Announcements Today Single level index review Multilevel index







 • Now search for non-ordering key: – Average is 1500 block reads")


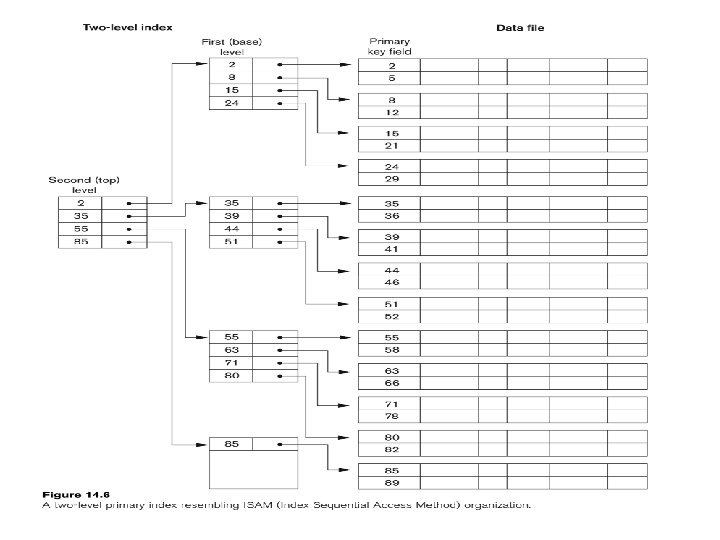
 • Construct multi level index for previous example – Secondary index had")




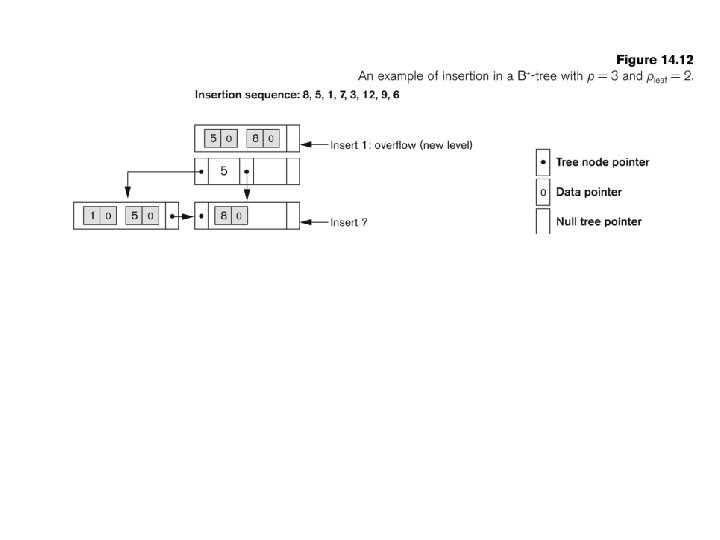
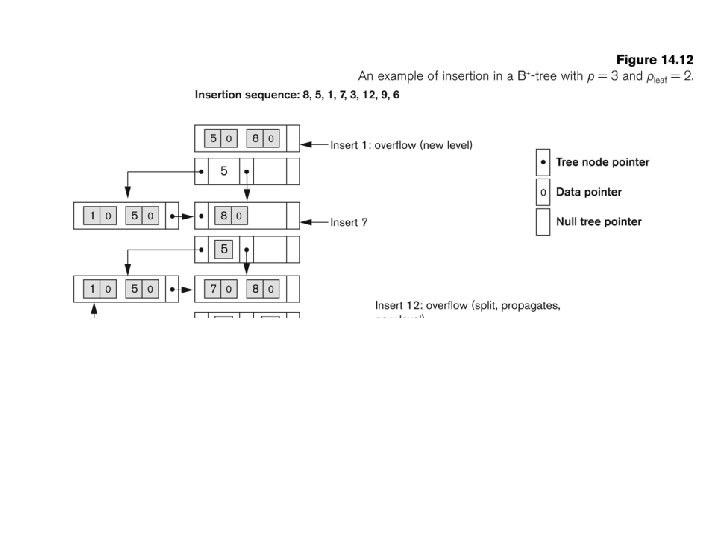
 Find leaf page on which to add entry 2)")

