Lecture 10 Term Translation Extraction CrossLanguage Information Retrieval
 Department of")


 – Cross-language information")






,")
 • Web mining for cross-language Web search – ROCLING’ 03,")

 • Summary of contributions – Present an innovative approach •")
")
 • Query translation for cross-language information retrieval – Dictionary-/MT-based approach")
 • Cross-language Web search (CLWS) – Practical CLWS services have")

 – The descriptive text of a link")






 •")



 新力")
 – t 1 co-occurs often")
 algorithm (Melamed 2000) – Determine")


 Direct_Translation_with_CL (s, U, Vt) Input: source term")

 藍鳥 (Bluebird) 迪士尼 (Disney) Top-5")











 –")





- Slides: 65
Lecture 10: Term Translation Extraction & Cross-Language Information Retrieval Wen-Hsiang Lu (盧文祥) Department of Computer Science and Information Engineering, National Cheng Kung University 2004/11/24 References: • Wen-Hsiang Lu (Advisors: Lee-Feng Chien and Hsi-Jian Lee. ) (2003) Term Translation Extraction Using Web Mining Techniques, Ph. D thesis, Department of Computer Science and Information Engineering, National Chiao Tung University.
Outline I. III. IV. Background & Research Problems Anchor Text Mining for Term Translation Extraction Transitive Translation for Multilingual Translation Web Mining for Cross-Language Information Retrieval and Web Search Applications
Part I Background & Research Problems
Motivation • Demands on multilingual translation lexicons – Machine translation (MT) – Cross-language information retrieval (CLIR) – Information exchange in electronic commerce (EC) • Web mining – Explore multilingual and wide-scoped hypertext resources on the Web
Research Problems • Difficulties in automatic construction of multilingual translation lexicons – Techniques: Parallel/comparable corpora – Bottlenecks: Lacking diverse/multilingual resources • Difficulties in query translation for cross-language information retrieval (CLIR) [Fig 1] – Techniques: Bilingual dictionary/machine translation/ parallel corpora – Bottlenecks: Multiple-senses/short/diverse/unknown query [Fig 2]
