Protein Asam nukleat replikasi dan transkripsi MRQ 2009







 and glutamine")

. • Struktur primer menyatakan susunan linear")

. Pada RNA gulanya adalah ribosa,")



.")



 untaian DNA induk, 2. Peng-\"awal\"-an( initiation, inisiasi) sintesis")



 yang berfungsi membuka")




 hanya dapat dimulai jika tersedia molekul primer, yaitu")




 dilakukan melalui beberapa")


 sinyal")




 is a run of codons")




 codon in the")








- Slides: 57
Protein – Asam nukleat : replikasi dan transkripsi MRQ - 2009
Protein • Protein tersusun atas satuan yang berupa asam amino. Jumlah asam amino yang umum terdapat pada jasad hidup ada 20 macam.
Protein • Satu asam amino terdiri atas satu gugus amino, satu gugus karboksil, satu atom hidrogen, dan satu rantai samping yang terikat pada atom karbon. • Susunan tetrahedral keempat gugus tersebut menentukan aktivitas optik asam amino sehingga ada dua bentuk isomer yaitu Lisomer dan D-isomer.
Asam amino • Perbedaan utama antara satu asam amino dengan yang lainnya terletak pada gugus sampingnya. • Asam amino paling sederhana strukturnya adalah glisin yang hanya mempunyai satu atom hidrogen pada gugus sampingnya. • Prolin adalah asam amino yang struktur dasarnya berbeda dari asam amino yang lain karena atom N-nya ada dalam struktur cincin, sehingga prolin lebih sesuai dinamakan asam imino. • Struktur prolin yang demikian menyebabkan terjadinya bengkokan pada struktur protein sehingga mempengaruhi arsitektur protein.
Asam amino non polar • Memiliki gugus R alifatik • Glisin, alanin, valin, leusin, isoleusin dan prolin • Bersifat hidrofobik. Semakin hidrofobik suatu asam amino seperti isoleusin , biasa terdapat di bagian dalam protein.
Asam amino dengan gugus R aromatik • Fenilalanin, tirosin dan triptofan • Bersifat relatif non polar hidrofobik • Fenilalanin bersama dgn V, L & I asam amino paling hidrofobik • Tirosin gugus hidroksil , triptofan cincin indol • Sehingga mampu membentuk ikatan hidrogen penting untuk menentukan struktur ensim
Asam amino dengan gugus R bermuatan positif • • • Lisin, arginin, dan histidin Mempunyai gugus yang bersifat basa pada rantai sampingnya Bersifat polar terletak di permukaan protein dapat mengikat air. Histidin mempunyai muatan mendekati netral (pada gugus imidazol) dibanding – lisin gugus amino – arginin gugus guanidino Karena histidin dapat terionisasi pada p. H mendekati p. H fisioligis sering berperan dlm reaksi ensimatis yang melibatkan pertukaran proton
Polar, uncharged amino acids • The side-chains of asparagine (Asn or N) and glutamine (Gln or Q), the amide derivatives of Asp and Glu, respectively, are uncharged but can participate in hydrogen bonding. Serine (Ser or S) and threonine (Thr or T) (Fig. 3 b) are polar amino acids due to the reactive hydroxyl group in the side-chain, and can also participate in hydrogen bonding (as can the hydroxyl group of the aromatic amino acid Tyr).
• Rantai samping asam amino dapat dibedakan atas: 1. polar, bermuatan negatif (aspartat, asam glutamat), 2. polar, bermuatan positif (arginin, histidin, lisin), 3. polar, tidak bermuatan (asparagin, glutamin, serin, dan treonin), 4. nonpolar/hidrofobik (alanin, sistein, isoleusin, metionin, fenilalanin, prolin, triptofan, tirosin, dan valin), 5. netral (glisin). • Kedua puluh macam asam amino beserta singkatannya dapat dilihat pada Tabel 3. 1.
