Toward a highquality singing synthesizer with vocal texture











 model amplitude • The transformed LF model controls the wave shape")
 model • Transformed LF model is an extension of the LF")
 model")
 model • Transformed LF model is an extension of the LF")





 derivative glottal wave Basic")
 derivative glottal wave Basic")

 N+1 order all pole filter")

")



")



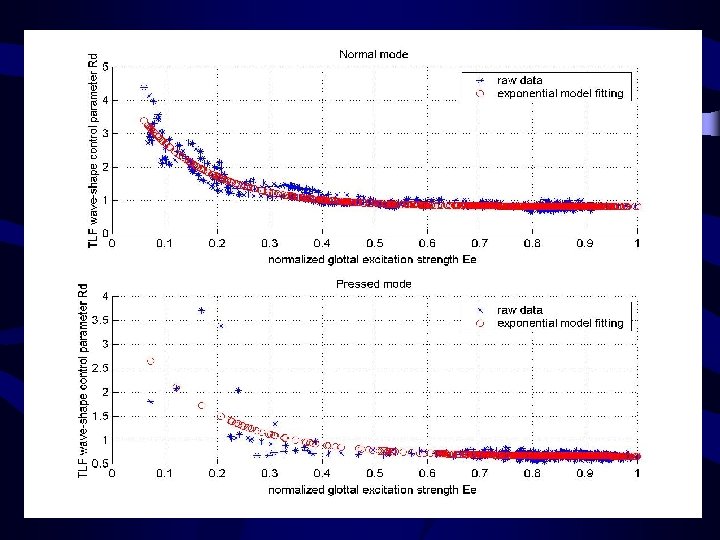
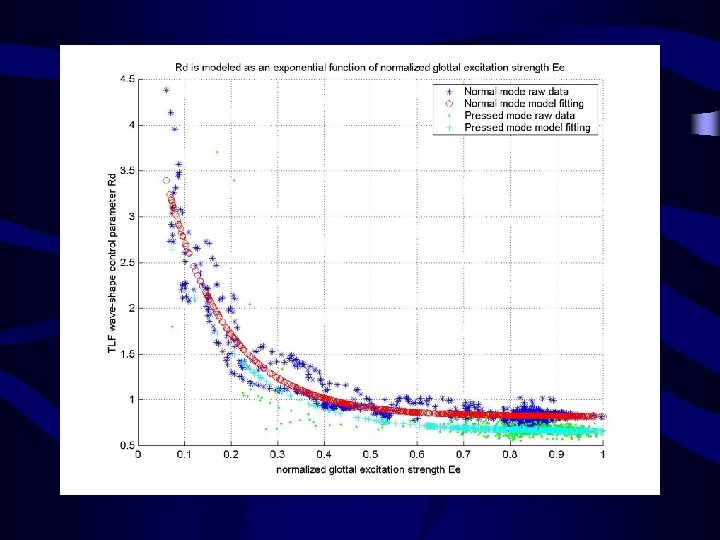
 Pressed and normal modes Wave-shape control parameter Rd and")
 Degree of pressness Glottal excitation strength Ee interpolation (apress")
 High-passed noise energy • NHR per glottal cycle Glottal")