Cross-Language Information Retrieval • Query in source language and retrieve relevant documents in target languages Source Query Translation Target Translation Information Retrieval Hussein 海珊/侯賽因/哈珊/胡笙 (TC) 侯赛因/海珊/哈珊 (SC) Target Documents
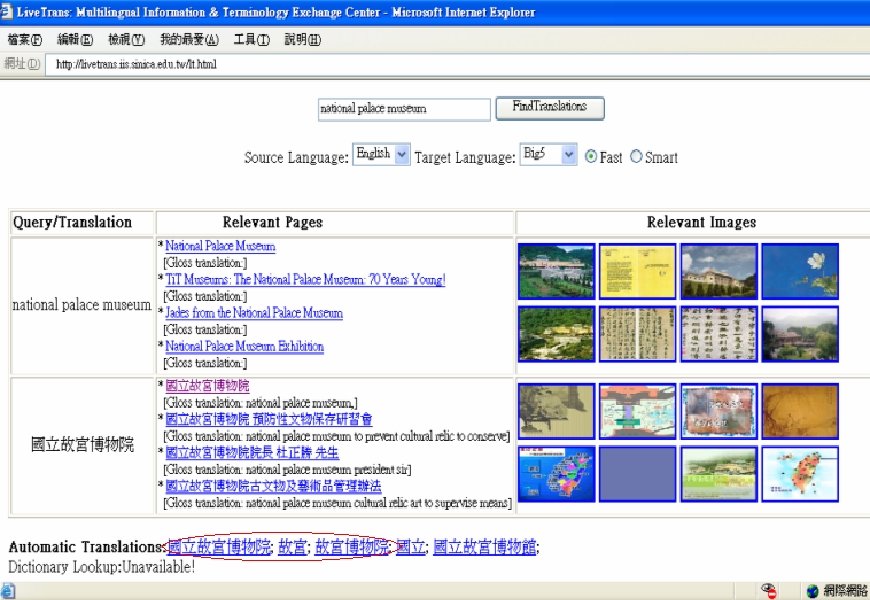
Difficulties in Query Translation using Machine Translation Systems Chinese translation: 全國宮殿博物館 English source query : National Palace Museum
Research Paradigm New approach Live Translation Lexicon Web Mining Anchor-Text Mining Internet Search-Result Mining Term-Translation Extraction Applications Cross-Language Information Retrieval Cross-Language Web Search
Multilingual Anchor Texts & Hyperlink Structure
Language-Mixed Texts in Search Result Pages
Research Results • Anchor text mining for term translation extraction – ACM SIGIR’ 01(poster), IEEE ICDM’ 01, ACM Trans. on Asian Language Information Processing 2002 – Reviewers’ encouraging comments • “… the approach seems to be quite novel. To my knowledge, there has not been a proposal of uses of anchor texts like this one. ” • Transitive translation for multilingual translation – COLING’ 02, ACM Trans. on Information Systems (first paper from Taiwan since 1986), ACL’ 04 – Reviewers’ encouraging comments • “This is a nicely written, technically sound paper that pursues a clever and original idea …” • “… the idea of using anchor texts from the Web to learn cross-lingual information retrieval algorithms is very good …” • “I enjoyed the paper and thought the underlying work was interesting and valuable …”
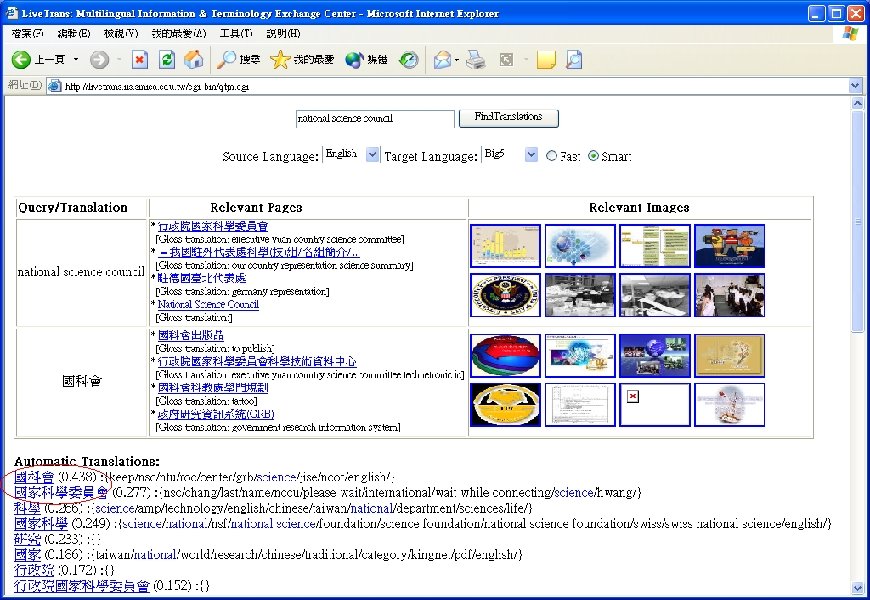
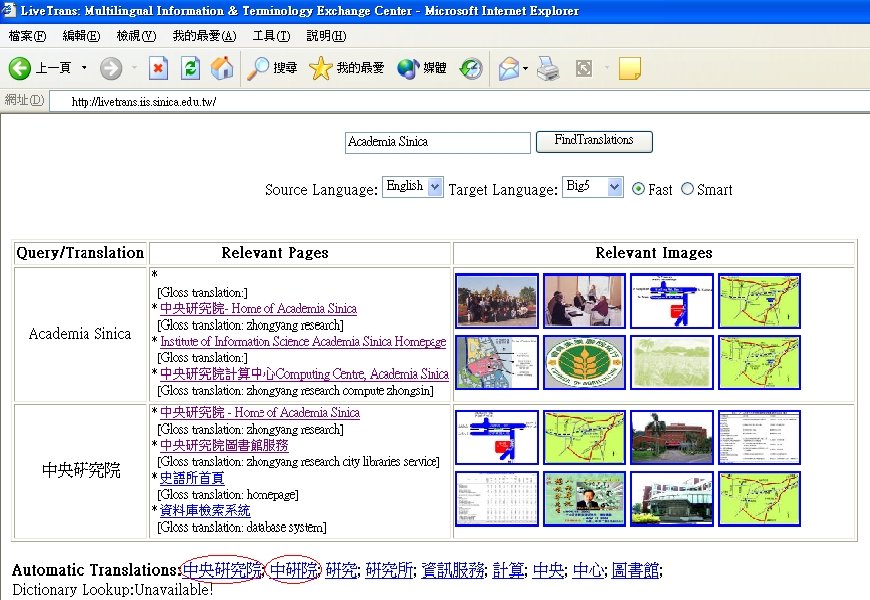
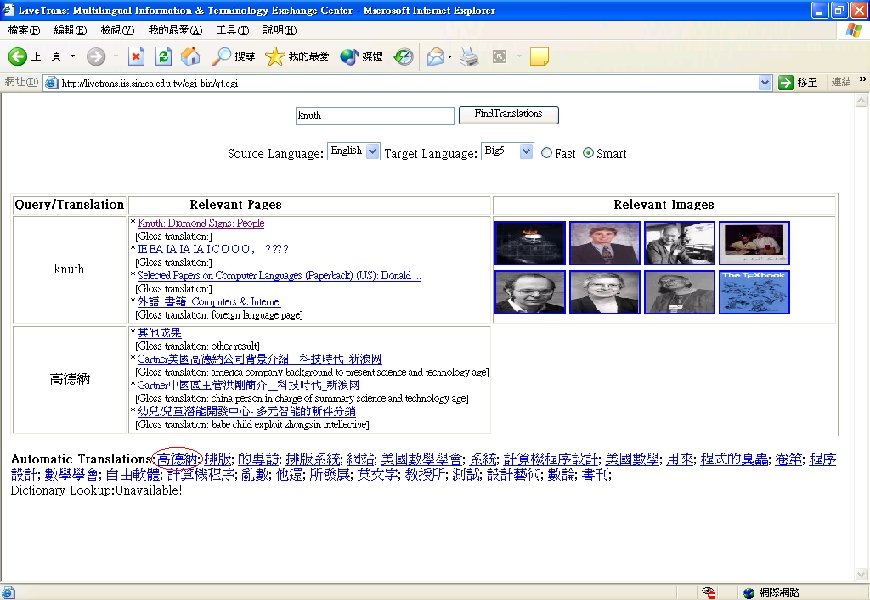
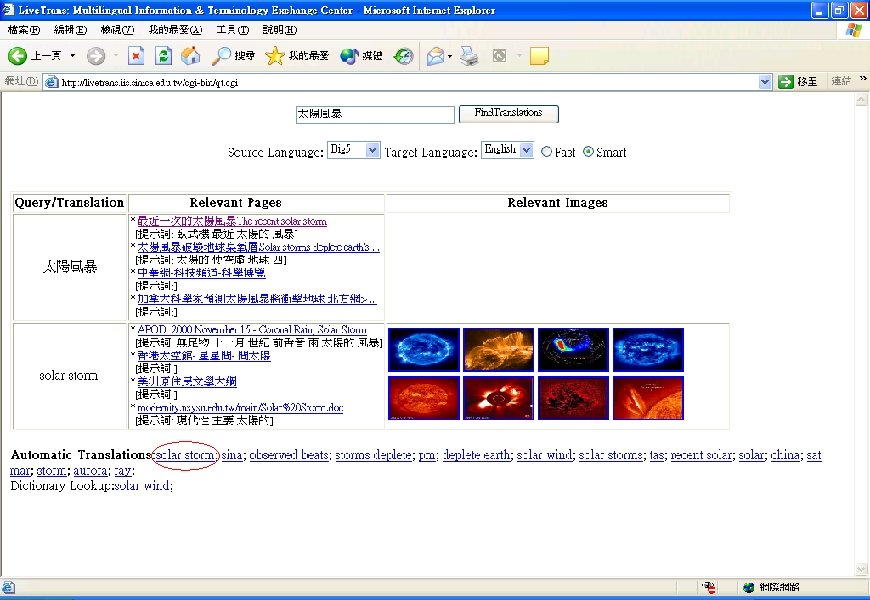
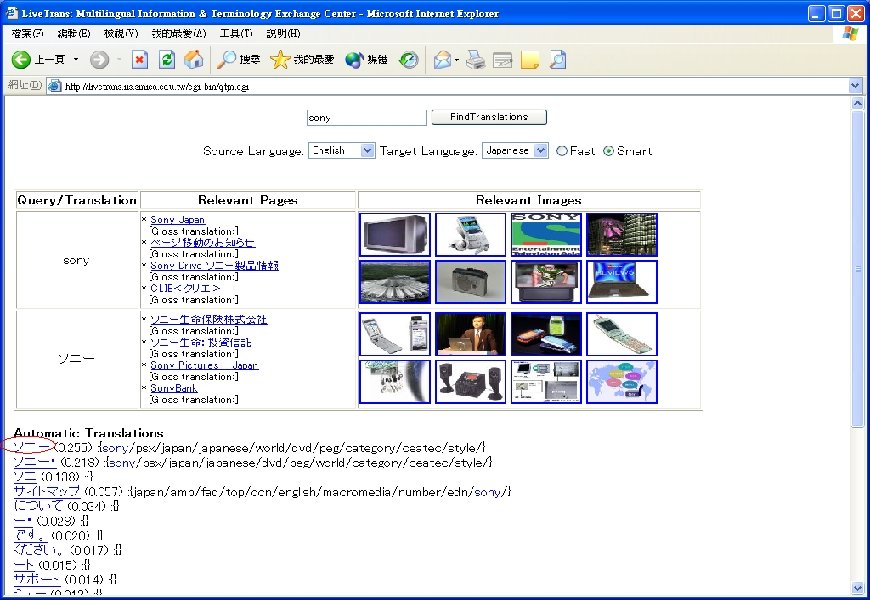
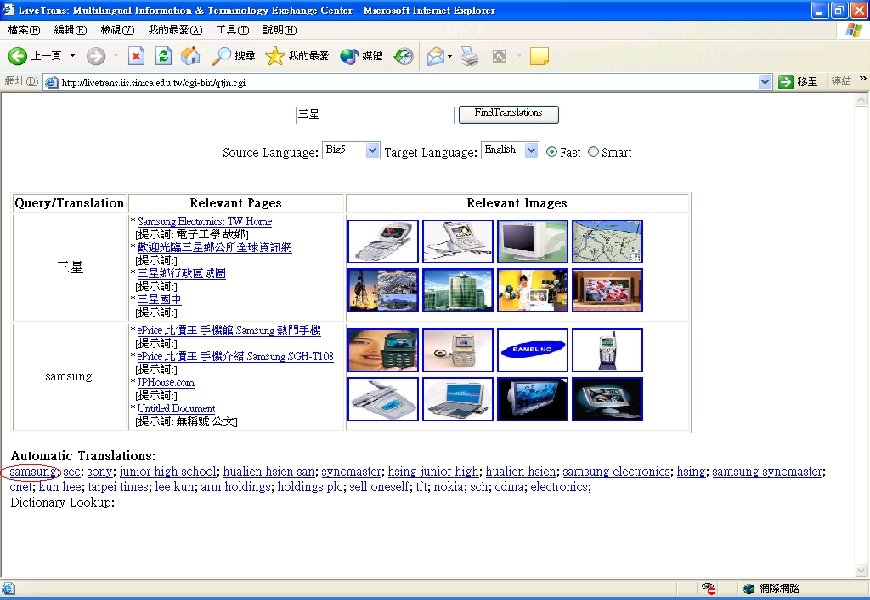
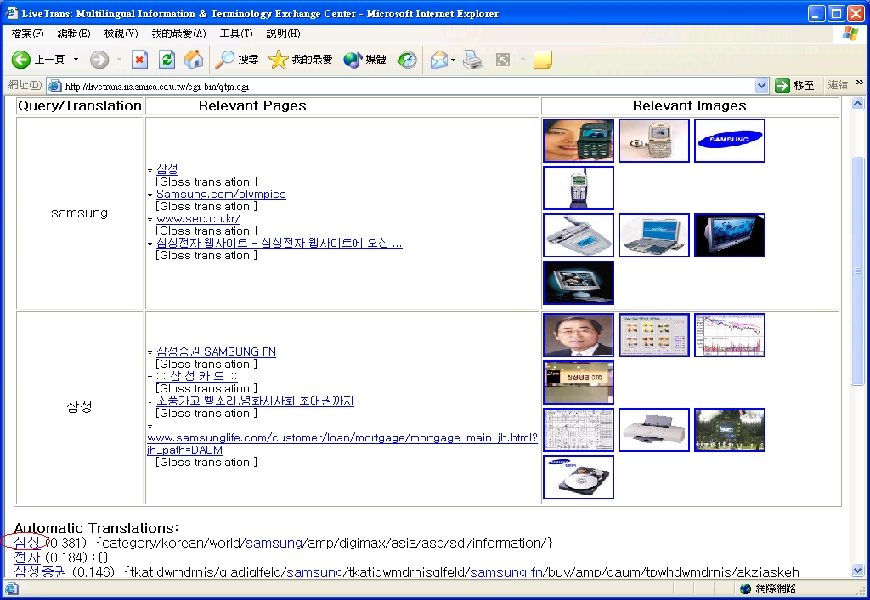