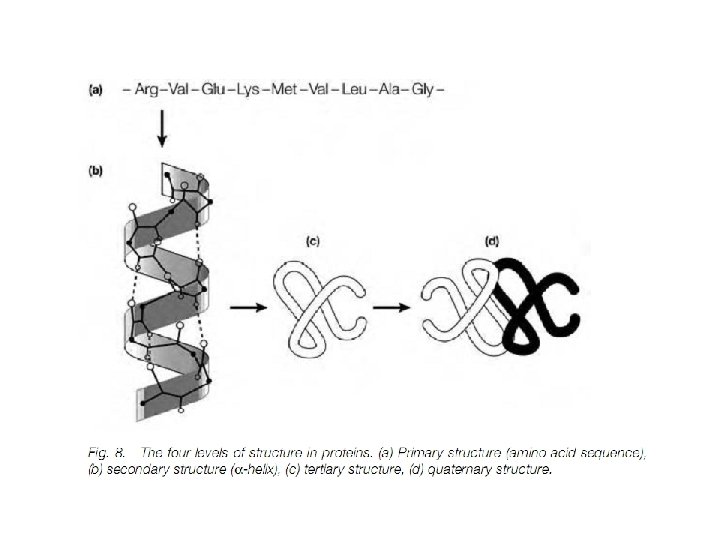
Struktur protein Dapat dibedakan dalam empat aras (level). • Struktur primer menyatakan susunan linear asam-asam amino sepanjang rantai polipeptida. • Struktur sekunder menggambarkan pola pelipatan (folding) bagian polipeptida ke dalam struktur yang teratur, misalnya heliks dan lembaran terlipat-β (β pleated sheet). • Struktur tersier menggambarkan pelipatan bagian-bagian antara heliks-α dan lembaran- β serta semua interaksi nonkovalen yang menyebabkan terjadinya pelipatan yang sesuai pada suatu rantai polipeptida. lnteraksi nonkovalen tersebut antara lain ikatan hidrogen, ikatan hidrofobik, dan interaksi van der Waals. • Struktur kuaterner, menunjukkan interaksi nonkovalen yang mengikat beberapa rantai polipeptida ke dalam satu molekul tunggal protein, misalnya hemoglobin.
Asam nukleat adalah suatu polimer nukleotida yang berperanan dalam penyimpanan serta pemindahan informasi genetik. Satu nukleotida terdiri atas tiga bagian yaitu : 1. Cincin purin atau pirimidin, yaitu basa nitrogen yang terikat pada atom C nomor 1 suatu molekul gula (ribosa atau deoksiribosa) melalui ikatan N-glukosidik. • Basa purin terdiri atas adenine (A) dan guanine (G), serta basa pirimidin yang terdiri atas thymine (T), cytosine (C), dan uracil (U). • Baik DNA (deoxyribonucleic acid) maupun RNA (ribonucleic acid tersusun atas A, G, C, tetapi T hanya ada pada DNA sedangkan U hanya ada pada RNA. • Akan tetapi ada perkecualian, yaitu bahwa pada beberapa molekul t. RNA terdapat basa T, sedangkan pada beberapa bakteriofag DNA-nya tersusun atas U dan bukan basa T.
1. 2. Molekul gula dengan 5 atom C (pentosa). Pada RNA gulanya adalah ribosa, sedangkan pada DNA gulanya adalah deoksiribosa. Perbedaan antara kedua bentuk gula tersebut terletak pada atom C nomor 2. Pada RNA, atom C nomor 2 berikatan dengan gugus hidroksil (OH) sedangkan pada DNA atom C nomor 2 berikatan dengan atom H. Gugus fosfat yang terikat pada atom C nomor 5 melalui ikatan fosfoester. Gugus fosfat inilah yang menyebabkan asam nukleat bermuatan negatif kuat.
