CH 11 UNSTRUCTURED DATA AND THE DATA WAREHOUSE
























 The result is a self-organizing map (SOM). The SOM produces")








- Slides: 49
CH: -11 UNSTRUCTURED DATA AND THE DATA WAREHOUSE
The world of unstructured data is one that is dominated by casual, informal activities such as those found on the personal computer and the Internet. The following are typical of the data formats for unstructured data: Emails Spreadsheets Text files Documents Portable Document Format (. PDF) files Microsoft Power. Point (. PPT) files
Figure 11 -1 shows the world of unstructured data. The polar opposite of unstructured data is structured data. Structured data is typified by standard DBMSs, reports, indexes, databases, fields, records, and the like. Figure 11 -2 depicts the structured world.
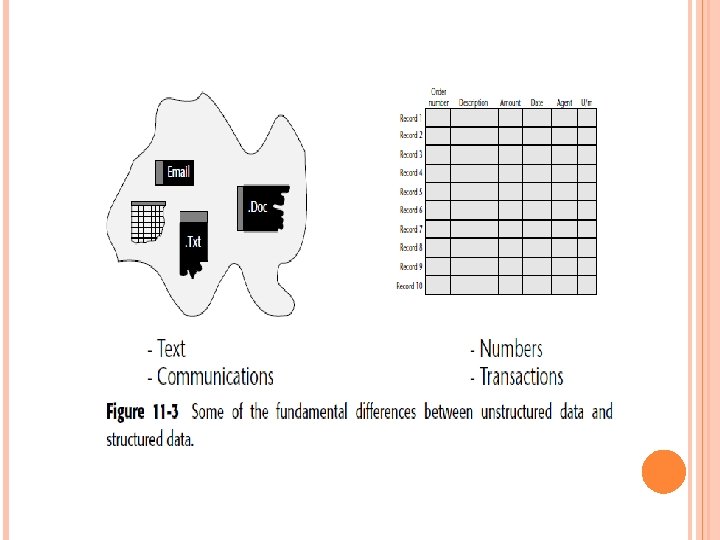
Communications tend to be relatively short and are for very limited distribution. Communications tend to have a short life. Documents tend to be for a wider audience and are typically larger than communications. Documents tend to live a lot longer than communications. The world of structured data is one that is dominated by numbers. The world of structured data has keys, fields, records, databases, and so forth. Figure 11 -3 shows the primary differences between structured data and unstructured data.
A FUNDAMENTAL MISMATCH While grammatically there are many differences between the two environments, perhaps the biggest reasons why matching raw data from one environment to the next is so fraught with misleading conclusions is that there is a fundamental mismatch between the environments represented between the two worlds. The unstructured environment represents documents and communications. The structured environment represents transactions.
In the structured environment, the minimum amount of textual data is captured. The textual data in the transaction environment serves only to identify and clarify the transaction. Matching Text across the Environments So, how can a match of text across the two environments be made? How can data meaningfully arrive in the data warehouse environment from an unstructured source? There are many ways a meaningful match can be made.
