Optimization The Cost Model and Estimating Result Sizes


")
: Number of tuples in each")




<NKeys(I 2) for attribute Y, then")
 – There is an index I")
-value)/(High(I)Low(I)) if there is an index I")
, Sailors(sid, rating) SELECT * FROM Reserves R, Sailors S WHERE")




 – dept(did, budget,")



![Creating an Index • Syntax: create [bitmap] [unique] index iname on table(column [, column].](https://slidetodoc.com/presentation_image_h/da07afffd3a4ccbd14ab878567adc73f/image-21.jpg "Creating an Index • Syntax: create [bitmap] [unique] index iname on table(column [, column].")
; • Create an index that will")







; – Create a cluster")















 */ sid From sailors Where sname=‘Joe’; Select /*+ INDEX")
- Slides: 49
Optimization The Cost Model and Estimating Result Sizes
Motivation (1( • We would like to find the cheapest way to calculate the join of three tables: Sailors Reserves Boats
Motivation (2( • We need to decide on the order of operations: (Sailors Reserves) Boats or Sailors (Reserves Boats) • We need to decide which join algorithm to use for each of the operations • What information do we need?
Statistics Maintained by DBMS for Relations • Cardinality NTuples(R): Number of tuples in each relation R • Size NPages(R) : Number of pages in each relation R
Statistics Maintained by DBMS for Indexes • Index Cardinality: Number of distinct key values NKeys(I) for each index I • Index Size: Number of pages INPages(I) in each index I • Index Height: Number of non-leaf levels IHeight(I) in each B+ Tree index I • Index Range: The minimum value ILow(I) and maximum value IHigh(I) for each index I
Note • The statistics are updated periodically (not every time the underlying relations are modified). • We cannot use the cardinality for computing select count(*) from R
Estimating Result Sizes • Consider SELECT attribute-list FROM relation-list WHERE term 1 and. . . and termn • The maximum number of tuples is the product of the cardinalities of the relations in the FROM clause • The WHERE clause is associating a reduction factor with each term. It reflects the impact of the term in reducing result size.
Result Size • Estimated result size: maximum size X the product of the reduction factors
Assumptions • Containment of value sets: if NKeys(I 1)<NKeys(I 2) for attribute Y, then every Y-value of R will be a Y-value of S • Empirically-obtained reduction factor is 1/10 if no additional info is available
Estimating Reduction Factors • column = value: 1/NKeys(I) – There is an index I on column. – This assumes a uniform distribution. – Otherwise, use 1/10. • column 1 = column 2: 1/Max(NKeys(I 1), NKeys(I 2)) – There is an index I 1 on column 1 and an index I 2 on column 2. – Containment of value sets assumption – If only one column has an index, we use it to estimate the value. – Otherwise, use 1/10.
Estimating Reduction Factors • column > value: (High(I)-value)/(High(I)Low(I)) if there is an index I on column.
Example Reserves (sid, agent), Sailors(sid, rating) SELECT * FROM Reserves R, Sailors S WHERE R. sid = S. sid and S. rating > 3 and R. agent = ‘Joe’ • Cardinality(R) = 100, 000 • Cardinality(S) = 40, 000 • NKeys(Index on R. agent) = 100 • High(Index on Rating) = 10, Low = 0
Example (cont(. • Maximum cardinality: 100, 000 * 40, 000 • Reduction factor of R. sid = S. sid: 1/40, 000 – sid is a primary key of S • Reduction factor of S. rating > 3: (10– 3)/(10 -0) = 7/10 • Reduction factor of R. agent = ‘Joe’: 1/100 • Total Estimated size: 700
Database Tuning
Database Tuning • Problem: Make database run efficiently • 80/20 Rule: 80% of the time, the database is running 20% of the queries – find what is taking all the time, and tune these queries
Solutions • Indexing – this can sometimes degrade performance, why? • Tuning queries • Reorganization of tables; perhaps "denormalization" • Changes in physical data storage