- Slides: 21
Announcements • Today – Single level index review – Multilevel index • Reading assignment: – Chapter 5 and Sections 6. 0 -6. 5
Program 1 post-mortem • I am in the process of grading it • Harshness of auto grading – Does not compile grade = 0 • We will have some way to replace lowest program • Please follow instructions exactly for turning in subsequent assignment
Review of Single Level Indexes
Primary Index • Index contains one index entry / block – Example index entry for a primary index on student # • <student# = 4173, block. ID = 937> The student # of the first record on block 937 is 4137 • Time to access in I/O operations – Without index: log 2 B – With index: log 2 Bidx + 1 The number of blocks in the file The number of blocks in index
Clustered Index • Index contains one entry / unique value of indexing field – Example index entry for clustered index on major • <major = “Comp. Sci”, block. ID = 937> The first block with a record whose major is Comp. Sci has blk. ID=937 • Time to access in I/O operations – Without index: log 2 B – With index: log 2 Bidx + 1 The number of blocks in the file The number of blocks in index
Secondary Indexes • Index contains every RID in the file – There are different ways to implement this – Example index entry for secondary index on major • <major = “Comp. Sci”, block. ID = 2877> Block 2877 (which is part of the index) contains RIDs for records where major is Comp. Sci • Time to access in I/O operations – Without index: B – With index: log 2 Bidx + 1 The number of blocks in the file The number of access the RID list blocks in index containing RID list block pointers
Example 1 and 2 in Chapter 14 • Setting file w/ 30, 000 fixed length records of 100 bytes on 1024 byte blocks – Records / block = 10 – # blocks in file = 3, 000 – Search for key w/o idx: log 2 3000 = about 12 • Make index on 9 byte ordering key, block ID is 6 bytes – 68 index entries / block, 3, 000 total index entries – 45 blocks in the index – Search for key w/ index = 1+log 2 45 = 7 I/Os
Example (continued) • Now search for non-ordering key: – Average is 1500 block reads • Construct secondary key on 9 byte non ordering key field: – Index entry still 15 bytes, 68 entries / block – But we need entry for each of the 30, 000 records • Need 442 blocks for index. – Binary search is log 2 442 = 9 block reads + 1 to get the record is 10.
Multilevel Indexes
Multilevel Indexes • Consider a clustered index on a non-key field • The index itself is an ordered file of (value, block. Ptr) pairs where value is a key field • We can thus construct a primary index on “value” • Add levels until the index fits in one block
Example (continued) • Construct multi level index for previous example – Secondary index had 68 entries / block and required 442 blocks on level 1 – Level two needs ceil(442 / 68) = 7 blocks – Level thee needs ceil(7 / 68) = 1 block – Stop • Search requires 4 block accesses
Inserts / Deletes are Problematic • In general, inserts and deletes to the file requires updating the index • Each level of the index is a physically ordered file thus updates are expensive • One solution: leave some space on each index for inserting new index entries B+ trees
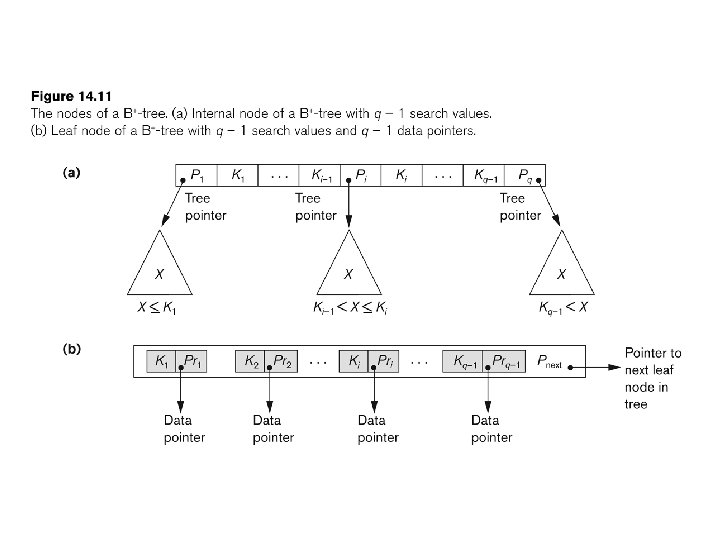
B+ Trees • B+ trees are the most popular implementation of dynamic multilevel indexes • There are two types B+ tree index blocks – Internal nodes: contain index field values (used to guide the search) and pointers blocks in lower levels of the B+ tree (tree pointers) – Leaf nodes: contain values and matching RIDs
Trees
B+ Tree Properties • A B+ tree is always balanced (ie, distance from the root to leaf is the same for each leaf) • Let p be the maximum number of tree pointers on an internal block – Other than root, each internal page has at least ceil(p/2) tree pointers – A block with q tree pointers has q-1 search field values • Key aspect of B+ trees are graceful algorithms for handling insertions and delete
B+ Tree Insert Overview 1) Find leaf page on which to add entry 2) If there is room on leaf page insert and stop 3) If there is no room, overflow