A stop word is a word that occurs so frequently as to be meaningless to the document. Typical stop words include the following: a an the for to by from when which that where
The second basic edit that must be done is the reduction of words back to their stem. For example, the following words all have the same grammatical stem: moving moved moves mover removing
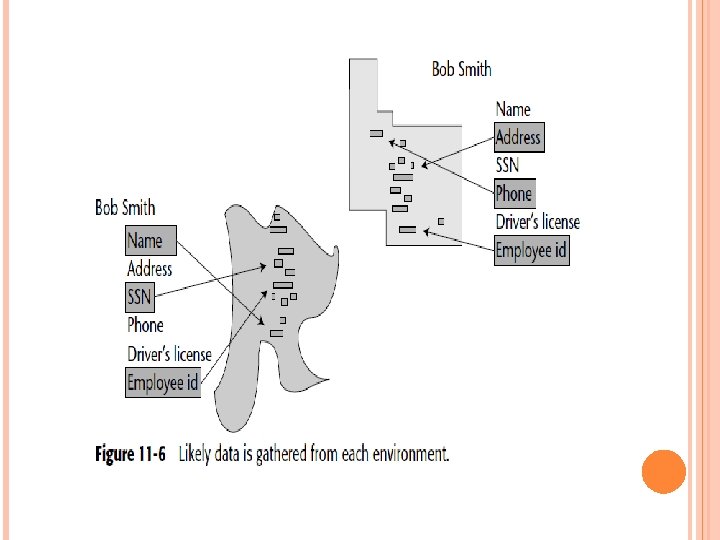
A PROBABILISTIC MATCH One of the ways that a meaningful match of data across the two environments can be made is through related data being included in the matching process. The classical way to make this determination is to create what can be termed a probabilistic match. In a probabilistic match, as much data that might be used to indicate the “Bob Smith” that you’re looking for is gathered and is used as a basis for a match against similar data found where other “Bob Smiths” are located.
Figure 11 -6 shows that in the unstructured environment other types of information are gathered along with the name “Bob Smith. ”
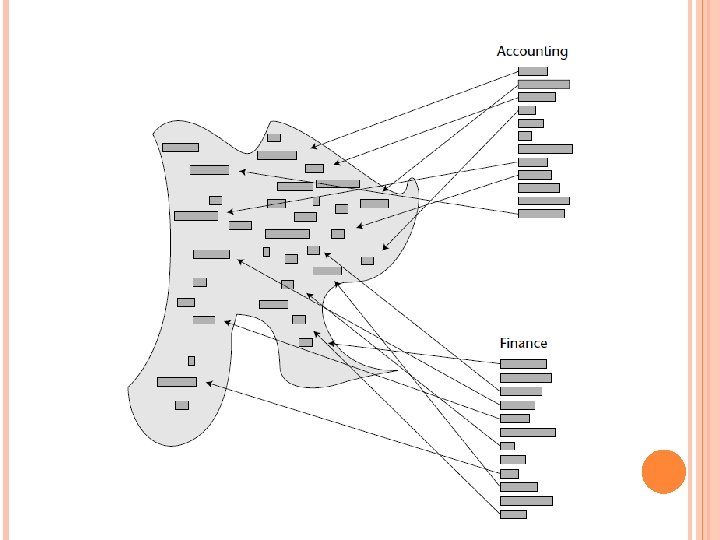
A THEMED MATCH A probabilistic matching of data is not the only way there is to match text between the structured and the unstructured environments. Another way of creating a match, or at least a relationship of text between the structured and the unstructured environments, is through a technique that can be called an “industrially recognized” grouping or theme of data.
INDUSTRIALLY RECOGNIZED THEMES One way to organize the unstructured data is by industrially recognized themes. In this approach, the unstructured data is analyzed according to the existence of words that relate to industrialized themes. For example, the accounting theme would contain words and phrases such as the following: receivable payable cash on hand asset debit due date account
The finance theme would contain such information as the following: price margin discount gross sale net sale interest rate carrying loan balance due
Once the collections of industrially recognized themes have been gathered, the unstructured data is passed against themes. Any time a word or the root of a word exists in the unstructured environment, a tally is made. This technique of passing unstructured text against industrially recognized themes allows the documents to be organized. A set of documents that has a strong orientation against accounting will have many “hits” against the industrially recognized list of words.