Ikatan fosfodiester antarnukleotida. • Suatu basa yang terikat pada satu gugus gula disebut nukleosida, sedangkan nukleotida adalah satu nukleosida yang berikatan dengan gugus fosfat. • Di dalam molekul DNA atau RNA, nukleotida berikatan dengan nukleotida yang lain melalui ikatan fosfodiester (Gambar). • Basa purin dan pirimidin tidak berikatan secara kovalen satu sama lain. • Oleh karena itu, suatu polinukleotida tersusun atas kerangka gula-fosfat yang berselang-seling dan mempunyai ujung 5'-P dan 3'-OH. • Asam nukleat yang mempunyai ujung demikian umum terdapat di alam, meskipun asam nukleat yang mempunyai ujung 5'-OH dan 3'-P dapat disintesis secara Kimiawi.
• Struktur molekul DNA pertama kali Struktur molekul diungkapkan oleh James Watson dan Francis Crick pada tahun 1953 (double DNA helix) • Untai-ganda DNA tersusun oleh dua rantai polinukleotida yang berpilin. Kedua rantai mempunyai orientasi yang berlawanan (antiparalel): • Rantai yang satu mempunyai orientasi 5' 3', sedangkan rantai yang lain berorientasi 3' 5'. Kedua rantai tersebut berikatan dengan adanya ikatan hidrogen antara basa odenine (A) dengan thymine (T), dan antara guonine (G) dengan citosine (C). lkatan antara A-T berupa dua ikatan hidrogen, sedangkan antara G-C berupa tiga ikatan hidrogen sehingga ikatan G-C lebih kuat (Gambar 5. 1). • Spesifisitas pasangan basa semacam ini Pada masing-masing rantai disebut sebagai komplementaritas DNA ada ujung 5'-fosfat (5'-P) (complementority) dan ujung 3'-OH
• Struktur DNA yang dikemukakan Watson dan Crick adalah struktur paling umum terdapat di alam. Struktur semacam ini disebut sebagai Struktur untai putar-kanan struktur untai putar-kanan (right-handed helix). • Struktur tersebut dikelompokkan tipe B. • Molekul DNA tipe B mempunyai lekukan besar dan lekukan kecil. • Dibandingkan dengan tipe A, lekukan besar pada tipe B lebih mudah mengikat protein tertentu karena lekukan besar pada tipe A lebih dalam. • Bentuk A lebih menyerupai konformasi bagian untai-ganda molekul RNA (misalnya pada t. RNA).
• DNA tipe Z adalah satu-satunya DNA yang untaiannya mempunyai orientasi putar-kiri (left-handed). Molekul DNA tipe semacami ni mempunyai kerangka gula-fosfat yang berbentuk zigzag(sehingga disebut Z). • Struktur DNA Z tidak hanya terjadi pada molekul yang mempunyai poli(d. C-d. G), melainkan juga terjadi pada bagian polinukleotida yang basa-basa purin dan pirimidinnya bergantian misalnya: ACAC. • Lebih jauh lagi, jika basa-basa purin dan pirimidin yang ada secara bergantian tersebut terletak pada molekul DNA yang panjang misalnya: TGATCCGCGCAGTCTT. .
Replikasi DNA • Replikasi ialah proses perbanyakan bahan genetik • Pengkopian rangkaian molekul bahan genetik( DNA atau RNA) sehingga dihasilkan molekul anakan yang sangat identik
• Model replikasi DNA secara semikonservatif menunjukkan bahwa DNA anakan terdiri atas pasangan untaian DNA induk dan untaian DNA hasil sintesis baru. • Model ini memberikan gambaran bahwa untaian DNA induk berperanan sebagai cetakan (template) bagi pembentukan untaian DNA baru. • Molekul DNA untai-ganda terdiri atas dua untai molekul DNA yang berpasangan secara komplementer yaitu antara basa nukleotida A dengan T, dan antara C dengan G.