- Slides: 45
Toward a high-quality singing synthesizer with vocal texture control Hui-Ling Lu Center for Computer Research in Music and Acoustics (CCRMA) Stanford University, Stanford, CA 94305, USA
Score-to-Singing system Phoneme Score Lyrics Singing style Rule system F 0 Sound level Duration Vibrato • Lyrics-to-phoneme • Musical rules Parametric Database Sound synthesis Singing voice • Acoustic rendering • Co-articulation rules
General sound synthesis approaches Cons • analysis/re-synthesis difficult • invasive measurements Pros Physical Modelin g • flexible/intuitive control • expressive • co-articulation easy Sourcefilter Model • less expressive • co-articulation difficult Spectral Modelin g • analysis/re-synthesis easy
Contributions A pseudo-physical model for singing voice synthesis which • is an approximate physical model. • can generate high-quality non-nasal singing voice. • has analysis/re-synthesis ability. • is computationally affordable. • provides flexible control of vocal textures. An Automatic analysis procedure for analysis/re-synthesis A parametric model for vocal texture control
Outline • Human voice production system • Synthesis model • Analysis procedure • Vocal texture parametric model • Vocal texture control demo • Contributions and future directions
The human voice production system Nasal cavity Nasal sound output Oral cavity Oral sound output Velum Pharyngeal cavity Vocal folds Lungs Muscle force Tongue hump
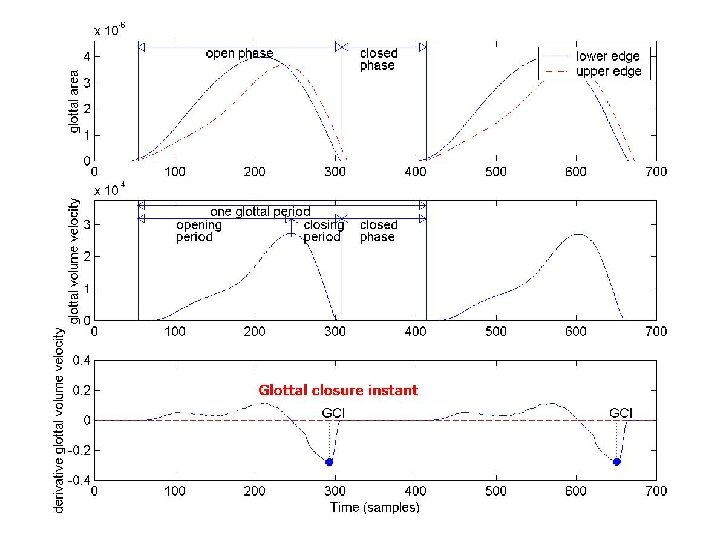
Oscillation pattern of the vocal folds Opening period Open phase Closing period Close phase • The oscillation results from the balancing of the subglottal pressure, the Bernoulli pressure and the elastic restoring force of the vocal folds. • Prephonatory position : the initial configuration of the vocal folds before the beginning of oscillation.
Variation of vocal textures Pressed Normal Breathy
Simplified human voice production model • Source-tract interaction: The glottal waveform in general depends on the vocal tract configuration. • Neglect the source-tract interaction since the glottal impedance is very high most of the time. Glottal Source Vocal Tract Filter Aspiration noise Radiation
Source-filter type synthesis model Glottal Source Radiation Vocal Tract Filter Aspiration noise Glottal excitation Derivative Glottal Wave Aspiration noise Filter Vocal Tract Filter Voice output
Overview of the proposed synthesis model Glottal excitation Derivative glottal wave Filter Transformed Liljencrants-Fant Model All Pole Filter Noise Residual Model High-passed aspiration noise Voice output
Transformed Liljencrants-Fant (LF) model amplitude • The transformed LF model controls the wave shape of the derivative glottal wave via a single parameter, Rd ( wave-shape control parameter). 0. 05 pressed phonation 0 amplitude -0. 05 0 200 400 600 800 1000 1200 1400 0. 05 normal phonation 0 -0. 05 amplitude derivative glottal wave from LF model 0 200 400 600 800 1000 1200 1400 0. 05 breathy phonation 0 -0. 05 0 200 400 600 800 time index 1000 1200 1400
Transformed Liljencrants-Fant (LF) model • Transformed LF model is an extension of the LF model. It provides a control interface for the LF model to change the wave shape of the derivative glottal wave easily. Synthesis: Wave shape Rd control parameter Mapping Analysis: Estimated derivative glottal wave LF fitting Direct synthesis timing parameters Derivative glottal wave LF model Mapping-1 Rd