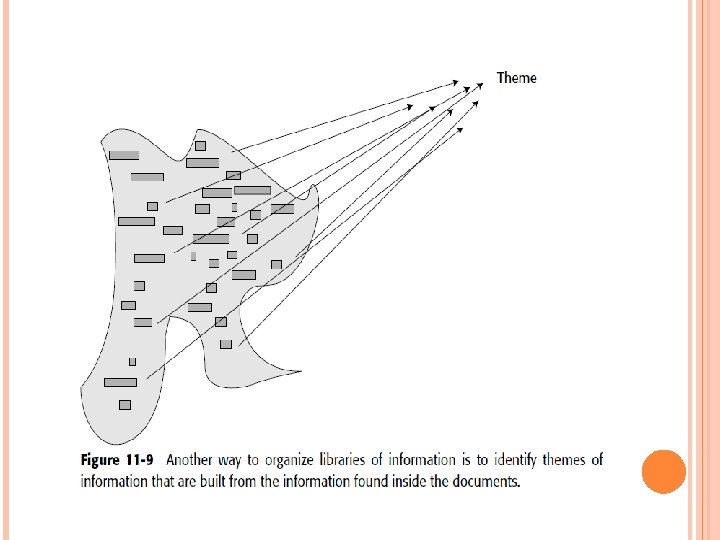
NATURALLY OCCURRING THEMES Another way to organize unstructured data is through naturally occurring themes. Figure 11 -9 shows this organization.
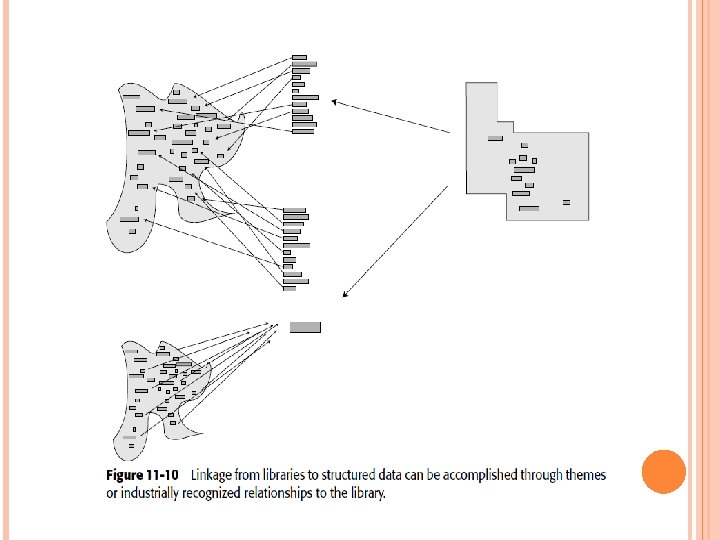
LINKAGE THROUGH THEMES AND THEMED WORDS Linkage can be formed to the structured environment through the data that forms theme of a document, as shown in Figure 11 -10. One way to relate themed data found in the unstructured environment to the data found in the structured environment is through a raw match of data. In a raw match of data, if a word is found anywhere in the structured environment and the word is part of theme of a document, the unstructured document is linked to the structured record.