Denormalization • Suppose you have tables: – emp(eid, ename, salary, did) – dept(did, budget, address, manager) • Suppose you often ask queries which require finding the manager of an employee. You might consider changing the tables to: – emp(eid, ename, salary, did, manager) – dept(did, budget, address, manager) - in emp, there is a FD did -> manager. It is not 3 NF!
Creating Indexes Using Oracle
Index • Map between – the row key – the row location • Oracle has two kinds of indexes – B* tree – Bitmap • Sorted
B* tree Root 14 2* 3* 5* 7* 14* 16* 19 24 19* 20* 22* 33 24* 27* 29* 33* 34* 38* 39*
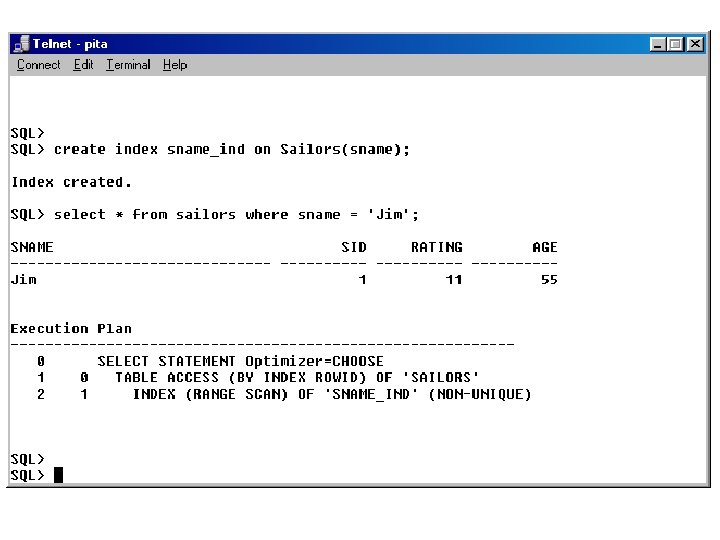
Creating an Index • Syntax: create [bitmap] [unique] index iname on table(column [, column]. . . )
Unique Indexes create unique index rating_bit on Sailors(rating); • Create an index that will guarantee the uniqueness of the key. Fail if any duplicate already exists. • When you create a table with a – primary key constraint or – unique constraint a "unique" index is created automatically
Bitmap Indexes • Appropriate for columns that may have very few possible values • For each value c that appears in the column, a vector v of bits is created, with a 1 in v[i] if the i-th row has the value c – Vector length = number of rows • Oracle can automatically convert bitmap entries to Row. IDs during query processing
Bitmap Indexes: Example Sid Sname age rating 12 Jim 55 3 13 John 46 7 14 Jane 46 10 15 Sam 37 3 create bitmap index rating_bit on Sailors(rating); • Corresponding bitmaps: – 3: <1 0 0 1> – 7: <0 1 0 0> – 10: <0 0 1 0>
When to Create an Index • Large tables, on columns that are likely to appear in where clauses as a simple equality • where s. sname = ‘John’ and s. age = 50 • where s. age = r. age
Function-Based Indexes • You can't use an index on sname for the following query: select * from Sailors where UPPER(sname) = 'SAM'; • You can create a function-based index to speed up the query: create index upp_sname on Sailors(UPPER(sname));
Index-Organized Tables • An index organized table keeps its data sorted by the primary key • Rows do not have Row. IDs • They store their data as if they were an index create table Sailors( sid number primary key, sname varchar 2(30), age number, rating number) organization index;
Index-Organized Tables (2( • What advantages does this have? – Primary key is not duplicated in the index – Improve performance of queries based on the primary key • What disadvantages? – expensive to add columns, dynamic data • When to use? – where clause on the primary key – static data
Clustering Tables Together • You can ask Oracle to store several tables with common columns together on the disk • This is useful if you often join these tables • Cluster: area on the disk where the rows of the tables are stored • Cluster key: the columns by which the tables are usually joined in a query
Clustering Tables Together: Syntax • create cluster sailor_reserves (X number); – Create a cluster with nothing in it • create table Sailors( sid number primary key, sname varchar 2(30), age number, rating number) cluster sailor_reserves(sid); – create the table in the cluster
Clustering Tables Together: Syntax (cont(. • create index sailor_reserves_index on cluster sailor_reserves – Create an index on the cluster • create table Reserves( sid number, bid number, day date, primary key(sid, bid, day) ) cluster sailor_reserves(sid); – A second table is added to the cluster
Sailors Reserves sid sname rating age sid bid day 22 Dustin 7 45. 0 22 102 7/7/97 31 Lubber 8 55. 5 22 101 10/10/96 58 Rusty 10 35. 0 58 103 11/12/96 Stored sid sname rating age bid day 22 Dustin 7 102 7/7/97 45. 0 101 10/10/96 31 Lubber 8 55. 5 58 Rusty 10 35. 0 103 11/12/96