Liljencrants-Fant (LF) model
Transformed Liljencrants-Fant (LF) model • Transformed LF model is an extension of the LF model. It provides a control interface for the LF model to change the wave shape of the derivative glottal wave easily. Synthesis: Wave shape Rd control parameter Analysis: Estimated derivative glottal wave Mapping LF fitting Direct synthesis timing parameters Derivative glottal wave LF model Mapping-1 Rd
Noise residual model Bn Gaussian Noise Generator Noise floor Noise residual Amplitude Modulation An GCI + L
Vocal tract filter • An all-pole filter. • The vocal tract is assumed to be a series of concatenated uniform lossless cylindrical acoustic tubes. • Assume that sound waves obey planar propagation along the axis of the vocal tract. A 1 glottis A 2 AN Alip end Ug 1 -k. N -1 Ulip
Vocal tract filter Kelly-Lochbaum junction : Scattering coefficient 1 -km Um+ Am Um- -km + Um+1 km 1+km Am+1 Um+1 : the propagation time for sound wave to travel one acoustic tube. N : the number of acoustic tubes excluding the glottis and the lip end. • If sampling period T = 2 , the transfer function of the vocal tract acoustic tubes can be shown to be an Nth order all-pole filter. • The autoregressive coefficients of the vocal tract filter can be converted to scattering coefficients by Durbin’s method.
Overall synthesis model implementation Degree of breathiness 0. 8 E e , F 0 Vocal texture model Rd Transformed LF model + Glottal excitation strength Ee Fundamental frequency F 0 Noise residual model Output voice (No noise input)
Analysis procedure Desired voice recording Source-filter de-convolution Inverse filtered glottal excitation De-noising by Wavelet Packet Analysis Fitting the estimated derivative glottal wave via LF model coefficients High-passed aspiration noise
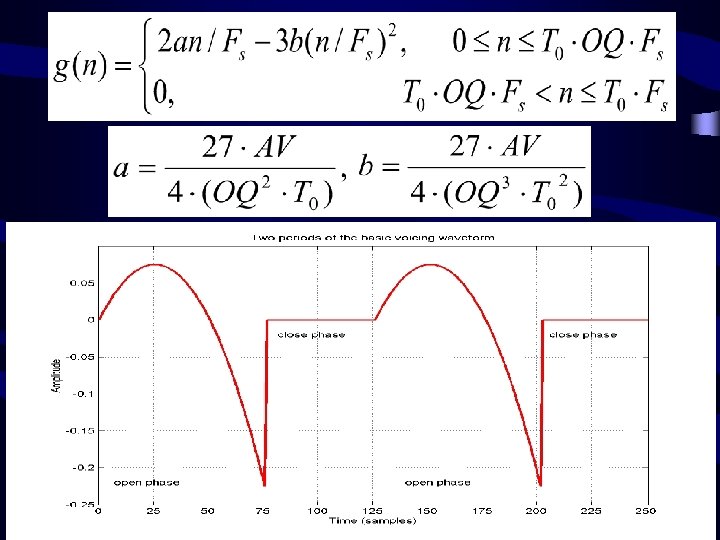
Source-filter de-convolution • Synthesis model for analysis KLGLOTT 88 (KL) derivative glottal wave Basic Voicing Waveform (a, b, OQ) Low-pass filter Nth order All pole vocal tract filter N+1 order all pole filter
Source-filter de-convolution • Synthesis model for analysis KLGLOTT 88 (KL) derivative glottal wave Basic Voicing Waveform (a, b, OQ) Low-pass filter Nth order All pole vocal tract filter N+1 order all pole filter
Source-filter deconvolution estimation flowchart Voice signal after removing the low frequency drift GCI detection Phase I One glottal period signal Loop over different OQ values: Vocal tract filter and glottal source estimation via SUMT End Select and store 5 best estimates Phase II Loop for each period: Enforce continuity constraints via Dynamic Programming End Smoothing the vocal tract area by time averaging and linear interpolation Estimated model parameter sequence
Convex optimization formulation Basic Voicing Waveform (a, b, OQ) N+1 order all pole filter Inverse filter • Estimate by minimizing the error between the basic voicing waveform and the estimated one.
Convex optimization formulation • Error for one glottal cycle in vector form, A convex optimization problem Minimize Subject to • L 2 norm is used The above problem can be solved by SUMT (sequential unconstrained minimization technique).
De-convolution result (synthetic data)
Effective analysis/re-synthesis Baritone examples: • Normal phonation original KLGLOTT 88 • Pressed phonation original KLGLOTT 88 (KL) derivative glottal wave Basic Voicing Waveform (a, b, OQ) Low-pass filter Nth order All pole vocal tract filter