Research Results (cont. ) • Web mining for cross-language Web search – ROCLING’ 03, ACM SIGIR’ 04 – Improve precision rate from 0. 207 (dictionary-based) to 0. 241 on NTCIR-2 Chinese-English CLIR evaluation task – Reviewers’ encouraging comments • “It gives us insight into the value of the Web as a dynamic information source. Although the experiments are restricted to Chinese-English documents, also developers for other languages may find this work stimulating. ” • “The idea is interesting, and is relatively new. It may give inspiration to other researchers working in the same area. ” • Live. Trans: Experimental CLWS system [Live. Trans]
Live. Trans: Cross-Language Web Search System • http: //livetrans. iis. sinica. edu. tw/lt. html [Live. Trans] – Mirror: http: //wmmks. csie. ncku. edu. tw/lt. html [Live. Trans] • System functions – Query-translation suggestion – Retrieval of Web pages and images. – Multilingual search: English, traditional Chinese, simplified Chinese, Japanese or Korean – Gloss translation for retrieved page titles – Fusion of retrieval results
Research Results (cont. ) • Summary of contributions – Present an innovative approach • Significantly reduce the difficulty of unknown-term translation. • CLIR can be improved especially for short queries. – Develop a practical cross-language Web search engine • Without relying on translation dictionary • A live dictionary with a significant number of multilingual term translations obtained. – Present a new problem for further investigation in Web Mining
Related Research • Automatic extraction of multilingual translations – Statistical translation model (Brown 1993) – Parallel corpus (Melamed 2000; Wu & Chang 2003) – Non-parallel/comparable corpus (Fung 1998; Rapp 1999) – Web mining • Parallel corpus collection (Nie 1999; Resnik 1999) • Comparable corpus collection: Anchor texts and search-result pages (Lu et al. 2002, 2003) • Strength: Huge amounts of Web data with link structure
