ASSESSMENT OF DATA QUALITY Mirza Muhammad Waqar Contact










 can")
















 index represents the overall accuracy of the")
 * 100% Where � Sd = sum")





 * 100 Where")

 * 100 where")

 Another useful analytical technique is the computation of the kappa coefficient")
 The coefficient (K), first developed by Cohen (1960) for nominal scale")
")


- Slides: 49
ASSESSMENT OF DATA QUALITY Mirza Muhammad Waqar Contact: mirza. waqar@ist. edu. pk +92 -21 -34650765 -79 EXT: 2257 RG 610 Course: Introduction to RS & DIP
Contents 2 Hard vs Soft Classification Supervised Classification � Training Stage Field Truthing Inter class vs Intra Class Variability � Classification Stage Minimum Distance to Mean Classifier Parallelepiped Classifier Maximum Likelihood Classifier � Output Stage Supervised vs Unsupervised Classification
Positional and Attribute Accuracies Positional and attribute accuracies are the most critical factors in determining the quality of geographic data. Can be quantified by sample data (a portion of whole data set) against reference data. The concepts and methods of spatial data quality are applicable to both raster and vector data.
Evaluation of Positional Accuracy Made up of two elements: � Planimetric accuracy, and This is done by comparing the coordinates (x and y) of sample points on maps to the coordinates (x and y) of corresponding reference points. � Height accuracy Involves comparison of elevation values of sample and reference data points.
Reference Data To be used as a sample point, the point must be well defined, which means that it can be unambiguously identified both on the map and on the ground. � Survey monuments � Bench marks � Road intersections � Corner of building � Lampposts � Fire hydrants etc.
Reference Data It is important for both the sample and reference data to be in the same map projection and based on the same datum. The Accuracy Standards for Large-scale Maps however, specifies that: �A minimum of 20 check points must be established throughout the area covered by the map. � These sample points should be spatially distributed in such a way that at least 20% of the points be located in each quadrant of the map. � with individual points spaced at intervals equal to at least 10% of the diagonal of the map sheet.
Standard to take sample Points
Root Mean Square Error The discrepancies between the coordinate values of the sample points and their corresponding reference coordinate values are used to compute the overall accuracy of the map as represented by the root mean-square error (RMSE) The RMSE is defined as the square root of the average of the squared discrepancies. The RMSE for discrepancies in the X coordinate direction (rmsx) Y coordinate direction (rmsy) and elevation (rmst ) are computed from:
RMS for discrepancies Where dx = discrepancies in X coordinate direction = X reference – X sample
RMS for discrepancies dy = discrepancies in Y coordinate direction = Yreference – Ysample e = discrepancies in elevation = E reference – E sample n = total number of points checked (sampled)
RMS for discrepancies From rmsx and rmsy, a single RMSE of planimetry (rmsp) can be computed as follows.
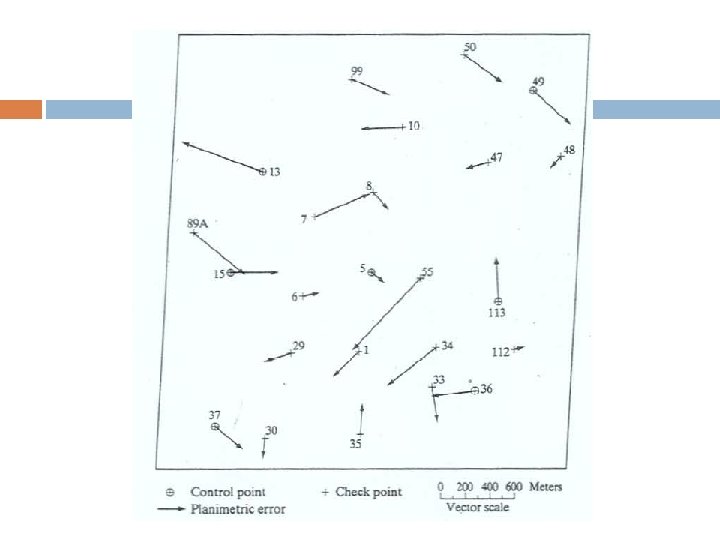
RMS as Overall Accuracy The RMSEs of planimetry and elevation have now been generally accepted as the overall accuracy of the map. RMSE is used as the index to check against specific standards to determine the fitness for use of the map. The major drawback of the RMSE is that it provides information of only the overall accuracy. It does not give any indication of the spatial variation of the errors.
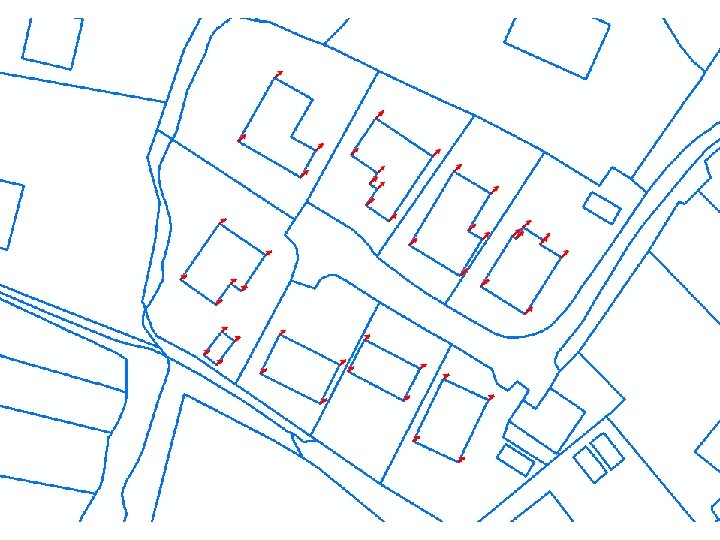
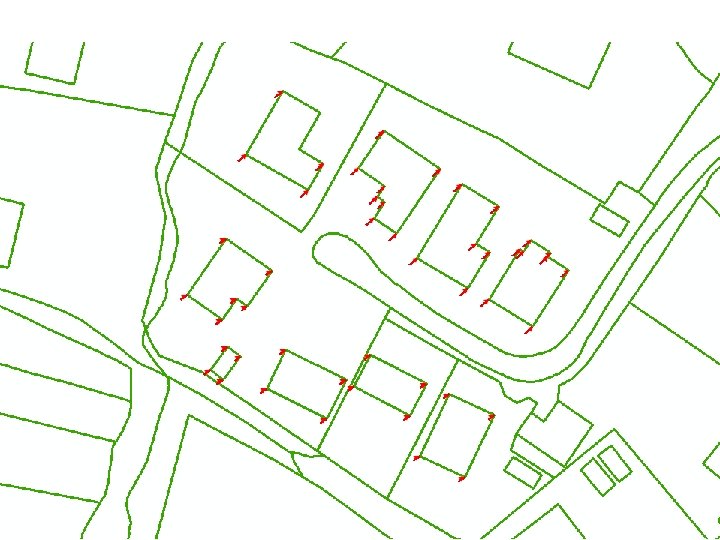
RMS as Overall Accuracy For users who require such information, a map showing the positional discrepancies at the sample points can be generated. Separate maps can be generated discrepancies in easting and northing. for Alternatively a map showing the vectors of discrepancies at each point can be plotted
