Convolutional Neural Nets Advanced Vision Seminar April 19

 : Image. Net Classification with Deep Conv. Nets – Large")



: Input : 224 x 3 mean-subtracted Layer 1: 96 kernels")

 D – Data/Batch size : “Momentum")
 Num.")
 • Easier to differentiate •")

: 1.")




 no rigorous analysis of effect of network structure,")



















- Slides: 38
Convolutional Neural Nets Advanced Vision Seminar April 19, 2015
Overview • The Revolution(2012) : Image. Net Classification with Deep Conv. Nets – Large performance gap – Possible Explanations • What makes convnets tick? Visualizing and Understanding Deep Conv. Nets • Some Limits of conv. Nets • Useful Resources
Image. Net Classification with Deep Conv. Neural Networks • Until 2012: Leading methods used hand-crafted features + encoding methods (e. g, SIFT+Bag-of. Words+SVM) • NIPS 2012, Alex Krizhevsky et. Al • Significant improvement w. r. t other methods: Image. Net performance – 2010: ~28% (pre-convnet) – 2012: 16% (Krizhevsky) – 2013: 12% – 2014: 6. 7%
Causes for Performance Gap: • Deep Nets have been around for a long time, why the sudden gap? • Combination of multiple factors: – Network Design – Scale of Data – Re. Lu faster convergence – Dropout – less overfitting – SGD – GPU computations
Network Design • Basic layer types: – Convolution – Nonlinearity – Pooling : max, avg – Local Normalization Lecun, 1989 • 8 Layers (deeper, wider than 1989) connected can also be viewed as convolution, receptive field is entire layer Krizhevsky, 2012
Network Design (Layer 0): Input : 224 x 3 mean-subtracted Layer 1: 96 kernels of 11 x 3, stride of 4 pixels, max pool and locally normalize Layer 2: 256 kernels of 5 x 5 x 96, max pool Layers 3 -5: more convolutions, similar to 1, 2 Layers 6, 7 : fully connected, 4096 hidden units each Layer 8: Soft-max over 1000 classes ….
Num Samples vs. Num. Parameters • The network has ~60, 000 parameters. To avoid overfitting, a lot of data is needed • Imagenet is indeed very large: > millions images – Training set: 1. 2 mil. Images, 1000 obj. classes • Additional samples are generated via data augmentation: simple geometric and color transformations • Dropout
Optimization - definitions Loss on one sample (softmax-loss) D – Data/Batch size : “Momentum Variable” (update history) Loss on batch : Regularization term : : Learning rate Momentum improves convergence stability and speed • Regularization term crucial for performance, according to authors • •
Optimization • • Set =. 9, = 0. 0005 , D=128 (batch size) Num. Epochs: 90 Update: =. 001 (initially) • This is called SGD+Momentum
Relu: Faster Convergence • Nonlinearity: tanh-> Relu (rectilinear unit) • Easier to differentiate • Avoids saturation • In practice, much faster convergence Krizhevsky, 2012 Relu Tanh
Stronger Machines • Modern GPU architectures enable massively parallel computations of the sort required by deep conv. nets • Training with two strong GPU’s, this took “only” 6 days – a x 50 speedup w. r. t to CPU training
Imagenet Results • LSVRC : Large Scale Visual Recognition Challenge • Imagenet (2014): 1. 4 mil. Images, 1000 obj. classes • Compare: Pascal : 22, 000 images, 20 obj. classes)
Results - 2012 Agaric
Generic Use in Vision • Using the output of the fully connected layers as a generic feature extractor has proven to very strong • Beating state of the art in many datasets/benchmarks unrelated to Image. Net • This is now standard in object detection, scene classification, Scene parsing, Segmentation, and many more • “Machine crafted” vs. hand crafted features
Generic Use in Vision a computer vision scientist: How long does it take to train these generic features on Image. Net? Hossein: 2 weeks Ali: almost 3 weeks depending on the hardware the computer vision scientist: hmmmm. . . Stefan: Well, you have to compare three weeks to the last 40 years of computer vision *quote from http: //www. csc. kth. se/cvap/cvg/DL/ots/ A. S. Razavian, H. Azizpour, J. Sullivan, S. Carlsson "CNN features off-the-shelf: An astounding baseline for recognition", CVPR 2014, Deep. Vision workshop