Komponen utama replikasi 1. DNA cetakan, yaitu molekul DNA atau RNA yang akan direplikasi. 2. Molekul deoksiribonukleotida, yaitu d. ATP, d. TTP, d. CTP, dan d. GTp. Deoksiribonukleotida terdiri atas tiga komponen yaitu: (i) basa purin atau pirimidin, (ii) gula 5 -karbon( deoksiribosa) dan (iii) gugus fosfat. 3. Enzim DNA polimerase, yaitu enzim utama yang mengkatalisi proses polimerisasi nukleotida menjadi untaian DNA. 4. Enzim primase, yaitu enzim yang mengkatalisis sintesis primer untuk memulai replikasi DNA. 5. Enzim pembuka ikatan untaian DNA induk, yaitu enzim helikase dan enzim lain yang membantu proses tersebut yaitu enzim girase. 6. Molekul protein yang menstabilkan untaian DNA yang sudah terbuka, yaitu protein SSB (single strand binding protein). 7. Enzim DNA ligase, yaitu suatu enzim yang berfungsi untuk menyambung fragmen-fragmen DNA.
Mekanisme dasar replikasi 1. Denaturasi (pemisahan) untaian DNA induk, 2. Peng-"awal"-an( initiation, inisiasi) sintesis DNA. 3. Pemanjangan untaian DNA, 4. Ligasi fragmen-fragmen DNA, dan 5. Peng-"akhir"-an (termination, terminasi) sintesis DNA.
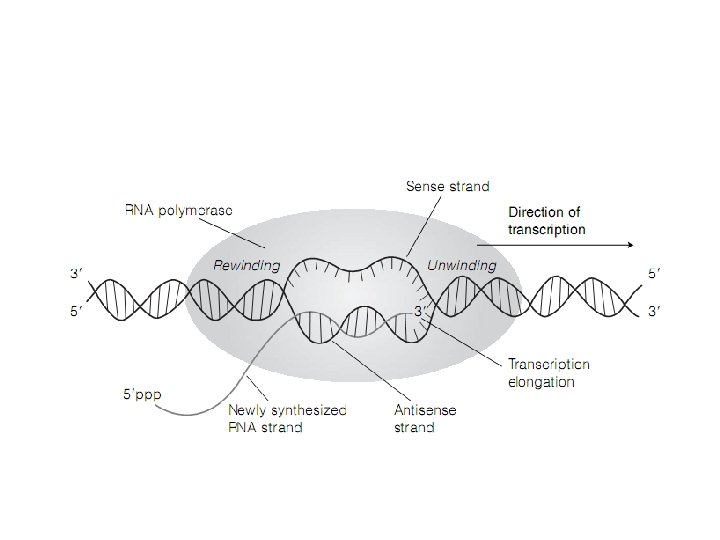
• Sintesis untaian DNA yang baru akan dimulai segera setelah kedua untaian DNA induk terpisah membentuk garpu replikasi Pemisahan kedua untaian DNA induk dilakukan oleh enzim DNA helikase • Sintesis DNA berlangsung dengan orientasi 5'-P 3'-OH. • Oleh karena ada dua untaian DNA cetakan yang orientasinya berlawanan, maka sintesis kedua untaian DNA baru juga berlangsung dengan arah geometris yang berlawanan namun semuanya tetap dengan orientasi 5' 3'
• Sintesis untaian DNA baru yang searah dengan pembukaan garpu replikasi dapat berlangsung tanpa terputus (sintesis secara kontinu). Untaian DNA yang disintesis secara kontinu semacam ini disebut sebagai untaian DNA awal (leading strand). • Sebaliknya sintesis untaian DNA yang berlawanan arah geometrinya dengan arah pembukaan garpu replikasi dilakukan secara tahap demi tahap (sintesis secara diskontinu). Hal ini terjadi karena proses polimerisasi pada untaian DNA ini hanya dapat dilakukan setelah DNA cetakannya membuka seiring dengan membukanya garpu replikasi. Untaian DNA yang disintesis secara lambat semacam ini disebut untaian DNA lambat (lagging strand)
• Pada untaian DNA awal, polimerisasi DNA berlangsung secara kontinu sehingga molekul DNA baru yang disintesis merupakan satu unit. • Sebaliknya, pada untaian DNA lambat polimerisasi dilakukan fragmen demi fragmen. Fragmen-fragmen DNA pendek tersebut pada akhirnya disambung (ligasi) dengan enzim DNA ligase sehingga menjadi unit yang utuh. • Fragmen-fragmen DNA pendek yang disintesis tersebut disebut fragmen Okazaki, karena fenomena sintesis DNA secara diskontinu tersebut pertama kali iungkapkan oleh Reiji Okazaki pada tahun 1968
