Map Reduce Simplified Data Processing on Large Clusters






. E. g. key")
: // input_key: document name // input_value:")
: // input_key: query log name // input_value:")









 functions run in parallel, creating different intermediate values from different input data")
 tasks Re-executes in-progress")





 mod R” Can be customized: E. g. “hash (Hostname(urlkey))")

 3 -character pattern")

 M =")

- Slides: 35
Map. Reduce: Simplified Data Processing on Large Clusters By Dinesh Dharme
Map. Reduce
Motivation: Large Scale Data Processing Want to process lots of data ( > 1 TB) Size of web > 400 TB Want to parallelize across hundreds/thousands of CPUs. Commodity CPUs have become cheaper. Want to make this easy. Favour programmer productivity over CPU efficiency.
What is Map. Reduce? More simply, Map. Reduce is: A parallel programming model and associated implementation. Borrows from functional programming Many problems can be modeled based on Map. Reduce paradigm
Map. Reduce Features Automatic parallelization & distribution Fault-tolerant Load balancing Network and disk transfer optimization Provides status and monitoring tools Clean abstraction for programmers Improvements to core library benefit all users of library!
Steps in typical problem solved by Map. Reduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize, filter, or transform Write the results Outline stays the same,
Map. Reduce Paradigm Basic data type: the key-value pair (k, v). E. g. key = URL, value = HTML of web page. Users implement interface of two functions: Map: (k, v)↦ <(k 1, v 1), (k 2, v 2), (k 3, v 3), . . . , (kn, vn)> Reduce: (k', <v'1, v'2, . . . , v'n'>)↦ <(k', v''1), (k', v''2), . . . , (k', v''n'')> (typically n'' = 1) All v' with same k' are reduced together.
Example: Count word occurrences map(String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: Emit. Intermediate(w, "1"); reduce(String output_key, Iterator intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += Parse. Int(v); Emit(As. String(result));
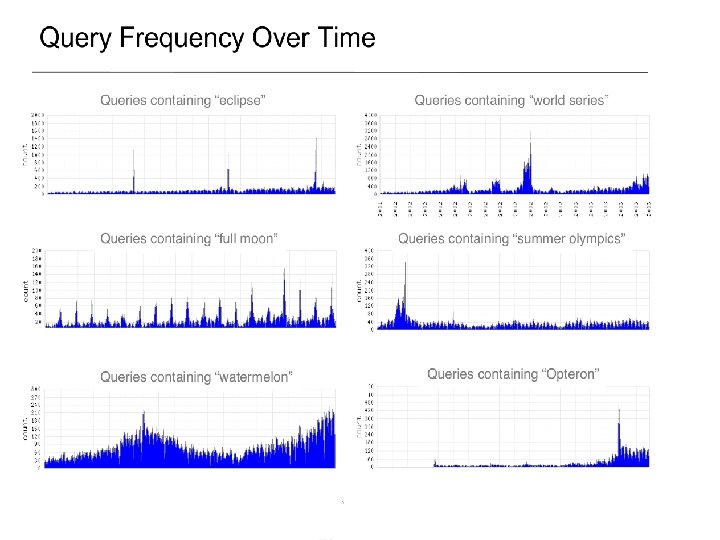
Example: Query Frequency map(String input_key, String input_value): // input_key: query log name // input_value: query log content for each query q in content: if(substring(“full moon”, q)): Emit. Intermediate(issue_time, "1"); reduce(String output_key, Iterator intermediate_values): // output_key: issue_time // output_values: a list of counts int result = 0; for each v in intermediate_values: result += Parse. Int(v); Emit(issue_time, As. String(result));
More Examples: Distributed Grep Count of URL Access Frequency Suggesting terms for query expansion Distributed Sort.
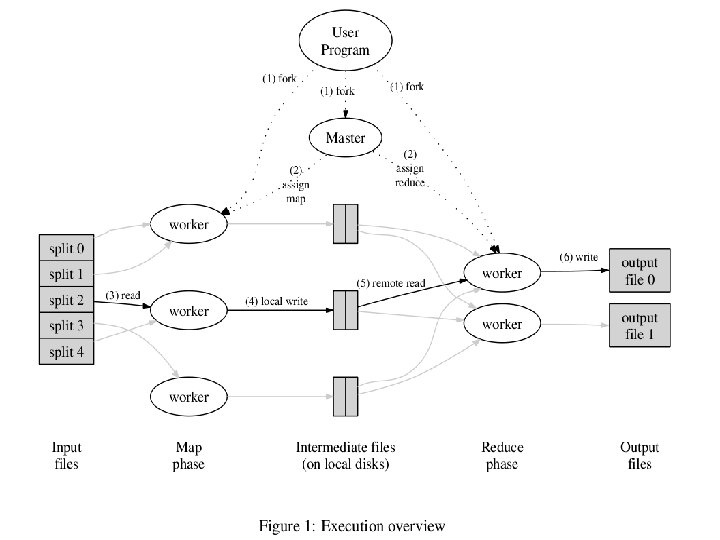
Execution Create M splits of input data User provides R i. e # of partitions or # of output files Master Data Structure: Keeps track of state of each map and reduce task.