Analysis procedure Desired voice recording Source-filter de-convolution Inverse filtered glottal excitation De-noising by Wavelet Packet Analysis Fitting the estimated derivative glottal wave via LF model coefficients High-passed aspiration noise
De-noising by Wavelet Packet Analysis De-noising by best basis thresholding : • A noisy data record: X = f + W • Transform the noisy data to another basis via Wavelet Packet Analysis : XB = f. B + WB • Thresholding out the smaller coefficients of XB by assuming that f can be compactly represented in the new basis by a few large coefficients. • Select the wavelet filter by energy compactness criteria: 1/(number of coefficients needed to accumulate 0. 9 of the total energy).
De-noising result (synthetic data)
Analysis procedure Desired voice recording Source-filter de-convolution Inverse filtered glottal excitation De-noising by Wavelet Packet Analysis Fitting the estimated derivative glottal wave via LF model coefficients High-passed aspiration noise
Effective analysis/re-synthesis Baritone examples: • Normal phonation original LF • Pressed phonation original LF
Vocal texture control • The parametric vocal texture control model determines the parameterizations of the glottal excitation to achieve the desired vocal texture. • Reduce the control complexity by exploring the correlations between the model parameters. Wave shape Desired Non-breathy mode control Transformed vocal parameter LF ? texture Rd model Glottal excitation strength Ee breathy mode ? Rd Noise residual model
Vocal texture control (non-breathy mode) Pressed and normal modes Wave-shape control parameter Rd and normalized glottal excitation strength Ee are highly correlated.
Vocal texture control (non-breathy mode) Degree of pressness Glottal excitation strength Ee interpolation (apress bpress cpress) (anormal bnormal cnormal) (a, b, c) Wave shape control parameter Rd Glottal Transformed excitation LF model
Vocal texture control (breathy mode) High-passed noise energy • NHR per glottal cycle Glottal excitation strength Ee • NHR is an indicator for the degree of breathiness. • The contour of the noise strength is adjusted by NHR. Desired vocal texture Ee NHR Bn=1 An = 2. 4138* Bn + 0. 213 duty cycle window lag Rd Transformed + LF model Noise residual model gain Glottal excitation
Overall synthesis model implementation Degree of breathiness 0. 8 E e , F 0 Vocal texture model Rd Glottal excitation strength Ee Fundamental frequency F 0 Transformed LF model Noise residual model Glottal + excitation Output voice
Vocal texture control demo
Contributions A pseudo-physical model for singing voice synthesis which • is an approximate physical model. • can generate high-quality non-nasal singing voice. • has analysis/re-synthesis ability. • is computationally affordable. • provides flexible control of vocal textures. An Automatic analysis procedure for analysis/re-synthesis A parametric model for vocal texture control
Future research • Build a complete score-to-singing system using the proposed synthesis model. Its associated analysis procedure will be used to construct the parametric database. • Investigate potential usage of the source-filter deconvolution algorithm to low-bit rate high quality speech coding. • Explore the application of the analysis procedure on sound transformation of vocal textures.
Thank you !