Nonparametric and Resampling Statistics Wilcoxon RankSum Test To





















.")







- Slides: 32
Nonparametric and Resampling Statistics
Wilcoxon Rank-Sum Test • • To compare two independent samples Null is that the two populations are identical The test statistic is Ws , Table of Critical Vals. For large samples, there is a normal approx. Is equivalent to the Mann-Whitney test. Assumptions are different from those of t. Rank the scores and sum the ranks in each group. • See handout and text for details on computation.
Assumptions
Summary Statement A Wilcoxon rank-sum test indicated that babies whose mothers started prenatal care in the first trimester weighed significantly more (N = 8, M = 3259 g, Mdn = 3015 g, s = 692 g) than did those whose mothers started prenatal care in the third trimester (N = 10, M = 2576 g, Mdn = 2769 g, s = 757 g), W = 52, p =. 034.
Power • If the assumptions of t are met, power will be a little greater with t than with W. • When the assumptions of t are not met, power may be greater with W. • Nana & Sawilowsky showed this to be the case with typical Likert scale data. • What is a Likert scale and how do you pronounce “Likert? ”
Wilcoxon’s Signed-Ranks Test • Two related groups. • Rank the absolute values of the difference scores. Sum of + ranks, sum of – ranks. • See handout and text for computational details. • The test statistic is T. • Table of Critical Values in text. • There is a normal approximation for large samples.
Assumption • The WSRT assumes that the difference scores are symmetrically distributed. • If they are distinctly skewed, this test is not valid. • One alternative is the binomial sign test. • I prefer a resampling test.
Summary Statement A Wilcoxon signed-ranks test indicated that participants who were injected with glucose had significantly better recall (M = 7. 62, Mdn = 8. 5, s = 3. 69) than did subjects who were injected with saccharine (M = 5. 81, Mdn = 6, s = 2. 86), T(N = 16) = 14. 5, p =. 004.
Kruskal-Wallis ANOVA • Two or more independent samples. • Rank the data, sum the ranks in each group. • Compute H (see text and handout). • Evaluate H as a chi-square on k-1 df. • Pairwise comparisons with Wilcoxon Rank Sum • Fisher’s procedure or Bonferroni to cap FW
Summary Statement Kruskal-Wallis ANOVA indicated that type of drug significantly affected the number of problems solved, H(2, N = 19) = 10. 38, p =. 006. Pairwise comparisons made with Wilcoxon’s rank-sum test revealed that. .
Friedman’s ANOVA • Two or more related groups. • Rank the scores within each block. • Compute F 2 on k-1 df (see text and handout) • Pairwise comparisons with Wilcoxon Signed Ranks. • Fisher’s procedure or Bonferroni to cap FW
Summary Statement Friedman’s ANOVA indicated that judgments of the quality of the lectures were significantly affected by the number of visual aids employed, 2(2, n = 17) = 10. 94, p =. 004. Pairwise comparisons with Wilcoxon signed-ranks tests indicated that. . .
SAS • Run the program Nonpar. sas from my SAS programs page
Wilcoxon Rank Sum • SAS reports the sum of ranks in each group • It gives both an exact p and a p from a normal approximation. • For the normal approximation, it makes a correction for continuity. • SAS Output
Wilcoxon Matched Pairs Signed-Ranks Test • Compute difference scores. • Point Proc Univariate to the difference scores. • SAS reports S, the signed rank statistic • This can be converted to T, see the handout. • A binomial sign test is also provided. • SAS Output
Kruskal-Wallis ANOVA • The sums and means reported by SAS are for the ranks, not the original scores. • I used subsetting IF statements to produce three data sets for the pairwise comparisons. – data kr 12; set kruskal; if group < 3; – data kr 23; set kruskal; if group > 1; – data kr 13; set kruskal; if group NE 2; – SAS Output
Friedman’s Rank Test for Correlated Samples • Use Proc Rank to create the ranked data. • Cochran-Mantel-Haenszel Statistic from Proc Freq is the test statistic. • An alternative analysis is a Factorial ANOVA on the ranks. – One IV is the blocks, the other is the Treatment. – Can easily get pairwise contrasts with this approach – SAS Output
Resampling Statistics • The sampling distributions here are created from the actual data set. • The approach is simple, but computerintensive. • We shall use the software provided free by David Howell. • See http: //core. ecu. edu/psyc/wuenschk/Stat. Help/Resampling. htm
Bootstrapping • Confidence Interval for a Median • We assume that the population is distributed exactly as is the sample. • We randomly draw one score from the sample of 20. We record it, replace it, and draw another. We repeat this process 20 times (20 because there are 20 scores in the sample). We compute the median of the obtained resample and record it.
• We repeat this process, obtaining a second sample of 20 scores and computing and recording a second median. • We continue until we have obtained a large number (10, 000 or more) of resample medians. We obtain the probability distribution of these medians and treat it like a sampling distribution. • From the obtained resampling distribution, we find the. 025 and the. 975 percentiles. These define the confidence limits.
