Lecture 11 Case Studies Le Net Alex Net

![Convolutional Neural Networks [Le. Net-5, Le. Cun 1980] SRTTU – A. Akhavan Lecture 11](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-2.jpg "Convolutional Neural Networks [Le. Net-5, Le. Cun 1980] SRTTU – A. Akhavan Lecture 11")






 simple cells: modifiable parameters complex cells: perform")







![Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-20.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First")
![Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-21.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First")
![Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-22.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After")
![Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-23.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After")
![Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-24.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After")
![Case Study: Alex. Net [Krizhevsky et al. 2012] Full (simplified) Alex. Net architecture: [227](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-25.jpg "Case Study: Alex. Net [Krizhevsky et al. 2012] Full (simplified) Alex. Net architecture: [227")




![Case Study: VGGNet [Simonyan and Zisserman, 2014] Only 3 x 3 CONV stride 1,](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-30.jpg "Case Study: VGGNet [Simonyan and Zisserman, 2014] Only 3 x 3 CONV stride 1,")



![Re. LU [Lin et al. , 2013. Network in network] SRTTU – A. Akhavan](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-34.jpg "Re. LU [Lin et al. , 2013. Network in network] SRTTU – A. Akhavan")
 SRTTU – A. Akhavan Lecture 11 - 35 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ")



![Inception network [Szegedy et al. , 2014, Going Deeper with Convolutions] SRTTU – A.](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-39.jpg "Inception network [Szegedy et al. , 2014, Going Deeper with Convolutions] SRTTU – A.")



![Residual block [He et al. , 2015. Deep residual networks for image recognition] SRTTU](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-43.jpg "Residual block [He et al. , 2015. Deep residual networks for image recognition] SRTTU")

![Case Study: Res. Net [He et al. , 2015] Slide from Kaiming He’s recent](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-45.jpg "Case Study: Res. Net [He et al. , 2015] Slide from Kaiming He’s recent")
![Case Study: Res. Net [He et al. , 2015] ILSVRC 2015 winner (3. 6%](https://slidetodoc.com/presentation_image/c16acf85c1d4160f6145dc0a242d8bee/image-46.jpg "Case Study: Res. Net [He et al. , 2015] ILSVRC 2015 winner (3. 6%")

 SRTTU – A. Akhavan Lecture 11 - 48")