Evaluation of Attribute Accuracy Attribute accuracy is obtained by comparing values of sample spatial data units with reference data obtained either by field checks or from sources of data with a higher degree of accuracy. These sample spatial units can be raster cells; raster image pixels; or sample points, lines, and polygons.
Error Matrix An error matrix is constructed to show the frequency of discrepancies between encoded values (i. e. , data values on a map or in a database) and their corresponding actual or reference values for a sample of locations. The error matrix has been widely used as a method for assessing classification accuracy of remotely sensed images
Error/Confusion Matrix An error matrix, also known as classification error matrix or confusion matrix, is a square array of values, which cross-tabulates the number of sample spatial data units assigned to a particular category relative to the actual category as verified by the reference data.
Error Matrix Conventionally, the rows of the error matrix represent the categories of the classification of the database, while the columns indicate the classification of the reference data. In the error matrix, the element ij represents the frequency of spatial data units assigned to category i that actually belong to category j.
An Error Matrix Sample Data Reference Data Total A B C D E F A 1 2 0 0 3 B 0 5 0 2 3 0 10 C 0 3 5 1 0 0 9 D 0 0 4 4 0 0 8 E 0 0 4 0 4 F 0 0 0 1 1 Total 1 10 9 7 7 1 35 A = Exposed soil B = Cropland C = Range D = Sparse woodland E = Forest F = water body
Error Matrix The numbers along the diagonal of the error matrix (i. e. when i = j) indicate the frequencies of correctly classified spatial data units in each category; and the off-diagonal numbers (when I j) represent the frequencies of misclassification in the various categories.
Error Matrix The error matrix is an effective way to describe attribute accuracy of geographic data. If in a particular error matrix, all the nonzero entries lie on the diagonal. it indicates that no misclassification at the sample locations has occurred an overall accuracy of 100% is obtained.
Commission or Omission When misclassification occurs, it can be identified either as an error of commission or an error of omission. Any misclassification is simultaneously an error of commission and an error of omission.
Error of Commission and Omission Errors of commission, also known as errors of inclusion, are defined as wrongful inclusion of a sample location in a particular category due to misclassification. When this happens, it means that the sample location is omitted from another category in the reference data, which is an error of omission.
Commission vs Omission Errors of commission are identified by offdiagonal values across the rows. Errors of omission. also known as errors of exclusion, are identified by those off-diagonal values down the columns.
An Error Matrix Sample Data Reference Data Total Error of Commission A B C D E F A 1 2 0 0 3 B 0 5 0 2 3 0 10 C 0 3 5 1 0 0 9 D 0 0 4 4 0 0 8 E 0 0 4 0 4 F 0 0 0 1 1 Total 1 10 9 7 7 1 35 A = Exposed soil B = Cropland C = Range D = Sparse woodland E = Forest F = water body
An Error Matrix Sample Data Reference Data Total A B C D E F A 1 2 0 0 3 B 0 5 0 2 3 0 10 C 0 3 5 1 0 0 9 D 0 0 4 4 0 0 8 E 0 0 4 0 4 F 0 0 0 1 1 Total 1 10 9 7 7 1 35 Error of Omission A = Exposed soil B = Cropland C = Range D = Sparse woodland E = Forest F = water body
Indices to check Accuracy In addition to the interpretation of errors of commission and omission, the error matrix may also be used to compute a series of descriptive indices to quantify the attribute accuracy of the data. These include: � Overall Accuracy � Producer's Accuracy � User's Accuracy
Overall Accuracy The PCC (Percent Correctly Classified) index represents the overall accuracy of the data. In the case of simple random sampling, the PCC is defined as the trace of the error matrix (i. e. , the sum of the diagonal values) divided by n, the total number of sample locations.
Overall Accuracy PCC = (Sd / n) * 100% Where � Sd = sum of values along diagonal � n = total number of sample locations