Network Design ? ? • How to determine “hyper-parameters”: – No. layers? – Kernel Size/Num. of kernels? – Training rate? Number of training epochs? –… • From own experience, either: – Start with existing network & tweak / finetune – Incrementally increase network complexity – start with a few layers, see what works • Domain knowledge : convolutions are especially suited for images, not always the right choice
Network Structure • (To my knowledge) no rigorous analysis of effect of network structure, either theoretical or empirical – Example: systematically check many different network structures / configurations – See what works well, what doesn’t and explain why • Guessing: Probably done by successful architectures, but “bad” results not published
Visualizing & Understanding Conv. Nets What Makes Convnets “Tick”? What happens in hidden units? Layer 1: easy to visualize Deeper layers: just a bunch of numbers? Or something more meaningful? • Do convnets use context or actually model target classes • •
Introducing: Visualizing & Understanding Conv. Nets • Zeiler & Fergus, 2013 • Goal: Try to visualize the “black box” hidden units, gain insights • Hope: Use conclusions to improve performance • Idea: “Deconvolutional” neural net
Deconvolutional Nets • Originally suggested for unsupervised feature learning : construct a convolutional net, cost function is image reconstruction error • Used here to find what stimuli causes strongest responses in hidden units • Run many images through net find strongest unit activations in each layer visualize by “reversing” net operation
Reversing a convent
“Unpooling”
Deconvolution* • Want to visualize a strong activation in feature map P from layer L+1 down to layer L. • As in Deep-Belief Nets: L P*F’, where F’ is the original kernel flipped in both dimensions • Intuition: can show, gradient of F w. r. t input is F’, this is back-propping error of strongest activations • *Note: Not really “deconvolution”, this is not an attempt to recover original signal
Layer 1:
Hidden Layer Visualizations: layer 2
Hidden Layer Visualizations: Layer 3
Hidden Layer Visualizations: Layer 4
Hidden Layer Visualizations: Layer 5
It’s Nice to Watch, But is it Useful? • Authors observed aliasing effects caused by large stride in lower layers (e. g, loss of fine texture) • Reducing filter size and stride increased performance, also reporting qualitatively “cleaner” looking filters
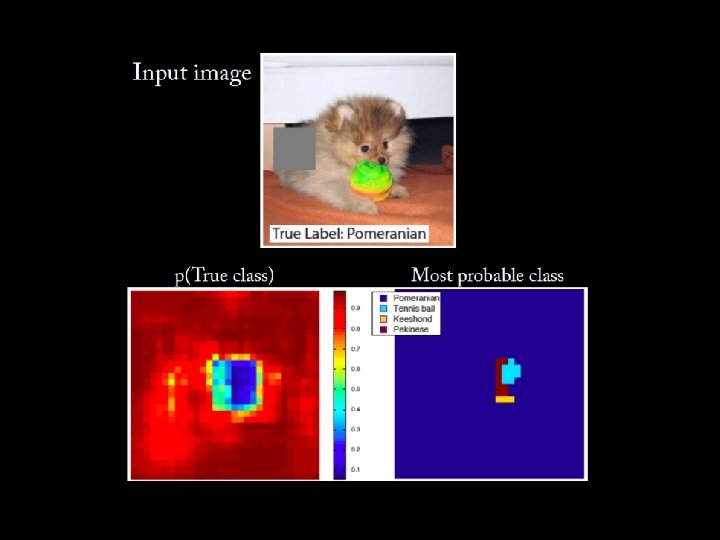
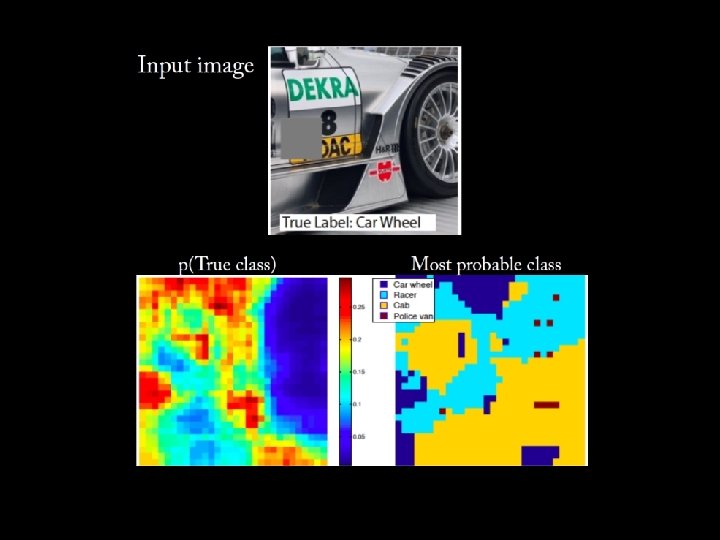
Is the net using context? • Let’s test if the network really focuses on relevant features • Systematically occlude different parts of image • Check output confidence for true class • (This doesn’t really have to do with the visualization)
Following Network paths • B. Zhou et al , Object Detectors Emerge in Deep CNNs, ICLR 2015
Going Deeper with convolutions • Recently, even deeper models have been proposed: Goog. Le. Net – 22 layers : 6. 7 top 5 error • 16 and 19 layer architectures from VGG , similar performance
Limits : Easy Classes : natural, highly textured, fine-grained • Natural, Highly textured, fine-grained
Limits : Difficult Classes • Man-Made, simple, non-textured, functional ?
Useful Tools • For starters: Mat. Conv. Net : – – Matlab Simple, straightforward Pre-trained popular models Windows/Linux compatible • More advanced: Caffe : – Powerful , open-source framework for training and testing convnets, with c++/python/matlab interfaces – Mostly Linux (some old windows ports) – “Model-Zoo” : updates often with state-of-the-art models • Many more deeplearning. net/software_links/
Thank You • References: • Lecun et al, Backpropagation Applied to Handwritten Zip Code Recognition (MIT press, 1989) • Zeiler et al, Visualizing and understanding convolutional networks, ECCV 14 • Rob Fergus. Deep Learning for Computer Vision (Tutorial). NIPS, 2013 (including several imgs from slides) • Russakovsky et al, Image. Net Large Scale Visual Recognition Challenge. ar. Xiv: 1409. 0575, 2014 • A. S. Razavian, H. Azizpour, J. Sullivan, S. Carlsson "CNN features off-the-shelf: An astounding baseline for recognition", CVPR 2014, Deep. Vision workshop