- Slides: 49
Lecture 11: Case Studies Le. Net – Alex. Net – ZFNet – VGG Inception – Resnet Alireza Akhavan Pour CLASS. VISION SRTTU – A. Akhavan Lecture 11 - 1 ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ ۱۳۹۷
Convolutional Neural Networks [Le. Net-5, Le. Cun 1980] SRTTU – A. Akhavan Lecture 11 - 2 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
On center No light Light on No light Off center SRTTU – A. Akhavan Lecture 11 - 3 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
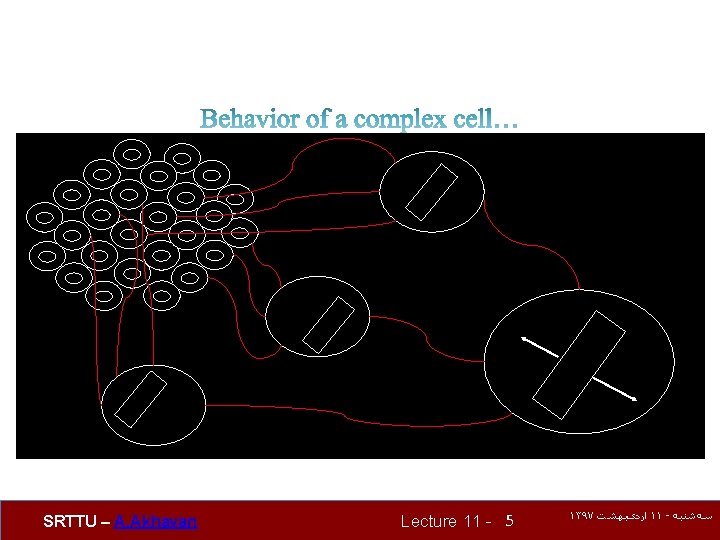
No light wrong position-wrong orientation SRTTU – A. Akhavan wright position-wrong orientation wrong position-wright orientation Lecture 11 - 4 Wright position Wright orientation ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
A bit of history: Hubel & Wiesel, 1959 RECEPTIVE FIELDS OF SINGLE NEURONES IN THE CAT'S STRIATE CORTEX 1962 RECEPTIVE FIELDS, BINOCULAR INTERACTION AND FUNCTIONAL ARCHITECTURE IN THE CAT'S VISUAL CORTEX 1968. . . SRTTU – A. Akhavan Lecture 11 - 6 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
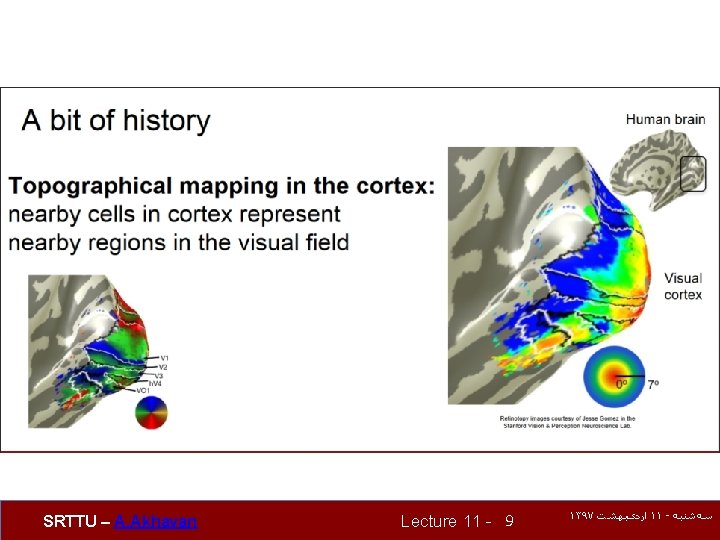
A bit of history Topographical mapping in the cortex: nearby cells in cortex represented nearby regions in the visual field SRTTU – A. Akhavan Lecture 11 - 8 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
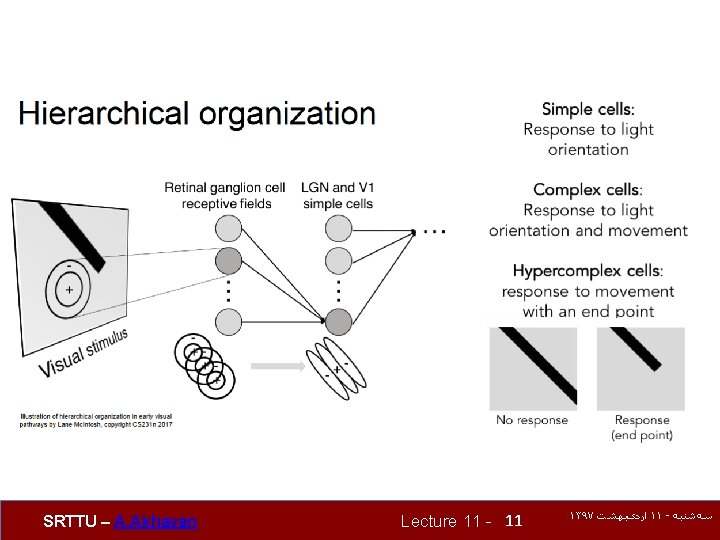
Hierarchical organization SRTTU – A. Akhavan Lecture 11 - 10 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
A bit of history: “sandwich” architecture (SCSCSC…) simple cells: modifiable parameters complex cells: perform pooling Neurocognitron [Fukushima 1980] SRTTU – A. Akhavan Lecture 11 - 12 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
A bit of history: Gradient-based learning applied to document recognition [Le. Cun, Bottou, Bengio, Haffner 1998] Le. Net-5 SRTTU – A. Akhavan Lecture 11 - 13 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Demo https: //www. youtube. com/watch? v=Agkf. IQ 4 IGa. M SRTTU – A. Akhavan Lecture 11 - 14 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Classic networks: • Le. Net-5 • Alex. Net • ZFNet • VGG Res. Net Inception SRTTU – A. Akhavan Lecture 11 - 15 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Le. Net - 5 avg pool f=2 s=2 avg pool f=2 s=2 120 84 [Le. Cun et al. , 1998. Gradient-based learning applied to document recognition] SRTTU – A. Akhavan Lecture 11 - 17 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Alex. Net MAX-POOL = 9216 4096 Softmax 1000 [Krizhevsky et al. , 2012. Image. Net classification with deep convolutional neural networks] SRTTU – A. Akhavan Lecture 11 - 19 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First layer (CONV 1): 96 11 x 11 filters applied at stride 4 => Output volume [55 x 96] Q: What is the total number of parameters in this layer? SRTTU – A. Akhavan Lecture 11 - 20 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images First layer (CONV 1): 96 11 x 11 filters applied at stride 4 => Output volume [55 x 96] Parameters: (11*11*3)*96 = 35 K SRTTU – A. Akhavan Lecture 11 - 21 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After CONV 1: 55 x 96 Second layer (POOL 1): 3 x 3 filters applied at stride 2 Q: what is the output volume size? Hint: (55 -3)/2+1 = 27 SRTTU – A. Akhavan Lecture 11 - 22 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After CONV 1: 55 x 96 Second layer (POOL 1): 3 x 3 filters applied at stride 2 Output volume: 27 x 96 Q: what is the number of parameters in this layer? SRTTU – A. Akhavan Lecture 11 - 23 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Input: 227 x 3 images After CONV 1: 55 x 96 Second layer (POOL 1): 3 x 3 filters applied at stride 2 Output volume: 27 x 96 Parameters: 0! SRTTU – A. Akhavan Lecture 11 - 24 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Alex. Net [Krizhevsky et al. 2012] Full (simplified) Alex. Net architecture: [227 x 3] INPUT [55 x 96] CONV 1: 96 11 x 11 filters at stride 4, pad 0 [27 x 96] MAX POOL 1: 3 x 3 filters at stride 2 [27 x 96] NORM 1: Normalization layer [27 x 256] CONV 2: 256 5 x 5 filters at stride 1, pad 2 [13 x 256] MAX POOL 2: 3 x 3 filters at stride 2 [13 x 256] NORM 2: Normalization layer [13 x 384] CONV 3: 384 3 x 3 filters at stride 1, pad 1 [13 x 384] CONV 4: 384 3 x 3 filters at stride 1, pad 1 [13 x 256] CONV 5: 256 3 x 3 filters at stride 1, pad 1 [6 x 6 x 256] MAX POOL 3: 3 x 3 filters at stride 2 [4096] FC 6: 4096 neurons [4096] FC 7: 4096 neurons [1000] FC 8: 1000 neurons (class scores) SRTTU – A. Akhavan Details/Retrospectives: - first use of Re. LU - used Norm layers (not common anymore) - heavy data augmentation - dropout 0. 5 - batch size 128 - SGD Momentum 0. 9 - Learning rate 1 e-2, reduced by 10 manually when val accuracy plateaus - L 2 weight decay 5 e-4 - 7 CNN ensemble: 18. 2% -> 15. 4% Lecture 11 - 25 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: ZFNet Alex. Net but: CONV 1: change from (11 x 11 stride 4) to (7 x 7 stride 2) CONV 3, 4, 5: instead of 384, 256 filters use 512, 1024, 512 Image. Net top 5 error: 15. 4% -> 14. 8% [Zeiler and Fergus, 2013] SRTTU – A. Akhavan Lecture 11 - 27 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
VGG - 16 POOL FC 4096 POOL FC 4096 [Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition] SRTTU – A. Akhavan Lecture 11 - Softmax 1000
Case Study: VGGNet [Simonyan and Zisserman, 2014] Only 3 x 3 CONV stride 1, pad 1 and 2 x 2 MAX POOL stride 2 TOTAL memory: 24 M * 4 bytes ~= 93 MB / image (only forward! ~*2 for bwd) TOTAL params: 138 M parameters best model 11. 2% top 5 error in ILSVRC 2013 -> 7. 3% top 5 error SRTTU – A. Akhavan Lecture 11 - 30 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Classic networks: • Le. Net-5 • Alex. Net 7 CNN ensemble: 15. 4% top 5 error • ZFNet 14. 8% top 5 error • VGG 7. 3% top 5 error Inception Res. Net SRTTU – A. Akhavan Lecture 11 - 31 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
One by One Convolution! SRTTU – A. Akhavan Lecture 11 - 32 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