Related Research (cont. ) • Query translation for cross-language information retrieval – Dictionary-/MT-based approach (Ballesteros & Croft 1997; Hull & Grefenstette 1996) – Corpus-based approach (Dumais 1997; Nie 1999) – Combined approach (Chen & Bian 1999; Kwok 2001) – Improving techniques • • Query expansion and phrase translation (Ballesteros & Croft 1997) Translation disambiguation (Ballesteros & Croft 1998; Chen & Bian 1999) Proper name transliteration (Chen et al. 1998; Lin & Chang 2003) Probabilistic retrieval/language models (Hiemstra & de Jong 1999; Lavrenko 2002) • Unknown query translation (Lu et al. 2002, 2003)
Related Research (cont. ) • Cross-language Web search (CLWS) – Practical CLWS services have not lived up to expectations • Keizai (Ogden et al. 1999): English query/Japanese, Korean Web news • MTIR (Bian & Chen 1999): Chinese query/English pages/translation • Mu. ST: Multilingual Summarization and Translation (Hovy & Lin 1998) – English/Indonesian/Spanish/Arabic/Japanese, Web news summarization or translation • TITAN (Hayashi et al. 1997): English-Japanese retrieval/translated pages titles • Challenges – Web queries are often • Short: 2 -3 words (Silverstein et al. 1998) • Diverse: wide-scoped topic • Unknown (out of vocabulary): 74% is unavailable in CEDICT Chinese-English electronic dictionary containing 23, 948 entries. – E. g. • Proper name: 愛因斯坦 (Einstein), 海珊 (Hussein) • New terminology: 嚴重急性呼吸道症候群 (SARS), 院內感染 (Nosocomial infections)
Part II Anchor Text Mining for Term Translation Extraction
Anchor-Text Set • Anchor text (link text) – The descriptive text of a link on a Web page • Anchor-text set – A set of anchor texts pointing to the same page (URL) – Multilingual translations 야후-USA Korea Yahoo Search Engine Yahoo! America http: //www. yahoo. com 美国雅虎 − Yahoo/雅虎/야후 − America/美国/アメリカ • Anchor-text-set corpus – A collection of anchor-text sets アメリカのYahoo! 雅虎搜尋引擎 Taiwan China Japan
Processing of Term Translation Extraction Source Query Term Collect Web pages and build up anchor-textset corpus. Target Translation Anchor-Text-Set Translation Corpus Lexicon Anchor-Text Extraction Web Pages Term Translation Extraction Term Extraction Web Spider Compute similarity using probabilistic inference model. Term Similarity Estimation Internet Extract key terms as translation candidate.
