High Availability and Disaster recovery High Availability only



High Availability and Disaster recovery High Availability only Availability replicas running across multiple datacenters in private or public cloud scenarios for high availability or disaster recovery. Failover Clustering running WSFC using shared storage architecture. Link for details Protects SQL Server at the instance level, does not protect for data loss, data corruption. Link for details Provides HA/DR Database mirroring is a solution for increasing the availability of a SQL Server database. Mirroring is implemented on a per-database basis and works only with databases that use the full recovery model. Not commonly used for HA/DR scenarios This feature will be removed in a future version of Microsoft SQL Server. § Snapshot Use Always On Availability Groups instead. Link for details Typically complemented by another Always. On technologies 3 Types: § Transactional / P 2 P Transactional § Merge Link for details Provides DR scenarios DR for a single primary database and one or more secondary databases, each on a separate instance of SQL Server. User-specified delay between when the primary server backs up the log of the primary database and when the secondary servers must restore (apply) the log backup. Link for details Azure Site Recovery makes it easy to handle replication, failover and recovery for your on-premises workloads and applications. Can replicate onpremises servers, Hyper-V virtual machines, and VMware virtual machines. Link for details


Availability Group Windows Server Failover Cluster Replica is hosted by a SQL Server instance Unit of High Availability A Primary Replica A Secondary Replica A group of databases that fail over as a unit AG 1 (DB 1, DB 2)

Availability Replica Windows Server Failover Cluster A Primary Replica A Secondary Replica Every other replica is Secondary Active replica is called Primary Each replica hosts a copy of the dbs in the AG AG 1 Readable / Non-Readable / Read-Intent Secondary can be one of the following

§ HA/DR for groups of DBs § Failovers can be automatic or manual § SQL Server replicates transactions from primary to secondaries § Replicas can be synchronous or asynchronous

§ Increased number of secondaries from 4 to 8 § Increased Readable Secondaries Availability Read workloads remain available despite disconnections to primary or quorum loss § SSMS Wizard to add replicas in Azure VM Easy and cost-effective solution for disaster recovery

Higher Availability Orthogonality • 3 Automatic Failover Replicas • Database-level Failure Detection • Support GMSAs (Group Managed Service Accounts) • Support DTC (Distributed Transaction Coordinator) • Read tables with column-store indexes in secondaries Scalability • Much higher Synchronization Throughput Flexibility • Replicas in different domains or domain-less • Distributed Availability Groups Ease of Use Licensing • Load Balancing of Read Workloads • Automatic Secondary Replicas Seeding • Basic Availability Groups in SQL Standard Edition

§ 3 Automatic Failover Replicas § Listener connects to primary as before § Failover priority defined in Windows Cluster’s preferred owners AG_Listener DB Replica 1 (Primary) (Secondary) DB DB Replica 2 Replica 3 (Secondary) (Primary) Increases AG availability

§ Database-level Failure Detection § Automatic failover if any user database in the Availability Group goes offline unexpectedly (e. g. due to inaccessible database files) § This is an option on top of the Availability Group Health Level (evaluates server health using sp_server_diagnostics) CREATE AVAILABILITY GROUP ag_name WITH ( FAILURE_CONDITION_LEVEL = { 1 | 2 | 3 | 4 | 5 }, DB_FAILOVER = { ON | OFF } ) MDF LDF DB Ensures database availability
 § Active Directory handles password changes for")
§ Support GMSAs (Group Managed Service Accounts) § Active Directory handles password changes for service accounts § without restarting SQL services § 120 -character passwords § Requires Windows Server 2012 + Avoids downtime Simplifies management
 § Ensures atomicity of distributed transactions, even if")
§ Support DTC (Distributed Transaction Coordinator) § Ensures atomicity of distributed transactions, even if active when AG fails over § Distributed transactions between different SQL Servers; or SQL Server and other DTC-complaint servers (e. g. Oracle Database or Web. Sphere MQ) § AG registers databases in DTC with a GUID § Requires Windows Server 2012 R 2 + CREATE AVAILABILITY GROUP ag_name WITH ( DTC_SUPPORT = { PER_DB | NONE } ) Important for legacy enterprise applications DB Replica 1 (Primary) DB Replica 2 (Secondary)

§ Much Higher Synchronization Throughput § § § 50 MB/s to 500 MB/s (10 X) Multi-threaded log compression/decompression New compression function: LZ 4 Multi-threaded log redo Keeps secondaries synchronized irrespective of workload size (low RTO) Important for heavy workloads on fast I/O cards

§ Replicas in different domains or domain-less § SQL Server management doesn’t change § Windows Cluster nodes are configured with certificate-based authentication (like Database Mirroring) § Requires Windows Server 2016 Important for different organizational domains AG_Listener Domain A DB Replica 1 (Primary) Domain B DB Replica 2 (Secondary) DB Replica 3 (Secondary)