Koordinasi sintesis DNA awal dan DNA lambat • Dna. B (helikase) yang berfungsi membuka ikatan DNA, bergerak searah dengan arah sintesis untaian DNA awal. Setelah DNA dibuka maka protein SSB menempel pada DNA
Koordinasi sintesis DNA awal dan DNA lambat • Masing-masing inti katalitik DNA polimerase lll akan terikat pada kedua untaian DNA induk (cetakan) dan menyintesis baik DNA awal maupun DNA lambat
Koordinasi sintesis DNA awal dan DNA lambat • Kompleks primosom akan menarik untaian DNA induk yang digunakan sebagai cetakan untuk sintesis DNA lambat ke arah yang sesuai dengan arah pergerakan Dna. B (helikase) sekaligus menyintesis primer.
Koordinasi sintesis DNA awal dan DNA lambat • Salah satu inti katalitik DNA polimerase lll akan menyintesis fragmen Okazaki
Koordinasi sintesis DNA awal dan DNA lambat • Pada waktu garpu replikasi bergerak maju (searah dengan pergerakan sintesis DNA awal), maka protein Pri. A (salah satu komponen primosom) akan bergerak berlawanan arah dari arah gerakan garpu replikasi sekaligus menyingkirkan SSB.
• Polimerisasi DNA (replikasi DNA) hanya dapat dimulai jika tersedia molekul primer, yaitu suatu molekul yang digunakan untuk mengawali proses polimerisasi untaian DNA. • Molekul primer dapat berupa molekul DNA, RNA, atau bahkan protein spesifik
Transkripsi • Transkripsi adalah proses penyalinan kode-kode genetik yang ada pada urutan DNA meniadi molekul RNA. • Tianskripsi adalah proses yang mengawali ekspresi sifat-sifat genetik yang nantinya akan muncul sebagai fenotipe. • Urutan nukleotida pada salah satu untaian molekul RNA digunakan sebagai cetakan (template) untuk sintesis molekul RNA yang komptementer
Molekul RNA • Mololekul RNA yang disintesis dalam proses transkripsi dapat dibedakan menjadi tiga yaitu; (1) m. RNA (messenger RNA), (2) t. RNA (transfer RNA); dan (3) r. RNA (ribosomol RNA). • Molekul m. RNA adalah RNA yang merupakan salinan kode genetik pada DNA yang dalam proses selanjutnya (yaitu proses translasi), akan diterjemahkan menjadi urutan asam amino yang menyusun suatu, polipeptida yaitu protein tertentu. • Molekul t. RNA adalah RNA yang berperan membawa asam amino sfesifik yang akan digabungkan dalam proses sintesis protein (tranlasi). • Molekul r. RNA adalah RNA yang digunakan untuk menyusun ribosom yaitu suatu partikel di dalam sel yang digunakan tempat untuk sintesis protein
• Beberapa komponen utama yang terlibat adalah: 1. 2. 3. 4. • • Urutan DNA yang akan ditranskripsi (cetakan/template) Enzim RNA polimerase, Faktor-faktor transkripsi, dan Prekursor untuk sintesis RNA. Urutan DNA yang ditranskripsi adalah gen yang diekspresikan. Gen dapat diberi batasan sebagai suatu urutan DNA yang mengkode uruton lengkap asam amino suatu polipeptida atau molekul RNA tertentu. Gen yang lengkap terdiri atas tiga bagian urama, yaitu: 1. Daerah pengendali (regulatory region) yang secara umum disebut promoter, 2. Bagian struktural, dan 3. Terminator.
