Porzdkowanie liniowe Wprowadzenie Termin statystyczna analiza danych odnosi










 dany jest co najmniej dwuelementowy i skończony zbiór obiektów S; 2) istnieje")






 Następnie obliczamy wartość miary Hellwiga: gdzie di 0 to")
![Metoda Hellwiga (c. d. ) Syntetyczna miara Hellwiga przyjmuje wartości z przedziału [0, 1]](https://slidetodoc.com/presentation_image_h2/2d13b988e55ed5b28de7335966c4cb89/image-20.jpg "Metoda Hellwiga (c. d. ) Syntetyczna miara Hellwiga przyjmuje wartości z przedziału [0, 1]")



- Slides: 23
Porządkowanie liniowe
Wprowadzenie Termin statystyczna analiza danych odnosi się do grupy metod statystycznych, za pomocą których jednoczesnej analizie poddane są obserwacje charakteryzowane przez przynajmniej dwie zmienne. Każdy z obiektów (obserwacji) jest wektorem wartości zmiennych: gdzie xij to wartość j-tej zmiennej dla i-tego obiektu. Dla wszystkich obserwacji daje to w rezultacie macierz danych:
Skale pomiaru wartości cech Cecha to pewna własność obiektów należących do pewnej zbiorowości, wspólna dla wszystkich i przyjmująca wartości z określonego zbioru. Biorąc pod uwagę sposób wyrażania wartości cech, można je podzielić na: • ilościowe (kwantytatywne), • jakościowe (kwalitatywne, opisowe).
Wartościami cech ilościowych są liczby rzeczywiste, uzyskane w wyniku pomiaru i wyrażone w określonych jednostkach (np. zysk w mln. zł) lub liczbami całkowitymi otrzymanymi w wyniku policzenia (np. liczba dzieci w rodzinie). Jeśli chodzi o cechy jakościowe, to ich wartościom przypisywane są różnego rodzaju symbole (np. słowa). Podział ten jest nieprecyzyjny i wywołuje spory. Aby tego uniknąć, cechy dzielimy ze względu na skale pomiaru.
Pomiar to przyporządkowanie liczb charakterystykom obiektów zgodnie z określonymi regułami w taki sposób, aby liczby odzwierciedlały relacje zachodzące między tymi obiektami. W teorii pomiaru wyróżnia się 4 rodzaje skal: • nominalna (skala nazw), gdy pomiędzy wartościami cechy „x” dla dwóch obiektów zachodzi jedna z relacji: • porządkowa, gdy można określić znak różnicy pomiędzy wartościami cechy „x”, tj. zachodzi jedna z relacji:
• przedziałowa, gdy można określić wielkość różnicy pomiędzy wartościami cechy „x” (o ile jednostek), tj. na wartościach cechy dopuszczalne są operacje: >, <, =, , +, -. Wartości przybierane są ze zbioru R. • ilorazowa, gdy można określić krotność różnicy pomiędzy wartościami cechy „x” (ile razy), tj. na wartościach cechy dopuszczalne są operacje: >, <, =, , +, -, ·, /. Wartości przybierane są ze zbioru R+ (zero lewostronnie ogranicza zakres skali). Dwie pierwsze to skale słabe, a dwie ostatnie to skale mocne.
Normalizacja zmiennych Niektóre z metod statystycznych wymagają sprowadzenia zmiennych (mierzonych na skalach przedziałowych lub ilorazowych) do porównywalności poprzez zastosowanie formuł normalizacyjnych. 1. Standaryzacja: 2. Unitaryzacja: 3. Normalizacja na <-1, 1>:
Porządkowanie liniowe Polega na uszeregowaniu obiektów, tj. ustaleniu kolejności obiektów ze względu na wartości więcej niż jednej cechy od „najlepszego” do „najgorszego”. Musi więc istnieć pewne kryterium, ze względu na które będzie można te obiekty uporządkować. Narzędziem metod porządkowania liniowego jest syntetyczny miernik rozwoju (SMR), będący pewną funkcją określoną na zmiennych i wyznaczoną dla każdego obiektu ze zbioru obiektów S.
Gdy dokonujemy porządkowania, cechy dzielimy na 3 grupy ze względu na preferencje: • stymulanty, gdy wyższe wartości tej cechy pozwalają zakwalifikować obiekt jako „lepszy”, tj. x. A > x. B => A > B • destymulanty, gdy wyższe wartości tej cechy pozwalają zakwalifikować obiekt jako „gorszy”, tj. x. A > x. B => A < B • nominanty, których normalny poziom daje „wyższą” pozycje obiektowi, zaś odchylenia od tego poziomu „niższą”. Nominanty są zwykle pomijane w badaniach, ponieważ trudno określić ich nominalny poziom.
Zwykle w badaniach wymaga się, by wszystkie cechy miały charakter stymulant. Destymulanty można wtedy przekształcić w stymulanty za pomocą jednego ze wzorów: lub Dane powinny zostać poddane transformacji normalizacyjnej (najczęściej standaryzacji)!!!