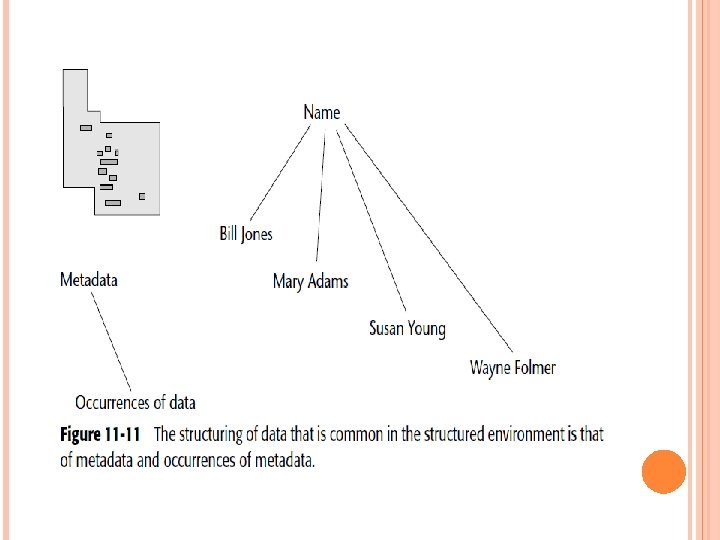
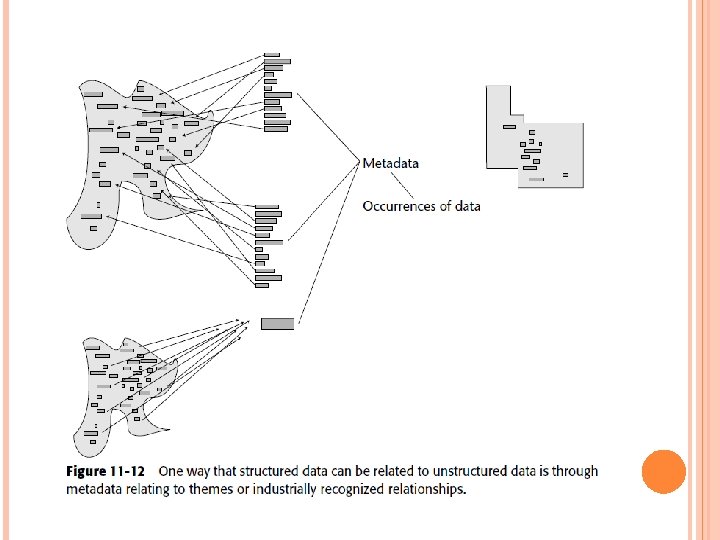
LINKAGE THROUGH ABSTRACTION AND METADATA Instead, another way to link the two environments is by the metadata found in the structured environment. To see how such linkage can occur, refer to the data found in Figure 11 -11. Put another way, data exists at two levels in the structured environment— the abstract level and the actual occurrence level. Figure 11 -12 shows this relationship of data. In Figure 11 -12, data exists at an abstract level— the metadata level. In addition, data exists at the occurrence level— where the actual occurrences of data reside.
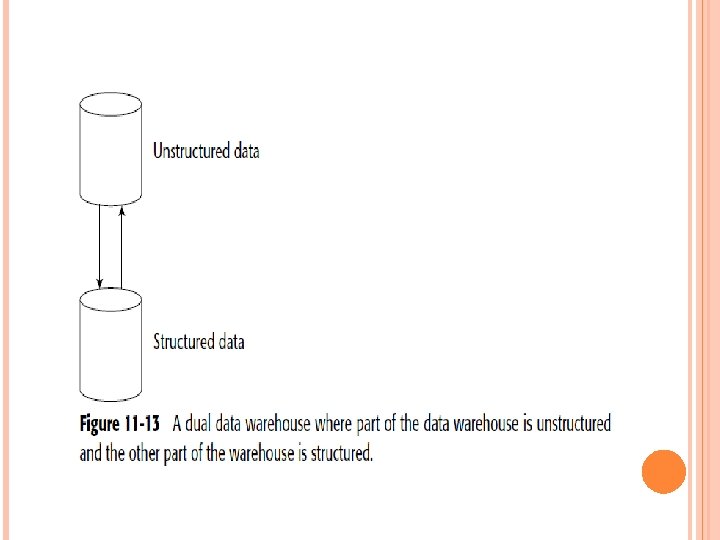
A TWO-TIERED DATA WAREHOUSE There are two basic approaches to the usage of unstructured data in the data warehouse environment. One approach is to access the unstructured environment and pull data over into the structured environment. Another approach to unstructured data and the data warehouse environment is to create a two-tiered data warehouse. One tier of the data warehouse is for unstructured data and another tier of the data warehouse is for structured data. Figure 11 -13 shows this approach.