• Follow My Instructions
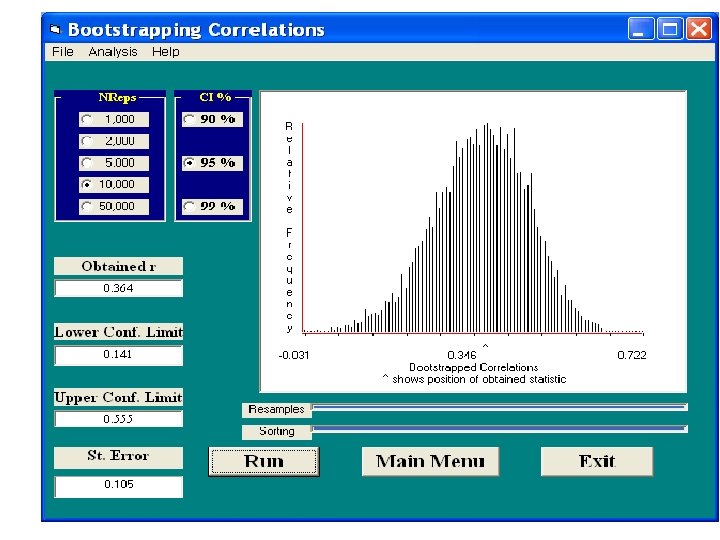
Confidence Interval for Pearson r • Correlation between misanthropy and attitude about animals (nonidealists). • Sample, with replacement, from our actual sample (n = 123), 123 pairs of scores. • Compute Pearson r on that sample of 123 pairs of scores and then record the value of r. • Repeat this process many times, each time recording the value of r.
• From the resulting resampling distribution of values of r, we obtain the. 025 and. 975 percentiles. This is the confidence interval for our sample r. • Follow My Instructions
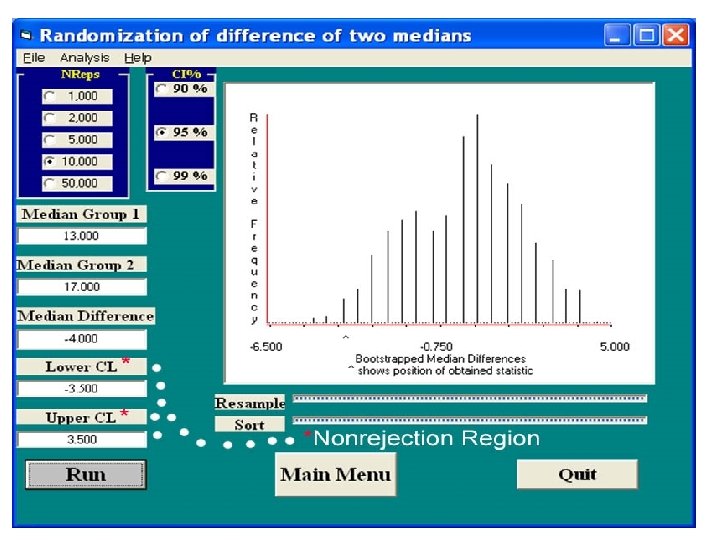
Permutation/Randomization Tests • Two Independent Samples • We take all 49 + 18 = 67 scores and throw them into one pot. • After mixing them, we select one score and assign it to the success group. • Without replacing it, we select a second score and assign it to the success group.
• We continue this until we have assigned 49 scores to the success group. The remaining 17 scores are assigned to the fail group. • We compute the medians of the resulting groups and then the difference between those medians. We record the difference in medians. • We put the 67 scores back in the pot and repeat the process, obtaining and recording a second difference in medians for the resulting sample of 49 scores assigned to one group, 17 to the other group.
• We repeat this procedure a large number of times. The resulting set of differences in medians is our resampling distribution under the null of no difference in population medians. • We map out the nonrejection region (typically the middle 95% of the resampling distribution. • If the observed difference in sample medians falls outside of the nonrejection region, then the difference is significant. • Follow My Instructions
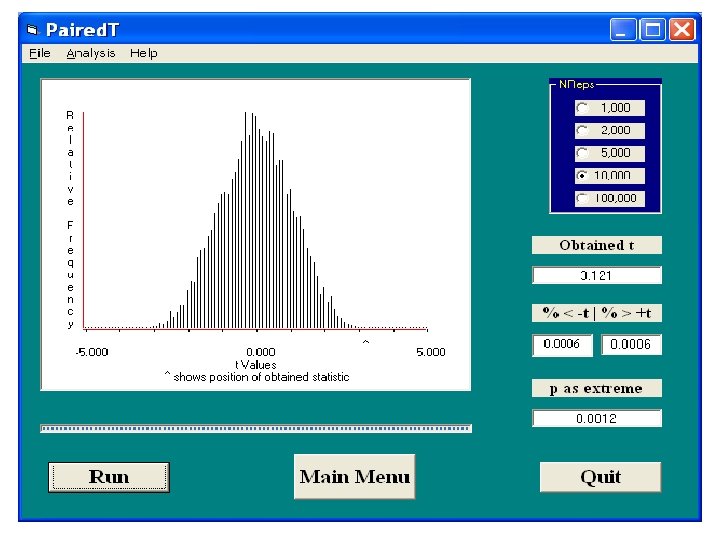
Two Correlated Samples • We conduct a one-sample t test of the null that the mean difference score is zero. • For our data, t = 3. 121. If we refer this to the distribution of Student's t, we obtain p =. 006, but we are not going to use Student's t. • We are going to construct our own resampling distribution of t.
• We take the 19 difference scores, strip them of their signs, and then randomly assigns to them. • We then compute and record a onesample t for the resulting distribution of difference scores. • We repeat this process a large number of times.
• From the resulting sampling distribution under the null hypothesis of no difference in population means (that is, a mean difference score of 0), we compute our p value by finding what proportion of the resampled t values differ from 0 by at least as much as did the t from our actual samples. • Follow My Instructions