PCC – Overall Accuracy Sample Data Reference Data Total A B C D E F A 1 2 0 0 3 B 0 5 0 2 3 0 10 C 0 3 5 1 0 0 9 D 0 0 4 4 0 0 8 A = Exposed soil 0 0 4 0 4 B = Cropland. E C = Range F 0 0 0 1 1 D = Sparse woodland 1 10 9 7 7 1 35 E = Forest Total F = water body PCC = (1+5+5+4+4+1) x 100/35 PCC = 20 x 100 / 35 = 57. 1%
Overall Accuracy The maximum value of the PCC index is 100 when there is perfect agreement between the database and the reference data. The minimum value is 0, which indicates no agreement.
Deficiencies in PCC index In the first place, since the sample points are randomly selected, the index is sensitive to the structure of the error matrix. This means that if one category of data dominates the sample (this occurs when the category covers a much larger area than others), the PCC index can be quite high even if the other classes are poorly classified.
Deficiencies in PCC index Second, the computation of the PCC index does not take into account the chance agreements that might occur between sample and reference data. The index therefore always tends to overestimate the accuracy of the data. Third, the PCC index does not differentiate between errors of omission and commission. Indices of these two types of errors are provided by the producer's accuracy and the user's accuracy.
Producer’s Accuracy This is the probability of a sample spatial data unit being correctly classified and is a measure of the error of omission for the particular category to which the sample data belong. The producer's accuracy is so-called because it indicates how accurate the classification is at the time when the data are produced.
Producer’s Accuracy Producer’s accuracy is computed by: Producer’s accuracy = (Ci/Ct) * 100 Where � Ci = Correctly classified sample locations in column � Ct = Total number of sample locations in column � Error of omission = 100 – producer’s accuracy
User’s Accuracy This is the probability that a spatial data unit classified on the map or image actually represents that particular category on the ground. This index of attribute accuracy, which is actually a measure of the error of commission, is of more interest to the user than the producer of the data.
User’s Accuracy User’s accuracy is computed by: User’s accuracy = (Ri/Rt) * 100 where � Rj = correctly classified sample locations in row � Rt = total number of sample locations in row � error of commission = 100 – user's accuracy
An Error Matrix Sampl Reference Data Tota e Data A B C D E F l A 1 2 0 0 3 B 0 5 0 2 3 0 10 C 0 3 5 1 0 0 9 D 0 0 4 4 0 0 8 E 0 0 4 0 4 F 0 0 0 1 10 9 7 7 1 35 Total A = Exposed soil B = Cropland C = Range D = Sparse woodland E = Forest F = water body PCC = (1+5+5+4+4+1) x 100/35 = 57. 1% Producer’s accuracy: A = 1/1 = 100% D = 4/7 = 57. 1% B = 5/10 = 50% E = 4/7 = 57. 1% C = 5/9 = 55. 6% F = 1/1 = 100% User’s Accuracy: A = 1/3 = 33. 3% D = 4/8 = 50% B = 5/10 = 50% E = 4/4 = 100% C = 5/9 = 55. 6% F = 1/1 = 100%
Kappa Coefficient (k) Another useful analytical technique is the computation of the kappa coefficient or Kappa Index of Agreement (KIA) It is capable of controlling the tendency of the PCC index to overestimate by incorporating all the offdiagonal values in its computation The use of the off-diagonal values in the computation of the kappa coefficients also makes them useful for testing the statistical significance of the differences in different error matrices
Kappa Coefficient (k) The coefficient (K), first developed by Cohen (1960) for nominal scale data K = P o – Pc / 1 – P c Po is the proportion of agreement between the reference and sample data (PCC) Kappa coefficient varies from a minimum of 1 to a maximum of 0.
Tau Coefficient Kappa coefficient tends to overestimate the agreement between data sets. Foody (1992) described a modified kappa coefficient based on equal probability of group membership that resembles and is derived more properly from the tau coefficient.
Tau Coefficient = P o – Pr / 1 – P r It was demonstrated that the tau coefficient, which is based on the a priori probabilities of group membership, provides an intuitive and relatively more precise quantitative measure of classification accuracy than the kappa coefficient, which is based on the a posteriori probabilities
Questions & Discussion