• Promoter adalah bagian gen yang berperanan dalam mengendalikan proses transkripsi dan terletak pada ujung 5'. • Bagian struktural adalah bagian gen yang terletak di sebelah hilir (downstream) dari promoter. Bagian inilah yang mengandung urutan DNA spesifik (kode-kode genetik) yang akan ditranskripsi. • Terminator adalah bagian gen yang terletak di sebelah hilir dari bagian struktural yang berperanan dalam pengakhiran (terminasi) proses transkripsi
Mekanisme dasar transkripsi • 1. 2. 3. 4. Transkripsi (sintesis RNA) dilakukan melalui beberapa tahapan yaitu: Faktor-faktor yang mentendalikan transkripsi menempel pada bagian promoter. Penempelan faktor-faktor pengendali transkripsi menyebabkan terbentuknya kompleks promoter yang terbuka (open promoter complex). RNA pofimerase membaca cetakan (DNA template) dan mulai melakukan pengikatan nukleotida yang komplementer dengan cetakannya. Setelah terjadi proses pemanjangan untaian RNA hasil sintesis, selanjutnya diikuti dengan proses pengakhiran (terminasi) transkripsi yang ditandai dengan pelepasan RNA polimerase dari DNA yang ditranskripsi
Karakter kimiawi transkripsi 1. Prekursor untuk sintesis RNA adalah empat macam ribonukleotida yaitu 5'-trifosfat ATP GTP CTP dan UTP (pada RNA tidak ada thymine). 2. Reaksi polimerisasi RNA pada prinsipnya sama dengan polimerisasi DNA, yaitu dengan arah 5' 3'. 3. Urutan nukleotida RNA hasil sintesis ditentukan oleh cetakannya yaitu urutan DNA yang ditranskripsi. Nukleotida RNA yang digabungkan adalah nukleotida yang komplementer dengan cetakannya. Sebagai contoh, jika urutan DNA yang ditranskripsi adalah ATG, maka urutan nukleotida RNA yang digabungkan adalah UAC. 4. Molekul DNA yang ditranskripsi adalah molekul untai-ganda tetapi yang berperanan sebagai cetakan hanya salah satu untaiannya. 5. Hasil transkripsi berupa molekul RNA untai tunggal.
Pengendali ekspresi genetik • Proses ekspresi genetik dimulai dan diatur sejak pra-inisasi transkripsi • Pengendalian, ekspresi genetik pada jasad eukaryot dilakukan pada, banyak titik pengendalian seperti digambarkan secara skematis pada gambar : Gambar Jalur regulasi ekspresi genetik pada eukaryot: 1) kontrol transkripsi, 2) kontrol pemrosesan RNA, (3) kontroi transpor RNA, (4) kontrol translasi, (5) kontrol degradasi m. RNA, (6) kontrol aktivitas protein'
• Pengendalian ekspresi genetik dapat ditinjau dari 3 sisi yaitu : 1) sinyal pengendali ekspresi 2) aras pengendalian ekspresi dan 3) mekanisme pengendalian • Sinyal pengendali ekpresi meliputi semua molekul yang berperanan dalam proses pengendalian ekspresi, misalnya faktor transkripsi dan protein regulator khusus. • Aras pengenda|ian ekspresi terjadi pada tahapan: (a) inisiasi transkripsi dan perpanjangan transkrip, (b) pengakhiran (terminasi) transkripsi, (c)pengendalian pasca-transkripsi dan (d) pengendalian selama Proses translasi dan pasca-translasi • Mekanisme pengendalian ekspresi membahas Proses rinci pengendalian ekspresi genetik yang meliputi interaksi antar sinyal pengendali ekspresi
THE GENETIC CODE • The genetic code is a triplet code – The genetic code is the rules that specify how the nucleotide sequence of an m. RNA is translated into the amino acid sequence of a polypeptide. – The nucleotide sequence is read as triplets called codons. – The codons UAG, UGA and UAA do not specify amino acids and are called termination codons or Stop codons. – AUG codes for methionine and also acts as an initiation (Start) codon
The genetic code is degenerate • Most amino acids in proteins are specified by more than one codon (i. e. the genetic code is degenerate). • Codons that specify the same amino acid (synonyms) often differ only in the third base, the wobble position, where base pairing with the anticodon may be less stringent than for the first two positions of the codon.