Locality Master program divides up tasks based on location of data: tries to have map() tasks on same machine as physical file data, or at least same rack map() task inputs are divided into 64 MB blocks: same size as Google File System chunks
Parallelism map() functions run in parallel, creating different intermediate values from different input data sets reduce() functions also run in parallel, each working on a different output key All values are processed independently Bottleneck: reduce phase can’t start until map phase is completely finished.
Fault Tolerance Master detects worker failures Re-executes completed & in-progress map() tasks Re-executes in-progress reduce() tasks Master notices particular input key/values cause crashes in map(), and skips those values on re-execution. Effect: Can work around bugs in third-party libraries!
Fault Tolerance contd. What if the Master fails? Create a checkpoint and note the state of Master Data Structure Write the state to GFS filesystem New master recovers and continues
Semantics in Presence of Failures Deterministic map and reduce operators are assumed. Atomic commits of map and reduce task outputs Relies on GFS
Semantics in Presence of Failures contd. What if map/reduce operators are nondeterministic? In this case, Map. Reduce provides weaker but reasonable semantics.
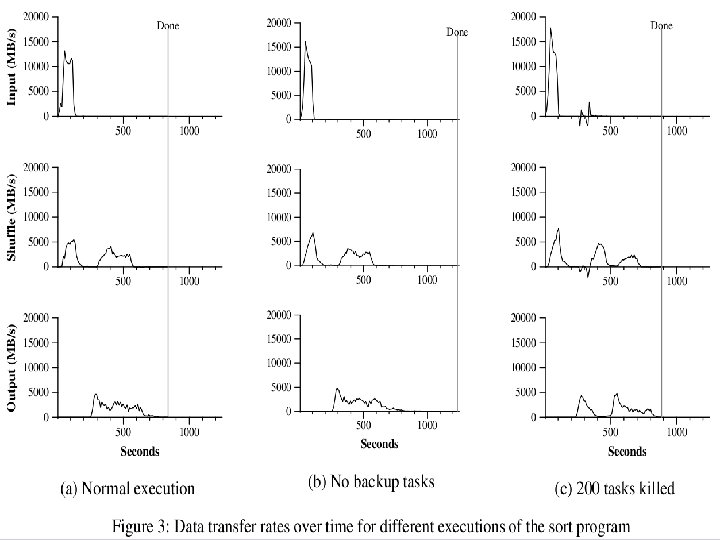
Optimizations No reduce can start until map is complete: A single slow disk controller can rate-limit the whole process Master redundantly executes “slowmoving” map tasks; uses results of first copy to finish Performed only when close to completion Why is it safe to redundantly execute map tasks? Wouldn’t this mess up the total computation?
Fine tuning Partitioning Function Ordering Guarantees Combiner function Bad Record Skipping Status Information Counters
Partitioning Function Default : “hash(key) mod R” Can be customized: E. g. “hash (Hostname(urlkey)) mod R” Distribution of keys can be used to determine good partitions.
Combiner Function Runs on same machine as a map task Causes a mini-reduce phase to occur before the real reduce phase Saves bandwidth
Performance Grep 1800 machines 1010 100 byte records. (~ 1 TB) 3 -character pattern to be matched ( ~ 1 lakh records contain the pattern ) M = 15000 R=1 Input data chunk size = 64 MB
Performance: Grep
Performance Sort 1800 machines used 1010 100 byte records. (~ 1 TB) M = 15000 R = 4000 Input data chunk size = 64 MB 2 TB of final output (GFS maintains 2 copies)
Map. Reduce Conclusions Map. Reduce has proven to be a useful abstraction Greatly simplifies large-scale computations at Google. Indexing code rewritten using Map. Reduce. Code is simpler, smaller, readable.