The Oracle Optimizer
Types of Optimizers • There are different modes for the optimizer ALTER SESSION SET optimizer_mode = {choose|rule|first_rows(_n)|all_rows} • RULE: Rule-based optimizer (RBO) – deprecated • CHOOSE: Cost-based optimizer (CBO); picks a plan based on statistics (e. g. number of rows in a table, number of distinct keys in an index) – Need to analyze the data in the database using analyze command
Types of Optimizers • ALL_ROWS: execute the query so that all of the rows are returned as quickly as possible – Merge Join has priority over Block Nested Loop Join • FIRST_ROWS(n): execute the query so that all of the first n rows are returned as quickly as possible – Block Nested Loop Join has priority over Merge Join
Analyzing the Data analyze table | index <table_name> | <index_name> compute statistics | estimate statistics [sample <integer> rows | percent] | delete statistics; analyze table Sailors estimate statistics sample 25 percent;
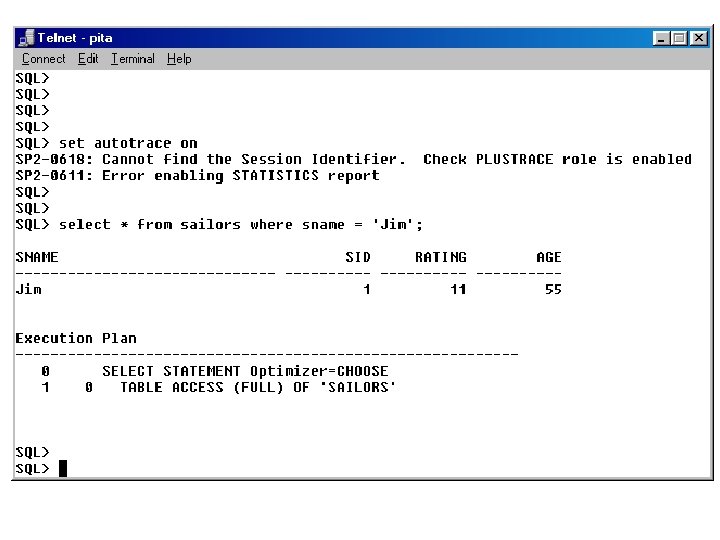
Viewing the Execution Plan (Option 1( • You need a PLAN_TABLE table. So, the first time that you want to see execution plans, run the command: @$ORACLE_HOME/rdbms/admin/utlxplan. sql • Set autotrace on to see all plans – Display the execution path for each query, after being executed
Viewing the Execution Plan (Option 2( explain plan set statement_id=‘<name>’ • Another option: for <statement> explain plan set statement_id='test' for SELECT * FROM Sailors S WHERE sname='Joe'; Select … from Plan_Table where statement_id=‘test’;
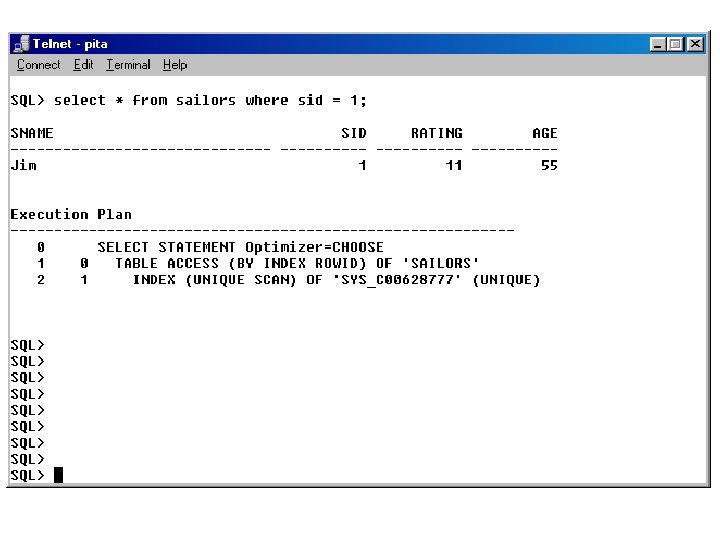
Operations that Access Tables • TABLE ACCESS FULL: sequential table scan – Oracle optimizes by reading multiple blocks – Used whenever there is no where clause on a query select * from Sailors • TABLE ACCESS BY ROWID: access rows by their Row. ID values. – How do you get the rowid? From an index! select * from Sailors where sid > 10
Types of Indexes • Unique: each row of the indexed table contains a unique value for the indexed column • Nonunique: the row’s indexed values can repeat
Operations that Use Indexes • INDEX UNIQUE SCAN: Access of an index that is defined to be unique • INDEX RANGE SCAN: Access of an index that is not unique or access of a unique index for a range of values
When are Indexes Used/Not Used? • If you set an indexed column equal to a value, e. g. , sname = 'Jim' • If you specify a range of values for an indexed column, e. g. , sname like 'J%' – sname like '%m': will not use an index – UPPER(sname) like 'J%' : will not use an index – sname is null: will not use an index, since null values are not stored in the index – sname is not null: will not use an index, since every value in the index would have to be accessed
When are Indexes Used? (cont( • 2*age = 20: Index on age will not be used. Index on 2*age will be used. • sname != 'Jim': Index will not be used. • MIN and MAX functions: Index will be used • Equality of a column in a leading column of a multicolumn index. For example, suppose we have a multicolumn index on (sid, bid, day) – sid = 12: Can use the index – bid = 101: Cannot use the index
Optimizer Hints • You can give the optimizer hints about how to perform query evaluation • Hints are written in /*+ */ right after the select • Note: These are only hints. The Oracle optimizer can choose to ignore your hints
Hints • FULL hint: tell the optimizer to perform a TABLE ACCESS FULL operation on the specified table • ROWID hint: tell the optimizer to perform a TABLE ACCESS BY ROWID operation on the specified table • INDEX hint: tells the optimizer to use an indexbased scan on the specified table
Examples Select /*+ FULL (sailors) */ sid From sailors Where sname=‘Joe’; Select /*+ INDEX (sailors s_ind) */ sid From sailors S, reserves R Where S. sid=R. sid AND sname=‘Joe’;