Universality of the genetic code • The genetic code is not universal but is the same in most organisms. • Exceptions are found in mitochondrial genomes where some codons specify different amino acids to that normally encoded by nuclear genes. • In mitochondria, the UGA codon does not specify termination of translation but instead encodes for tryptophan. • Similarly, in certain protozoa UAA and UAG encode glutamic acid instead of acting as termination codons.
Reading frames • • • The m. RNA sequence can be read by the ribosome in three possible reading frames. Usually one reading frame codes for a functional protein since the other two reading frames contain multiple termination codons. In some bacteriophage, overlapping genes occur which use different reading frames.
Open reading frames • An open reading frame (ORF) is a run of codons that starts with ATG and ends with a termination codon, TGA, TAA or TAG. • Coding regions of genes contain relatively long ORFs unlike noncoding DNA where ORFs are comparatively short. • The presence of a long open reading frame in a DNA sequence therefore may indicate the presence of a coding region. • Computer analysis of the ORF can be used to deduce the sequence of the encoded protein
TRANSLATION IN PROKARYOTES • During translation the m. RNA is read in a 5’ to 3’ direction and protein is made in an N-terminal to C-terminal direction. • Translation relies upon aminoacylt. RNAs that carry specific amino acids and recognize the corresponding codons in m. RNA by anticodon–codon base pairing. • Translation takes place in three phases; initiation, elongation and termination
Synthesis of aminoacyl-t. RNA • Each t. RNA molecule has a cloverleaf secondary structure consisting of three stem loops, one of which bears the anticodon at its end. • The amino acid is covalently bound to the 3’ OH group at the 3’ end by aminoacyl synthetase to form aminoacylt. RNA. • The reaction, called amino acid activation, occurs in two steps and requires ATP to form an intermediate, aminoacyladenylate
Initiation of protein synthesis • • Each ribosome has three binding sites for t. RNAs; an A site where the incoming aminoacyl-t. RNA binds, a P site where the t. RNA linked to the growing polypeptide chain is bound, and an E site which binds t. RNA prior to its release from the ribosome. Translation in prokaryotes begins by the formation of a 30 S initiation complex between the 30 S ribosomal subunit, m. RNA, initiation factors and f. Met t. RNAf Met The 30 S subunit binds to the Shine–Dalgarno sequence which lies 5’ to the AUG Start codon and is complementary to the 16 S r. RNA of the small ribosomal subunit. The ribosome then moves in a 3’ direction along the m. RNA until it encounters the AUG codon. The 50 S ribosomal subunit now binds to the 30 S initiation complex to form the 70 S initiation complex. In this complex, the anticodon of the f. Met t. RNAf Met is base paired to the AUG initiation codon (start codon) in the P site.
