Speech Recognition v v Algorithm Aspects in Speech




 Quintuple λ= (N, M, A, B,")




 = Pr(w …. w ) = Pr(w )Pr(w |w")

- Slides: 12
Speech Recognition v v “Algorithm Aspects in Speech Recognition” , Adam L. Buchsbaum , Raffaele Giancarl Presents the main fields of speech recognition The general problem areas: Graph searching Automata manipulation Shortest path finding Finite state automata minimization Some of the major open problems from an algorithmic viewpoint Asymptotically efficient: handle very large instances Practically efficient: run in real time
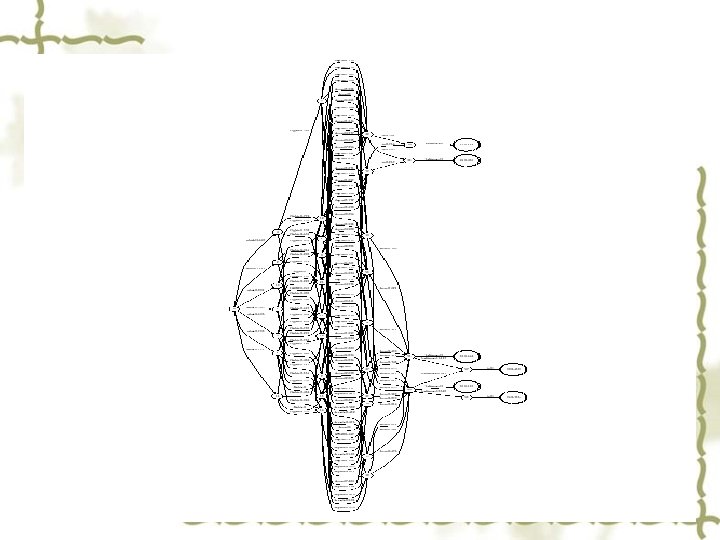
Block diagram of speech recognizer
IWR , CSR v IWR: Isolated Word Recognition Spoken in isolation and belonging to a fixed dictionary Lexicon: typical pronunciations of each word in dictionary Search algorithm: output the word that maximizes a given objective function ( likelihood of a word given the observation sequence) v CSR: Continuous Speech Recognition Lexicon: same as IWR Language model: give a stochastic description of the language and the possibly probabilistic description of which specific words can follow another word or group of words Search algorithm: find a grammatically correct sentence that maximizes a given objective function ( likelihood of a sentence given the observation sequence) Coarticulation effects: “how to recognize speech” vs “how to wreck a nice beach”, incomplete information
Major methods for speech recognition v v Template-based approach Small dictionaries, mainly for IWR Reference templates (a sequence of feature vectors representing a unit of speech to be recognized) Distance measure eg: log spectral distance, likelihood distortions Stochastic approach (maximum likelihood) Dominant method Equations represent X: observation sequence W: unknown sentence Output the sentence ŵ that Pr(ŵ) = max w{ Pr(W|X) } Pr(W|X) * Pr(X) = Pr(X|W) * Pr(W) Ŵ = argmax w { Pr(X|W) * Pr(W) } for fixed X ( argmaxw{ f(w) } = ŵ f(ŵ) = max w{ f(w) } Defn: Cs = -log. Pr eg: Cs(W) = - log. Pr(W) Ŵ = argmin w{ Cs(W) + Cs(X|W) } Solution of the equation: Language Modeling and Acoustic Modeling
Modeling Tools v v HMM (Hidden Markov Model) Quintuple λ= (N, M, A, B, π) N: the number of state M: the number of symbols that each state can output or recognize A: N*N state transition matrix, a(i, j) = the probability of moving from state i to state j B: observation probability distribution, bi(δ) =the probability of recognizing or generating the symbol δwhen in state i Π: the initial state probability distribution such that Πi = the probability of being in state i at time 1. MS (Markov Source) E: transitions between states V: set of states ∑: alphabet including null symbol One to one mapping M from E to V*∑*V M(t) = (i, a, j) i is the predecessor state of t t output symbol a j is the successor state of t
Viterbi v Viterbi Algorithm: Compute the optimal state sequence Q = (q 1, …. . , q. T) throughλ that matches X. (that is max Pr(Q|X, λ) ) βt (i) = probability along the highest probability that accounts for the first t observations and ends in state i γt (i) = the state at time t-1 that led to state I at time t along that path Initialization: Induction: Termination: Backtracking:
Acoustic Word Models via Acoustic Phone Models v Tree representation Static data structure Lexicon Over the alphabet of feature vectors
MS , HMM v v v Circles represent states, arcs represent transitions. Arcs are labeled f/p, denoting that the associated transition outputs phone f and occurs with probability p For each phone f in the alphabet build a HMM Directed graph having a minimum of four and a maximum of seven states with exactly one source, one sink, self loops and no back arcs Gives an acoustic model describing the different ways in which one can pronounce the given phone Technically, this HMM is a device for computing how likely it is that a given observation sequence acoustically matches the given phone
MS + HMM
Conclusion v Language Model Pr(W) = Pr(w …. w ) = Pr(w )Pr(w |w )…. . Pr(w |w …. . w ) Approximation: Pr(w |w …. w ) = Pr(w |w …. w ) 20, 000 words, k=2, 400 million vertices and arcs in the model Possible solution: group the equivalence classes (how to divide? ) 1 j v v v 1 2 j-1 1 j j j-k+1 Heuristic approach Layer solution Shortest path finding Automata machine Redundancy problem and size reduction Training with efficiency 1 1 j-1
Application v AT&T Watson Advanced Speech Application Platform http: //www. att. com/aspg/blasr. html v BBN Speech Products http: //www. bbn. com/speech_prods/ v Dragon. Dictate from Dragon Systems, Inc. http: //www. dragonsys. com/