Example for Term Translation Extraction s: Source Query Term Yahoo t: Target Translations Term Translation Extraction 雅虎 -Yahoo in USA (#in-link= 187) . . . www. yahoo. com Set u 1 . . . . 雅虎 搜尋引擎 Taiwan Yahoo(#in-link= 21) . . . www. yahoo. com. tw Co-occurrence Set u 2 雅虎 台灣 Chinese-English Anchor-Text-Set Corpus Page Authority
Probabilistic Inference Model • Asymmetric translation models: • Symmetric model with link information: Conventional translation model Co-occurrence Page authority
Experimental Environment • Anchor-text-set corpora – 109, 416 traditional-Chinese-English sets (from 1, 980, 816 pages) – 157, 786 simplified-Chinese-English sets (from 2, 179, 171 pages) • Test query set – Query logs: • Dreamer log: 228, 566 unique query terms • GAIS log: 114, 182 unique query terms – Core terms: 9, 709 most popular query terms, frequencies >10 in two logs – Test set: 622 English terms selected from core terms • Average top-n inclusion rate (ATIR)
Performance with Different Estimation Models • Using different models – – MA: Asymmetric model MAL: Asymmetric model with link information MS: Symmetric model MSL: Symmetric model with link information • The symmetric inference model with link information was useful to improve the translation accuracy.
Performance with Different Term Extraction Methods and Query-Log-Set Sizes • The query-log-based method achieved better performance. • The medium-sized query-log set achieved the best performance
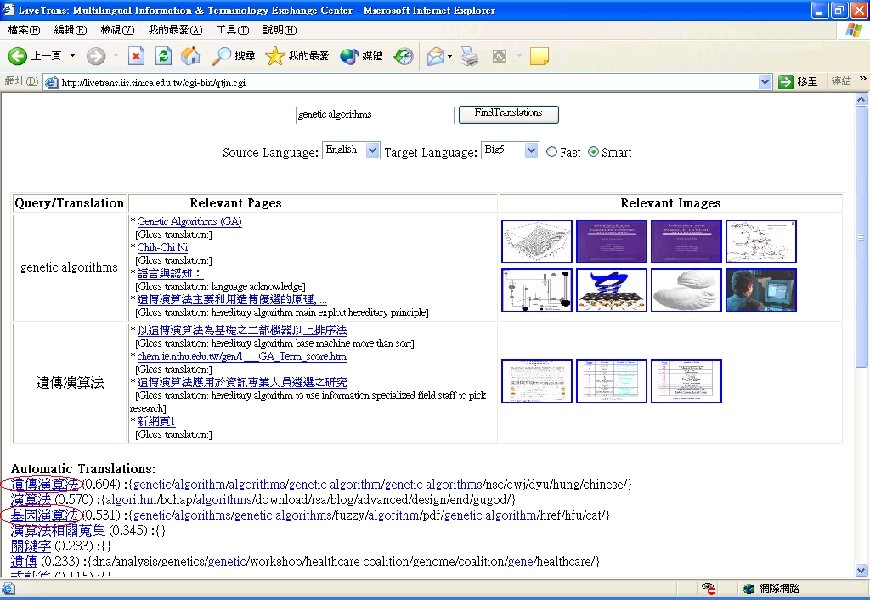
Performance Comparison • Example: Test term "sakura“ – Query-log set (9, 709 terms) • Top 5 extracted translations: 台灣櫻花, 蜘蛛網, 純愛, 螢幕保護 – Query-log set (228, 566 terms) • Top 10 extracted translations: 庫洛魔法使, 櫻花建設, 模仿, 櫻花大戰, 美夕, 台灣櫻花, 櫻 花, 蜘蛛網, 純愛, 螢幕保護 • Test results of 9, 709 core terms [TTE 9709] • Promising results Source terms (English) Yahoo Nike Ericsson Stanford Sydney Star Wars internet Extracted target translations Traditional Chinese 雅虎 耐吉 易利信 史丹佛 雪梨 星際大戰 網際網路 Simplified Chinese 雅虎 耐克 爱立信 斯坦福 悉尼 星球大战 互联网
Part III Transitive Translation for Multilingual Translation
Transitive Translation for Multilingual Translation • Problem – Insufficient anchor-text-set corpus for certain language pairs – E. g. , Chinese-Japanese, Chinese-French, etc. • Goal – A generalized model for multilingual translation • Idea – Transitive translation model: Extract translations via intermediate (third) language, e. g. , English (Borin 2000; Gollins & Sanderson 2001) – To reduce interference errors, integrates a competitive linking algorithm.
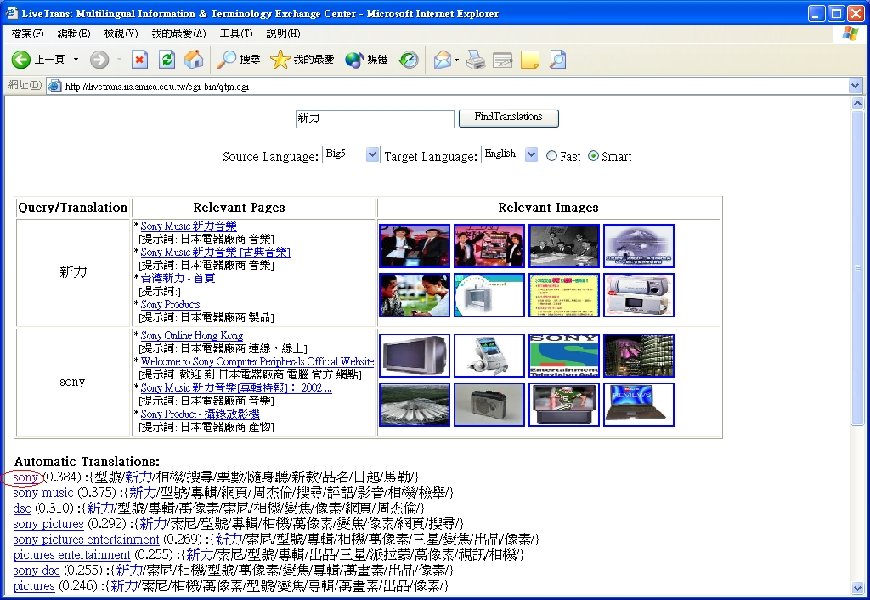
Transitive Translation: Combining Direct and Indirect Translation • Direct Translation Model Direct Translation s 新力 (Traditional Chinese) t ソニー (Japanese) • Indirect Translation Model m Sony (English) Indirect Translation … • Transitive Translation Model s : source term t : target translation m: intermediate translation
Promising Results for Automatic Construction of Multilingual Translation Lexicons Source terms (Traditional Chinese) 新力 耐吉 史丹佛 雪梨 網際網路 網路 首頁 電腦 資料庫 資訊 English Sony Nike Stanford Sydney internet network homepage computer database information Simplified Chinese 索尼 耐克 斯坦福 悉尼 互� 网 网� 主� � 算机 数据� 信息 Japanese ソニー ナイキ スタンフォード シドニー インターネット ネットワーク ホームページ コンピューター データベース インフォメーション
Indirect Association Problem • Indirect association error (Melamed 2000) – t 1 co-occurs often with s than t – E. g. , 思科 system (translation error) s 思科 0. 11 system t 1 0. 07 Cisco t
Competitive Linking Algorithm • Concepts of competitive linking (CL) algorithm (Melamed 2000) – Determine the most possible translation pairs between source and target sets. – Assumption: each term has only one translation. – Method: • Greedily select the most possible edges. • Select less possible edges when no conflicting with previous selections. • Integration of anchor-text-mining and CL Algorithm 1. Build a bipartite graph using our proposed translation model. 2. Use the extended CL algorithm to filter out indirect association errors.