Elongation • • The elongation cycle consists of three steps: aminoacyl-t. RNA binding, peptide bond formation, and translocation. In the first step, the aminoacyl-t. RNA corresponding to the second codon binds to the A site on the ribosome as an aminoacyl-t. RNA/EFTu/GTP complex. After binding, the GTP is hydrolyzed and EFTu/GDP is released. The EF-Tu is regenerated via the EF-Tu–EF-Ts exchange cycle. Peptide bond formation is catalyzed by peptidyl transferase between the C-terminus of the amino acyl moiety in the P site and the amino group of the aminoacyl-t. RNA in the A site. In the final (translocation) step, EF-G/GTP binds to the ribosome, the deacylated t. RNA moves from the P site to the E site, the dipeptidyl-t. RNA in the A site moves to the P site, and the ribosome moves along the m. RNA to place the next codon in the A site. The GTP is hydrolyzed to GDP and inorganic phosphate. When the next aminoacyl-t. RNA binds to the A site in the next round of elongation, the deacylated t. RNA is released from the E site
Termination • The appearance of a UAA or UAG termination (stop) codon in the A site causes release factor RF 1 to bind whereas RF 2 recognizes UGA. • RF 3 assists RF 1 and RF 2. • The release factors trigger peptidyl transferase to transfer the polypeptide to a water molecule instead of to aminoacyl-t. RNA. • The polypeptide, m. RNA, and free t. RNA leave the ribosome and the ribosome dissociates into its subunits ready to begin a new round of translation
PROTEIN TARGETING • Both in prokaryotes and eukaryotes, newly synthesized proteins must be delivered to a specific subcellular location or exported from the cell for correct activity. • This phenomenon is called protein targeting.
Secretory proteins • Secretory proteins have an N-terminal signal peptide which targets the protein to be synthesized on the rough endoplasmic reticulum (RER). • During synthesis it is translocated through the RER membrane into the lumen. • Vesicles then bud off from the RER and carry the protein to the Golgi complex, where it becomes glycosylated. Other vesicles then carry it to the plasma membrane. • Fusion of these transport vesicles with the plasma membrane then releases the protein to the cell exterior.
• Plasma membrane proteins are also synthesized on the RER but become inserted into the RER membrane (and hence ultimately the plasma membrane) rather than being released into the RER lumen. • The plasma membrane protein may pass once through the plasma membrane (Type I and Type II integral membrane proteins) or may loop back and forth, passing through many times (Type III integral membrane protein). • The orientation of the protein in the membrane is determined by topogenic sequences within the polypeptide chain. Plasma membrane proteins
• Type I proteins have a cleaved N-terminal signal sequence and a hydrophobic stop-transfer sequence, Type II have an uncleaved N-terminal signal sequence that doubles as the membrane-anchoring sequence, and Type III have multiple signal sequences and stop-transfer sequences. • Proteins destined to be anchored in the membrane by a glycosylphosphatidylinositol (GPI) structure have both a cleaved N-terminal signal sequence and a C-terminal hydrophobic sequence that directs addition of the preformed GPI anchor.
Proteins of the endoplasmic reticulum • Proteins destined for the RER have an N-terminal signal peptide, are synthesized on the RER, are translocated into the RER lumen or inserted into the RER membrane. • C-terminal amino acid sequences (KDEL in soluble RER lumen proteins, KKXX in type I integral membrane proteins) are recognized by specific receptor proteins and retain the proteins in the ER
Lysosomal proteins • Lysosomal proteins are targeted to the lysosomes via the addition of a mannose 6 -phosphate signal that is added in the cis-compartment of the Golgi and is recognized by a receptor protein in the trans-compartment of the Golgi. • The protein is then transported by specialized vesicles to a late endosome that later matures into a lysosome. • The mannose 6 -phosphate receptor recycles back to the Golgi for re-use.
Mitochondrial and chloroplast proteins • • Most mitochondria and chloroplast proteins are made on free cytosolic ribosomes, released into the cytosol and then taken up into the organelle. Uptake into the mitochondrial matrix requires a matrixtargeting sequence and occurs at sites where the outer and inner mitochondrial membranes come into contact. The process is mediated by hsp 70 and hsp 60 proteins and requires both ATP hydrolysis and an electrochemical gradient across the inner mitochondrial membrane. Targeting of proteins to other compartments of mitochondria or chloroplasts requires two signals.
Nuclear proteins • Proteins destined for import into the nucleus typically require a nuclear localization signal, four to eight amino acids long, located internally in the protein. • Uptake occurs via nuclear pores and requires ATP hydrolysis.