§ Distributed Availability Groups § One Availability Group can synchronize to one or more Availability Groups § Reduces primary replica’s network and CPU usage § Availability Groups are in different Windows Clusters § Flexible management of Windows Clusters (e. g. independent quorum) § Uni-directional synchronization (only one master replica), uses different listeners CREATE AVAILABILITY GROUP dist_ag WITH (DISTRIBUTED) AVAILABILITY GROUP ON 'ag 1' WITH ( LISTENER_URL = 'tcp: //ag 1 -listener: 5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC), 'ag 2' WITH ( LISTENER_URL = 'tcp: //ag 1 -listener: 5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC) Important for large-scale deployments
 are load balanced")
§ Load Balancing of Read Workloads § Read connections (specifying application_intent=‘read_only’) are load balanced between readable secondaries § Integrated load balancing (instead of DNS-based or F 5) § Simple load balancing: round robin § Possible to specify prioritized load balancing groups (e. g. local first) Important for customers with heavy read workloads
, ’Replica")
§ Load Balancing of Read Workloads READ_ONLY_ROUTING_LIST= ((‘Replica 2’, ’Replica 3’, ’Replica 4’), ’Replica 5’) Replica 2 (secondary) Replica 5 (secondary) Replica 3 (secondary) Replica 1 (Primary) Replica 4 (secondary) DR Site Primary Site

§ Automatic Secondary Replicas Seeding § Initialize the database copies in secondary replicas via log streaming (instead of backup/restore) § Uses new much faster synchronization § Can seed from a local Availability Group replica in a Distributed Availability Group (instead of having to seed from remote master replica) Useful for large databases in large -scale environments*

§ Basic Availability Groups in SQL Standard Edition § Basic HA solution in SQL Standard (replaces Database Mirroring) § 2 replicas only § Sync or Async (can be in Azure) § Not Readable § Automatic or Manual failover § 1 DB per AG § Everything else is the same (high synchronization throughput, domain- less support, streaming seeding, …) Critical to customers requiring HA for SMB apps

Read-scale availability groups



Data Synchronization Internals


Log Blocks Header • The atomic unit of physical commit to a log file • Contains a Header, Log Records, and a Slot Array • Each block ranges in size from 512 bytes to 60 K Slot Array no. Records, block. Size, prev. Block. Size, . . . Record 1 Record 2 Record 3


Current Buffer waiters

Log Pool • Enhances performance of operations that read the Transaction Log • Log blocks pushed into Log Pool based on consumers. • Lookup done based on private cache and hashed entries MEMORYCLERK_SQLLOGPOOL Consumers: Repl, HADR, Recovery, Rollback, fn_dblog Log Pool ( Per Instance) - sys. dm_logpool_stats Sys. dm_logconsumer_privatecachebuffers ( Per. DB) Hash Table IOBuf Sys. dm_logconsumer_cachebufferref (Shared - Per DB) LB KB 2769594 - Out of Memory Errors Due to Log Pool Cache Sys. dm_logpool_ hashentries Log Manager ( per DB) LB Log Block Tlog

Data Synchronization in Synchronous mode Windows Server Failover Cluster SQLINST 1 Begin Tran Insert into Employee() values (2, ‘Bob’) Commit New in SQL Server 2016: Parallel and faster compression of log blocks on the primary Log Block Log Cache Log Pool Primary Replica SQLINST 2 10 X increase in synchronization throughput in SQL AG 1 (DB 1, DB 2) Server 2016 due to DB 2) Log Network Capture performance Receive improvements A A Secondary Replica Redo Thread Log Cache Harden SQLINST 1 Buffer Pool Tlog New in SQL Server 2016: Optimized synchronization protocol Acknowledge Commit Tlog New in SQL Server 2016: Parallel decompression and redo on log records on secondary

Data Synchronization in Asynchronous mode Windows Server Failover Cluster SQLINST 1 Begin Tran Insert into Employee() values (2, ‘Bob’) Commit New in SQL Server 2016: Parallel and faster Acknowledge compression of Commit log blocks on the primary Log Block 1 Log Cache Log Pool Primary Replica SQLINST 2 10 X increase in synchronization throughput in SQL AG 1 (DB 1, DB 2) Server 2016 due to DB 2) Log Network Capture performance Receive improvements A A Secondary Replica New in SQL Server 2016: Parallel decompression and redo on log records on secondary Redo Thread Log Cache Harden SQLINST 1 Buffer Pool Harden Tlog New in SQL Server 2016: Optimized synchronization protocol Tlog