Bipartite Graph Construction S Step 1 s 思科 system t 1 Cisco s t 2 Step 2 思科 系統 St 1 T system t 1 Cisco t 2 資訊 網路 St 2 電腦 Bipartite graph G = (S∪T, E)
Extended Competitive Linking Algorithm • Pick up k most possible translations for a source term Step 2 Step 1 s 0. l 1 思科 system t 1 s 思科 system t 1 0. 07 0. 23 系統 St 1 資訊 網路 St 2 Cisco t 2 系統 0. 01 St 1 0. 03 0. 004 資訊 網路 St 2 電腦 電腦 Cisco t 2
Construct bipartite graph G = (S∪T, E) Direct_Translation_with_CL (s, U, Vt) Input: source term s Web pages of concern U translation vocabulary set Vt Output: target translation set R Compute edge weight wij Sort wij Choose edge ei*j* with highest weight N si* = s ? Remove all edges linking to si* or tj* Re-estimate wij for remaining edges N Y R = R ∪{tj*} |R| = k ? Y N Remove all edges linking to tj* Re-estimate wij for remaining edges |E| = 0 ? Y Return R
Performance of Proposed Models with CL Algorithm Model Top-1 Top-2 Top-3 Top-4 Top-5 Direct + CL 38. 0% 43. 8% 47. 3% 49. 6% 51. 2% Indirect + CL (k=1) 48. 0% 57. 0% 59. 4% 60. 1% 60. 9% • Test query set: 258 terms (from 9, 709 core terms) Indirect + CL (k=3) 48. 7% 58. 1% 60. 8% 62. 0% • Anchor-text-set corpora Transitive + CL (k=1) 52. 7% 60. 1% 62. 5% 63. 1% 63. 9% Traditional Chinese-English: 109, 416 sets Transitive + CL (k=3) 52. 7% Simplified Chinese-English: 157, 786 sets 61. 6% 63. 9% 64. 3% 65. 1% Model 63. 1% Traditional Chinese-Simplified Chinese : 4, 516 sets • Source/Target/Intermediate languages: Traditional Chinese/Simplified Chinese/English Top-1 Top-2 Top-3 Top-4 Top-5 Direct 35. 7% 43. 0% 46. 9% 49. 6% 51. 2% Indirect (k=1) 44. 2% 55. 1% 58. 0% 59. 7% 60. 5% Indirect (k=3) 46. 5% 57. 0% 60. 4% 62. 0% 62. 8% Transitive (k=1) 49. 2% 58. 1% 60. 9% 61. 6% 62. 0% Transitive (k=3) 50. 0% 60. 1% 62. 8% 63. 9% 64. 3%
Effective Translation Using CL Algorithm Source terms (Traditional Chinese) 藍鳥 (Bluebird) 迪士尼 (Disney) Top-5 extracted target translations (Simplified Chinese) Direct Not available 乐园(amusement park) 迪士尼(Disney)* 狮子王(Lion King) 狄斯尼(Disney)* 世界(world) Transitive with CL 视点(focus) 电影(movie) 蓝鸟(Bluebird)* 试点(test point) 快车(express) 蓝鸟(Bluebird)* 视点(focus) 电影(movie) 试点(test point) 快车(express) 乐园(amusement park) 迪士尼(Disney)* 狮子王(Lion King) 狄斯尼(Disney)* 世界(world) 迪士尼(Disney)* 乐园(amusement park) 狄斯尼(Disney)* 世界(world) 动画(anime)
Part IV Web Mining for Cross-Language Information Retrieval and Web Search Applications
Web Mining for Cross-Language Information Retrieval and Web Search Applications • Goal: Web mining to benefit CLIR and CLWS – Mining query translations from the Web • Idea: Integrated Web mining approach – Anchor-text-mining approach • Probabilistic inference model • Transitive translation model – Search-result-mining approach • Chi-square test • Context-vector analysis
Search-Result-Mining Approach • Goal: Enhance translation coverage for diverse queries • Idea – Comparable corpus: Language-mixed texts in search-result pages – Utilize co-occurrence relation and context information • Chi-square test • Context-vector analysis • Procedure of query translation based on search-result-mining 1. 2. 3. Corpus collection: Collect m search results from search engines. Translation candidate extraction: Segment the collected corpus and extract k most frequent target terms as candidates. Translation selection: Compute similarity based on chi-square test or context-vector analysis.
