycle latency • But bank conflicts may drag down – R/W per-grid global memory • ~500 -cycle latency • But coalescing accessing could hide latency • 性能优化思路 – Shared Memory比Global Memory快几百倍 – 线程之间通过Shared Memory合作 – 使用一个或少量线程装载和计算thread block 内全部线程共享的数据 Lenovo Confidential | © 2010 Lenovo
bx 0 矩阵乘法的分块计算 1 2 tx • 每个block计算一块小方矩阵Pd TILE_WIDTH Nd TILE_WIDTH • 每个thread读入Pd的一个元素 • 假设M和N的大小是小矩阵大小的整数倍 Md WIDTH 0 1 2 TILE_WIDTH-1 Pd 1 ty Pdsub TILE_WIDTH-1 TILE_WIDTH 2 WIDTH Lenovo Confidential | © 2010 Lenovo WIDTH by 0 1 2 TILE_WIDTHE 0
线程结构配置 // Setup the execution configuration dim 3 dim. Block(TILE_WIDTH, TILE_WIDTH); dim 3 dim. Grid(Width / TILE_WIDTH, Width / TILE_WIDTH); Lenovo Confidential | © 2010 Lenovo
kernel函数代码——整体结构 // Block index int bx = block. Idx. x; int by = block. Idx. y; // Thread index int tx = thread. Idx. x; int ty = thread. Idx. y; // Pvalue stores the element of the block sub-matrix // that is computed by the thread – automatic variable! float Pvalue = 0; // Loop over all the sub-matrices of M and N // required to compute the block sub-matrix for (int m = 0; m < Width/TILE_WIDTH; ++m) { code for calculating the sub-sum; }; Lenovo Confidential | © 2010 Lenovo
bx (by*TILE_WIDTH+ty)*width+m*TILE_WIDTH+tx N矩阵: 2 tx 0 1 2 TILE_WIDTH-1 m TILE_WIDTH bx (m*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx WIDTH 在第m次循环中每个线程需要读取的元素地址为 Nd M矩阵: 1 TILE_WIDTH 地址计算 0 P矩阵: (by*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx by 1 m ty by 0 1 2 Pdsub TILE_WIDTH-1 TILE_WIDTH 2 WIDTH Lenovo Confidential | © 2010 Lenovo WIDTH 0 Pd TILE_WIDTHE Md
将数据读入Shared Memory并计算sub-sum __shared__ float Mds[TILE_WIDTH]; __shared__ float Nds[TILE_WIDTH]; Mds[ty][tx] = Md[(by*TILE_WIDTH+ty)*width+m*TILE_WIDTH+tx]; Nds[ty][tx] = Nd[(m*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx]; __syncthreads(); for (int k = 0; k < TILE_WIDTH; ++k) Pvalue += Mds[ty][k] * Nds[k][tx]; __syncthreads(); Lenovo Confidential | © 2010 Lenovo
将结果写回P矩阵 Pd[(by*TILE_WIDTH+ty)*width+bx*TILE_WIDTH+tx] = Pvalue; 大约能达到峰值性能的15% Lenovo Confidential | © 2010 Lenovo
Thank you! Lenovo Confidential | © 2010 Lenovo