L 2 to OffChip Memory Interconnects for CMPs















- Slides: 18
L 2 to Off-Chip Memory Interconnects for CMPs Presented by Allen Lee CS 258 Spring 2008 May 14, 2008
Motivation n In modern many-core systems, there is significant asymmetry between the number of cores and the number of memory access points ¨ Tilera’s multiprocessor has 64 cores and only 4 memory controllers n n PARSEC benchmarks suggest that off-chip memory traffic increases with the number of cores for CMPs We explore mechanisms to lower latency and power consumption for processor-memory interconnect
Tilera Tile 64 x 5
Tilera Tile 64 n Five physical mesh networks ¨ UDN, IDN, SDN, TDN, MDN TDN and MDN are used for handling memory traffic n Memory requests transit TDN n ¨ Large n store requests, small load requests Memory responses transit MDN ¨ Large load responses, small store responses ¨ Includes cache-to-cache transfers and off-chip transfers
Tapered Fat-Tree n Good for many-to-few connectivity Fewer hops Shorter latency ¨ Fewer routers Less power, less area ¨ n n Root nodes directly connect to memory controller Replace MDN mesh network with two tapered fat-tree networks One for routing requests up ¨ One for routing responses down ¨
Tile 64 with Tapered Fat Tree
Memory Model Directory-based cache coherence n Directory cache at every node n Off-chip directory controller n Tile-to-tile requests and responses transit the TDN n Off-chip memory requests and responses transit the MDN n
TDN and MDN Traffic for L 2 Read Misses
Synthetic Benchmarks n Statistical simulation Model benchmarks from PARSEC suite ¨ Based on off-chip traffic for 64 -byte cache-line for 64 cores ¨ Less More Sharing Working Set Size Small streamcluster Large canneal 0. 0266 lines off-chip/cycle 99% are loads 1% are stores 0. 0189 lines off-chip/cyc 70% are loads 30% are stores blackscholes x 264 9. 38 e-5 lines off-chip/cycle 20% are loads 80% are stores 0. 0025 lines off-chip/cycle 70% are loads 30% are stores
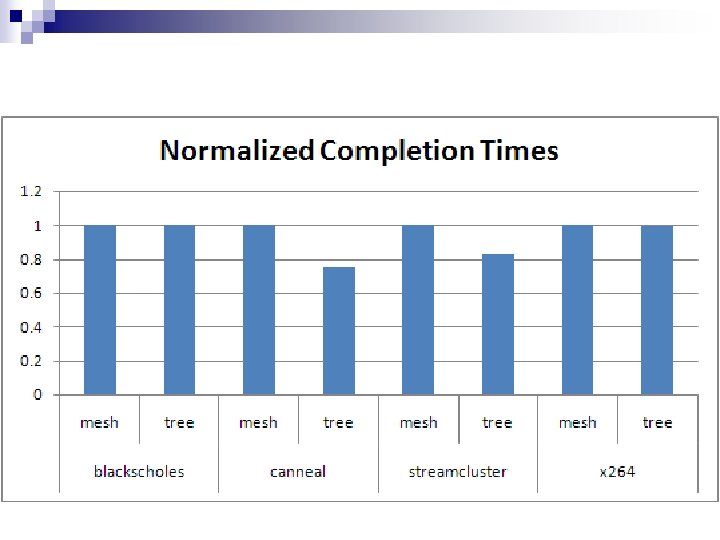
Breakdown of Average Latency of memory intensive applications dominated by queuing delay. n Benchmarks with little off-chip traffic save on transit time. n
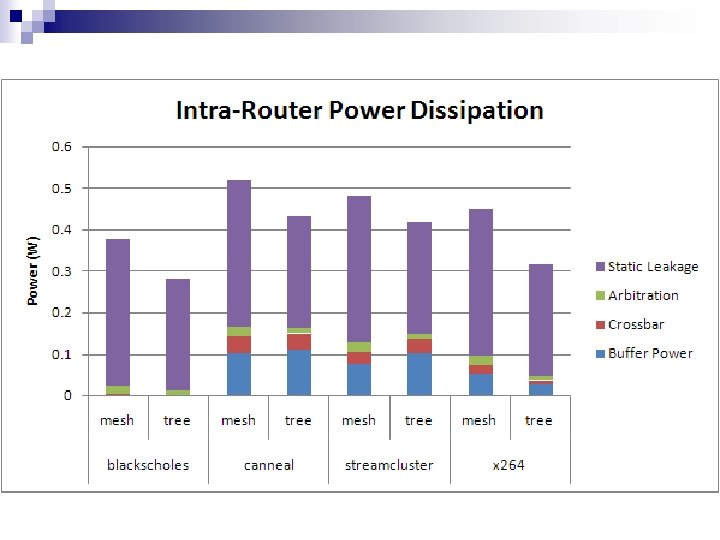
Power Modeling Orion power simulator for on-chip routers from Princeton University n Models switching power as sum of n ¨ Buffer power ¨ Crossbar power ¨ Arbitration power n Specify parameters ¨ Activity factor, number of input and output ports, virtual channels, size of input buffer, etc.
Tilera MDN Routers Router Number Inputs Outputs Width 4 3 3 32 bits 24 4 4 32 bits 36 5 5 32 bits 4 4 1 32 bits in 64 bits out 4 1 4 64 bits in 32 bits out
Tree Routers Router Number Inputs Outputs Width 16 16 4 2 2 4 32 32 8 8 4 4 32 32 8 32 in 64 out 64 in 32 out 4 4 8 1 1
Parameters 100 nm CMOS process n VDD = 1. 0 V n Clock Frequency = 750 MHz n 32 -bit flit width n
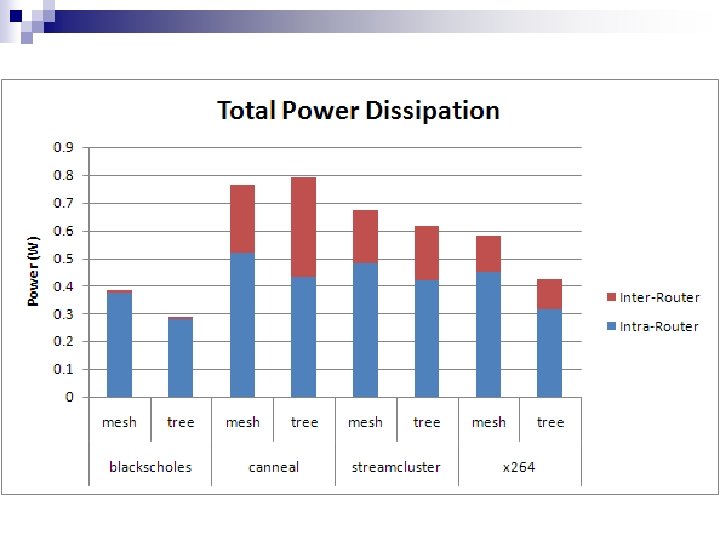
Conclusion Physical design of the tapered fat-tree is more difficult n The TFT topology can reduce memory latency and power dissipation for manycore systems n