Chi-Square Test • Idea – Makes good use of all relations of co-occurrence between the source and target terms. • Similarity measure (Gale & Church 1991) • 2 -way contingency table t ~t s a b ~s c d a: # of pages containing both terms s and t b: # of pages containing term s but not t c: # of pages containing term t but not s d: # of pages containing neither term s nor t N: the total number of pages, i. e. , N= a+b+c+d
Context-Vector Analysis • Idea – Take co-occurring context terms as feature vectors of the source/target terms. • Similarity measure • Weighting scheme: TF*IDF s: ws 1, ws 2, …, wsm t: wt 1, wt 2, …, wtm
Translation Selection based on Chi-Square Test and Context-Vector Analysis • For each candidate – Chi-square test 1. 2. Retrieve page frequencies by submitting the Boolean queries ‘s∩t’, ‘~s∩t’, and ‘s∩~t’ to search engines Compute the similarity Sχ2(s, t) – Context-vector analysis 1. 2. Retrieve the top m search results by submitting t to search engines, and generate its feature vector Compute the similarity SCV(s, t)
Integrated Web Mining Approach • Idea: Take both complementary advantages – Anchor-text-mining: good precision rate – Search-result-mining: good coverage rate • Combined similarity measure m: an assigned weight for each similarity measure Sm Rm(s, t): the similarity ranking between s and t using Sm
Test Bed • Test query set – 430 popular Chinese/English query terms • Filter out terms without translations (from 9, 709 core terms) • OOV: 64% (274/430) are out of vocabulary – 200 random Chinese query terms • Randomly select from top 19, 124 terms in Dreamer log • OOV: 82. 5% (165/200) – 50 scientist names (proper names) • Randomly select from 256 scientists (Science/People in the Yahoo! Directory) • OOV: 76% (38/50) – 50 disease names (technical terms) • Randomly select from 664 diseases (Health/Diseases and Conditions in the Yahoo! Directory) • OOV: 72% (36/50)
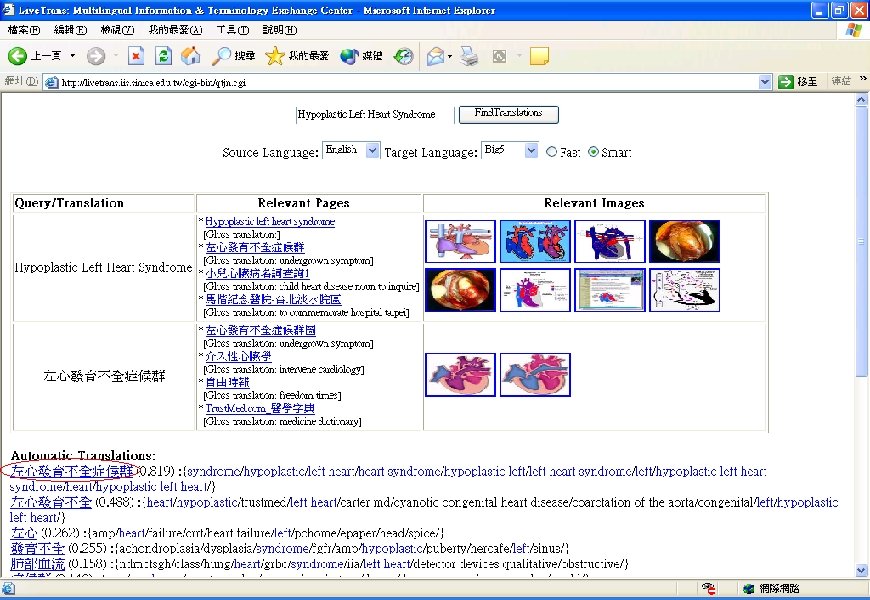
Examples of Proper Name and Technical Term Query type Scientist name Disease name English query Extracted Chinese translations Aldrin, Buzz (Astronaut) Hadfield, Chris (Astronaut) Galilei, Galileo (Astronomer) Ptolemy, Claudius (Astronomer) Tibbets, Paul (Aviators) Crick, Francis (Biologists) Drake, Edwin Laurentine (Earth Scientist) Aryabhata (Mathematician) Kepler, Johannes (Mathematician) Dalton, John (Physicist) Feynman, Richard (Physicist) 艾德林 哈德菲爾德 伽利略/伽里略/加利略 托勒密 第貝茲/迪貝茨 克立克/克里克 德拉克 阿耶波多/阿利耶波多 克卜勒/開普勒/刻卜勒 道爾頓/道耳吞/道耳頓 費曼 Ganglion Cyst Gestational Diabetes Hypoplastic Left Heart Syndrome Lactose Intolerance Legionnaires' Disease Muscular Dystrophy Nosocomial Infections Shingles Stockholm Syndrome Sudden Infant Death Syndrome (SIDS) 腱鞘囊腫 妊娠糖尿病 左心發育不全症候群 乳糖不耐症 退伍軍人症 肌肉萎縮症 院內感染 帶狀皰疹/帶狀庖疹 斯德哥爾摩症候群 嬰兒猝死症
Performance of Web Mining for Popular Queries Approach CV χ2 AT Combined Query type Top-1 Top-3 Top-5 Coverage Dic 56. 4% 70. 5% 74. 4% 80. 1% OOV 56. 2% 66. 1% 69. 3% 85. 0% All 56. 3% 67. 7% 71. 2% 83. 3% Dic 40. 4% 61. 5% 67. 9% 80. 1% OOV 54. 7% 65. 0% 68. 2% 85. 0% All 49. 5% 63. 7% 68. 1% 83. 3% Dic 67. 3% 78. 2% 80. 8% 89. 1% OOV 66. 1% 74. 5% 76. 6% 83. 9% All 66. 5% 75. 8% 78. 1% 85. 8% Dic 68. 6% 82. 1% 84. 6% 92. 3% OOV 66. 8% 85. 8% 88. 0% 94. 2% All 67. 4% 84. 4% 86. 7% 93. 5%
Performance of Web Mining for Random Queries/Proper Names/Technical Terms Table 5. 5 Coverage and inclusion rates for random queries Approach Top-1 Top-3 Top-5 Coverage CV 25. 5% 45. 5% 50. 5% 60. 5% χ2 26. 0% 44. 5% 50. 5% 60. 5% AT 19. 0% 28. 5% 29. 0% Combined 33. 5% 53. 5% 60. 5% 67. 5% Table 5. 6 Inclusion rates for proper names and technical terms using the combined approach. Query type Top-1 Top-3 Top-5 Scientist name 40. 0% 52. 0% 60. 0% Disease name 44. 0% 60. 0% 70. 0%