What happens when - Secondary Replica goes offline

Synchronous Secondary Replica goes offline Windows Server Failover Cluster Start waiting on acknowledge ment from Secondary Replica Primary Replica A SQLINST 1 Block Transaction Log Blocks SYNCHRONIZED NOT SYNCHRONIZED SYNCHRONIZING SQLINST 2 Last Hardened LSN End-Of-Log Last Redone(EOL) LSN UNTIL Last Hardened LSN of primary = Last Hardened LSN of secondary AG 1 (DB 1, DB 2) A Harden Last Redone LSN AG 1 (DB 1, DB 2) Last Hardened LSN Redo Tlog

Asynchronous Secondary Replica goes offline Windows Server Failover Cluster Secondary Replica Primary Replica A SQLINST 1 Block Transaction Log Blocks A SQLINST 2 Last Hardened LSN End-Of-Log Last Redone(EOL) LSN Harden Last Redone LSN AG 1 (DB 1, DB 2) SYNCHRONIZING NOT SYNCHRONIZED AG 1 (DB 1, DB 2) Last Hardened LSN Redo Tlog

What happens when - Primary Replica goes offline Automatic failover No Starting in SQL Server 2016, you can now configure Availability Groups Synchronous-commit to failover when a mode with manual mode with automatic database goes failover mode No Yesoffline. Planned manual failover No Yes Forced failover Yes Yes* Asynchronouscommit mode

Automatic Failover

How does Automatic Failover Work? Windows Server Failover Cluster Health Check Detects Failure A Restart resource Primary Replica A Secondary Replica 1 A Health Check Detects Health Resource fails Automatic Failover AG 1 Synchronous Data Movement AG 1 Secondary Replica 2 If both the secondary synchronous-commit replicas are SYNCHRONIZED and healthy and multiple automatic failover targets have been configured, which replica will the Cluster choose to failover to? Asynchronous Data Movement Note: In SQL Server 2016, both synchronous secondary replicas can be configured as automatic failover partners with the primary replica.

Planned Manual Failover

Forced Failover

How can a Forced Failover can cause Data Loss? Windows Server Failover Cluster A Failed Primary Replica A Asynchronous Secondary Replica Perform a manual forced failover Tlog Manually Resume Synchronization Synchronizing Secondary DBs Suspended Data Loss AG 1 (DB 1, DB 2) Last Hardened LSN = 50 100 Asynchronous Data Movement AG 1 (DB 1, DB 2) Last Hardened LSN = 50


Quorum loss Lease timeout Health. Check timeout SQL Dumps User initiated

One or more DBs not sync’d Secondary not connected WSFC cannot connect to SQL AG set for manual failover Exceeded failover thresholds
*** The RHS.")
Always. On AGs require & depend on Windows Server Failover Clustering (WSFC)*** The RHS. EXE process monitors SQL health. The RHS. EXE process also establishes a “lease” with SQL Server on the AG primary. If the cluster service stops on the AG primary, the AG goes offline.

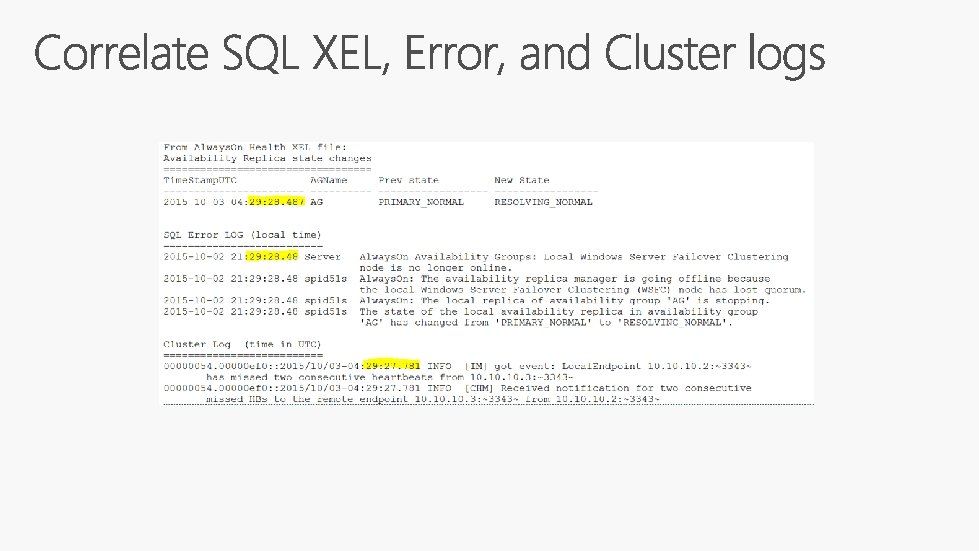
Review Always. On Health extended events Review SQL Server error logs Review System Health extended events If needed, then review these: Review SQL Diagnostic extended events Application event logs System event logs Cluster event logs Network event logs Review “cluster logs”

Look for failover DDL events Look for lease timeout events

Look at all state changes to get timelines

Anatomy Get-Cluster. Log Verbose log options


- Slides: 51