1 3 2 4 1 5 2 5 1 7 5 4 3 5 3 8 3 9 6 1 4 5 7 8 5 3 9 7 4 3 8 4 3 9 8 5 2 4 6 2 [Lin et al. , 2013. Network in network] SRTTU – A. Akhavan Lecture 11 - 33 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Re. LU [Lin et al. , 2013. Network in network] SRTTU – A. Akhavan Lecture 11 - 34 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Inception (Goog. Le. Net) SRTTU – A. Akhavan Lecture 11 - 35 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
http: //knowyourmeme. com/memes/we-need-to-go-deeper SRTTU – A. Akhavan Lecture 11 - 36 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
28 x 64 Same 28 x 28 Same 28 x 128 64 2 x 28 x 3 28 Same MAX-POOL 28 2 3 8 x x 2 28 128 32 32 Same [Szegedy et al. 2014. Going deeper with convolutions] SRTTU – A. Akhavan Lecture 11 - 37 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Inception module 28 x 64 28 x 128 Previous Activation 28 x 192 96 28 x 32 Channel Concat 16 28 x 32 28 x 192 SRTTU – A. Akhavan Lecture 11 - 38 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Inception network [Szegedy et al. , 2014, Going Deeper with Convolutions] SRTTU – A. Akhavan Lecture 11 -
Case Study: Goog. Le. Net Fun features: - Only 5 million params! (Removes FC layers completely) Compared to Alex. Net: - 12 X less params - 2 x more compute - 6. 67% (vs. 16. 4%) SRTTU – A. Akhavan Lecture 11 - 40 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Goog. Le. Net Inception module [Szegedy et al. , 2014, Going Deeper with Convolutions] SRTTU – A. Akhavan ILSVRC 2014 winner (6. 7% top 5 error) Lecture 11 - 41 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Residual block [He et al. , 2015. Deep residual networks for image recognition] SRTTU – A. Akhavan Lecture 11 - 43 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Residual Network Res. Net training error Plain # layers [He et al. , 2015. Deep residual networks for image recognition] SRTTU – A. Akhavan Lecture 11 - 44 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Res. Net [He et al. , 2015] Slide from Kaiming He’s recent presentation https: //www. youtube. com/watch? v=1 PGLj-u. KT 1 w SRTTU – A. Akhavan Lecture 11 - 45 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Res. Net [He et al. , 2015] ILSVRC 2015 winner (3. 6% top 5 error) 2 -3 weeks of training on 8 GPU machine at runtime: faster than a VGGNet! (even though it has 8 x more layers) (slide from Kaiming He’s recent presentation) SRTTU – A. Akhavan Lecture 11 - 46 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
Case Study: Res. Net 224 x 3 spatial dimension only 56 x 56! [He et al. , 2015] SRTTU – A. Akhavan Lecture 11 - 47 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
(slide from Kaiming He’s recent presentation) SRTTU – A. Akhavan Lecture 11 - 48 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ
ﻣﻨﺎﺑﻊ • https: //www. slideshare. net/Alirezaakhavanpo ur/akhavan-2 • https: //www. coursera. org/specializations/dee p-learning • http: //cs 231 n. stanford. edu/ SRTTU – A. Akhavan Lecture 11 - 49 ۱۳۹۷ ﺍﺭﺩیﺒﻬﺸﺖ ۱۱ - ﺳﻪﺷﻨﺒﻪ