CLIR on NTCIR-2 Evaluation Task • The test collection (Chen & Chen 2001) – 132, 173 Chinese news documents (200 MB) – 50 English query topics • Title-query (title section only) – Short: Average 3. 8 English words – Low performance: 55% of monolingual performance (Kwok 2001) – Difficulty: CLIR may fail if anyone key word in short queries can not be translated correctly. • Can Web mining solve short query translation? Table 5. 1 Examples of Title-Query in NTCIR-2. Q 06 Q 12 Q 23 Q 28 Q 30 Q 34 Q 45 Q 46 Q 47 English Title Query Chinese Title Query Kosovar refugees Michael Jordan's retirement Disneyland Cutting down the timber of Chinese cypress in Chilan El Nino and infectious diseases Side effects of Viagra Cloud Gate Dance Theatre of Taiwan Ma Yo-yo cello recital Jin Yong kung-fu novels 科索沃難民潮 麥可喬登退休 迪士尼樂園 棲蘭檜木砍伐 聖嬰現象與傳染病 威而鋼之副作用 雲門舞集 馬友友演奏會 金庸武俠小說
Integration of Web Mining and Probabilistic Retrieval Model • Probabilistic retrieval model (Xu 2001; Hiemstra & de Jong 1999) – The Web mining approach: P(e | c) = Pweb(e | c) ≈ SCombined(e, c) – The dictionary-based approach: P(e | c) = Pdic(e | c) ≈ 1/ne ne: the number of translations of c – The hybrid approach: P(e | c) = [Pweb(e | c) + Pdic(e | c)] / 2 Q: English query D: Chinese Document e: English query term c: Chinese translation P(e): background probability P(e|c): translation probability P(c|D): generation probability
Performance of Query Translation and CLIR for NTCIR-2 English-Chinese Retrieval Task Table 5. 9 Top-n inclusion rates with Web mining approach for traditional Chinese translations of 178 English title query terms. Type Number Top-1 Top-2 Top-3 Top-4 Top-5 Terms existing in LDC 156 60. 3% 73. 7% 77. 6% 82. 1% 83. 3% Terms not included in LDC 22 68. 1% 77. 2% 81. 8% 86. 3% Total 178 61. 2% 74. 2% 78. 1% 82. 6% 83. 7% Table 5. 10 The MAP values with three different approaches of query translation to the NTCIR-2 English-Chinese retrieval task. Query translation approach Mean average precision Dictionary-based approach 0. 207 Web mining approach 0. 241 The hybrid approach 0. 271
Performance Analysis for Query Translation & CLIR • Query translation – Effective • Local place names: “Chilan” (棲蘭), “Meinung” (美濃) • Foreign names: “Jordan” (喬登, 喬丹), “Kosovar” (科索沃), “Carter” (卡特) • Aliases/Synonyms: “Disney” (迪士尼, 迪斯奈, 狄士尼) – Ineffective • Common terms: “victim” (受難者), “abolishment” (廢止) • Native Chinese names: “Bai Xiao-yan” (白曉燕), “Bai-feng bean” (白鳳豆) – Multiple senses • Title query Q 01: “The assembly parade law and freedom of speech” – “assembly” => “組合語言” (error), “集會” (correct) – “speech” => “演講”, “語音” (error), “言論” (correct) • CLIR – Effective • Q 23: ”Disneyland”: MAP (mean average precision) from 0 to 0. 721 • Q 46: “Ma Yo-yo cello recital”: MAP from 0. 205 to 0. 446
Conclusion • Practical CLWS services have not lived up to expectations due to lacking multilingual translations for diverse unknown queries. • The Web mining approach, which combines anchor-text-mining and search-result-mining approaches, are complementary in the precision and coverage rates for query translation. • Anchor texts and search-result pages are useful comparable corpora for query translation, which are contributed continuously by a huge number of volunteers (page authors) around the world. • Live. Trans can generate translation suggestions and provide an practical CLWS service for the retrieval of both Web pages and images.
Future Work • Currently, the Live. Trans system cannot fully perform in real time. It is necessary to find an more efficient way to reduce the computation cost. • Employ more language processing techniques to improve the accuracy in phrase translation, word segmentation, unknown word extraction and proper name transliterations. • Develop an automatic way to collect and exploit other Web resources like bilingual/multilingual Web pages. • Enhance the Live. Trans system to handle more Asian and European language translation, such as Japanese, Korean, France, etc. • Apply our Web-mining translation techniques to enhance current machine translation techniques and design a computer-aided English writing system.