Założenia 1) dany jest co najmniej dwuelementowy i skończony zbiór obiektów S; 2) istnieje pewne syntetyczne kryterium porządkowania elementów zbioru S; 3) dany jest skończony zbiór zmiennych merytorycznie związany z syntetycznym kryterium porządkowania. Zmienne mają charakter preferencyjny, tzn. wyróżnia się wśród nich stymulanty, destymulanty i nominanty; 4) zmienne służące do opisu obiektów są mierzone przynajmniej na skali porządkowej. Jeśli zmienne opisujące obiekty mierzone są na skali przedziałowej lub ilorazowej należy sprowadzić je do porównywalności poprzez normalizację; 5) relacją porządkującą elementy zbioru A jest relacja większości lub mniejszości dotycząca liczbowych wartości syntetycznego miernika rozwoju.
Porządkowanie liniowe Procedury porządkowania liniowego można podzielić na: • wzorcowe • bezwzorcowe W formułach bezwzorcowych następuje uśrednienie znormalizowanych wartości zmiennych (np. z udziałem przyjętych wag). Formuły wzorcowe są różnego rodzaju odległościami poszczególnych obiektów od obiektu wzorcowego, którym w badaniach empirycznych jest na ogół tzw. dolny bądź górny biegun rozwoju.
Metody bezwzorcowe Polegają na wyznaczeniu syntetycznej miary będącej funkcją pierwotnych cech. Najczęściej jest to średnia arytmetyczna: lub inne średnie: gdzie: to system wag: Im wyższa wartość SMR, tym wyższa pozycja obiektu w szeregu.
Warunki stosowalności Formuły bezwzorcowe można stosować do agregacji wartości zmiennych, gdy: • wszystkie zmienne (a więc stymulanty, destymulanty i nominanty) są pierwotnie mierzone na skali ilorazowej; • destymulanty i nominanty po przekształceniu na stymulanty są mierzone na skali ilorazowej (do zamiany destymulant i nominant na stymulanty należy stosować formuły ilorazowe); • normalizacja zmiennych została przeprowadzona za pomocą jednej z formuł o postaci przekształcenia ilorazowego.
Metody wzorcowe Istnieje kilka formuł agregacji znormalizowanych wartości zmiennych, opartych na wzorcu rozwoju: gdzie: – j-ta współrzędna obiektu-wzorca; – wartość zmiennej syntetycznej (SMR) dla i-tego obiektu; – znormalizowana wartość j-tej zmiennej w i-tym obiekcie.
Warunki stosowalności Formuły wzorcowe stosuje się do agregacji wartości zmiennych, gdy: • zmienne są mierzone na skali przedziałowej lub ilorazowej. • nie trzeba na ogół ujednolicać charakteru zmiennych. Jeśli w zbiorze zmiennych znajduje się nominanta (nominanty), to obiektem-wzorcem musi być górny biegun rozwoju. Wynika to stąd, że nominalna wartość nominanty jest wartością optymalną; • normalizację wartości zmiennych przeprowadza się z wykorzystaniem standaryzacji lub unitaryzacji.
Metoda Hellwiga Zakłada się w nich istnienie pewnego obiektu wzorcowego, w stosunku do którego wyznacza się odległości pozostałych obiektów. Własności (współrzędne) tego obiektu można wyznaczyć subiektywnie (np. poprzez ekspertów) lub obiektywnie (na podstawie danych): W = (z 01, z 02, z 03, . . . , z 0 N) Współrzędne wzorca wyznaczamy za pomocą formuły: i – numer obiektu j – numer zmiennej
Metoda Hellwiga (c. d. ) Następnie obliczamy wartość miary Hellwiga: gdzie di 0 to odległość euklidesowa i-tego obiektu od wzorca: zaś d 0 oznacza: Wartości składowe d 0 obliczono zgodnie z formułami: oraz
Metoda Hellwiga (c. d. ) Syntetyczna miara Hellwiga przyjmuje wartości z przedziału [0, 1] i jest tak skonstruowana, że im większe przyjmuje wartości, tym dany obiekt znajduje się bliżej wzorca.
Przykład
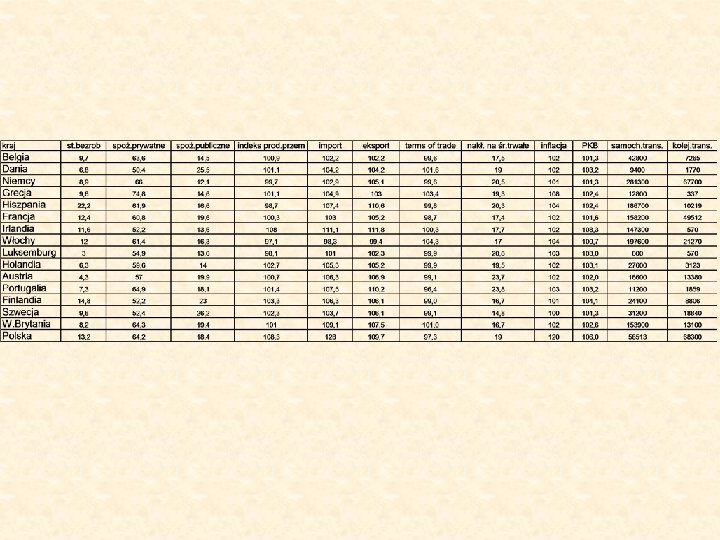
Zmienne: · wartość aktywów netto · udział kapitału zagranicznego · liczba członków · % członków płacących składki · średnia wartość składki · % aktywów zainwestowanych w akcje · % aktywów zainwestowanych w bony skarbowe i obligacje · opłata członkowska · roczny wzrost wartości jednostki uczestnictwa · stopa zwrotu
Fundusz Hellwig Commercial Union 0, 635 ING Nationale-Nederlanden 0, 493 PZU Złota Jesień 0, 473 AIG 0, 407 Bankowy 0, 397 Zurich 0, 338 DOM 0, 322 Ego 0, 284 Allianz 0, 275 SAMPO 0, 260 PBK Orzeł 0, 238 Pekao Pioneer 0, 236 Skarbiec-Emerytura 0, 235 Winterthur 0, 227 Pocztylion 0, 203 Polsat 0, 051 Kredyt Bank 0, 007