In Figure 11 -13, there are two related but separate components of a data warehouse. The data found in the unstructured data warehouse is in many ways similar to the data found in the structured data warehouse. Consider the following when looking at data in the unstructured environment: It exists at a low level of granularity. It has an element of time attached to the data. It is typically organized by subject area or “theme. ”
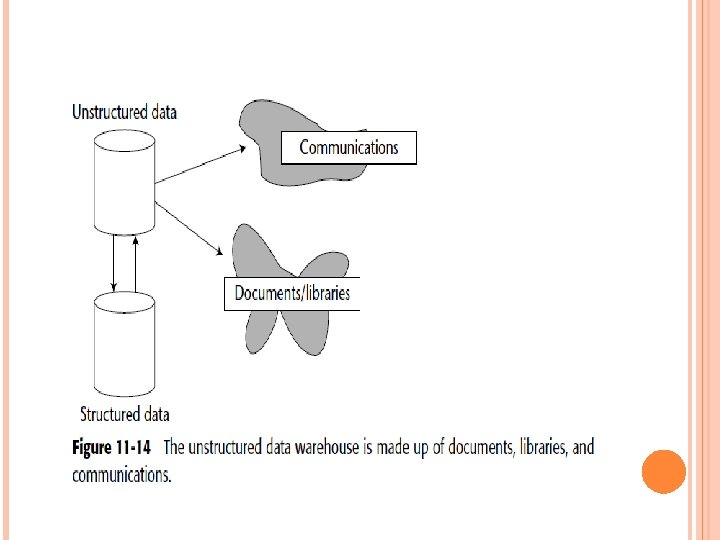
DIVIDING THE UNSTRUCTURED DATA WAREHOUSE There are some major differences between the structured data warehouse and the unstructured data warehouse. Data in the unstructured data warehouse is divided into one of the two following categories: Unstructured communications Documents and libraries Figure 11 -14 shows the division of data inside the unstructured data warehouse.
Communications have keys that typically are such things as the following Email address Telephone number Fax number Documents are found in the unstructured data warehouse as well. As a rule, documents are much larger than communications. Documents are grouped into libraries. A library is merely a collection of documents, all of which relate to some subject.
Subjects for a library might be almost anything, such as the following: Oil and gas accounting Terrorism and hijacking Explosives, mines, and artillery Insurance tables and calculations
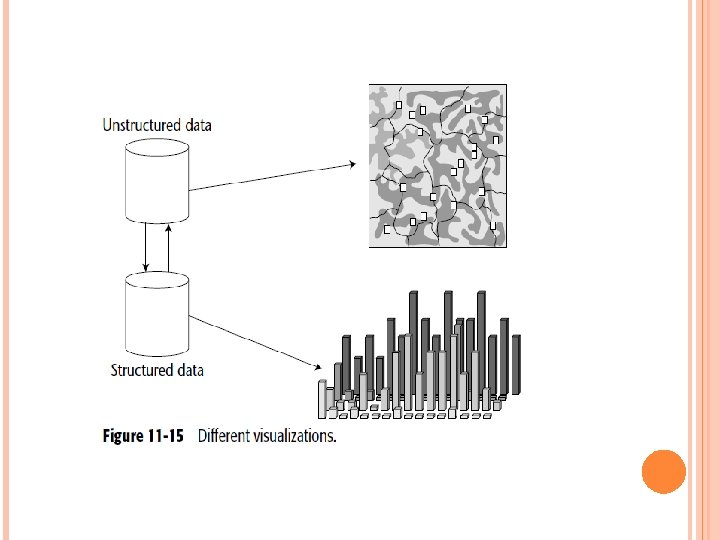
VISUALIZING UNSTRUCTURED DATA Unstructured visualization is the counterpart to structured visualization. Structured visualization is known as Business Intelligence. There are many commercial products that are used to embody structured visualization, including Business Objects and Micro Strategy. Figure 11 -15 shows the different kinds of visualization for the different data warehouses.
Visualization can also be done for textual-based data. Textual-based data forms the foundation of unstructured technology. To create a textual visualization, documents and words are collected. Then the words are edited and prepared sfor display.
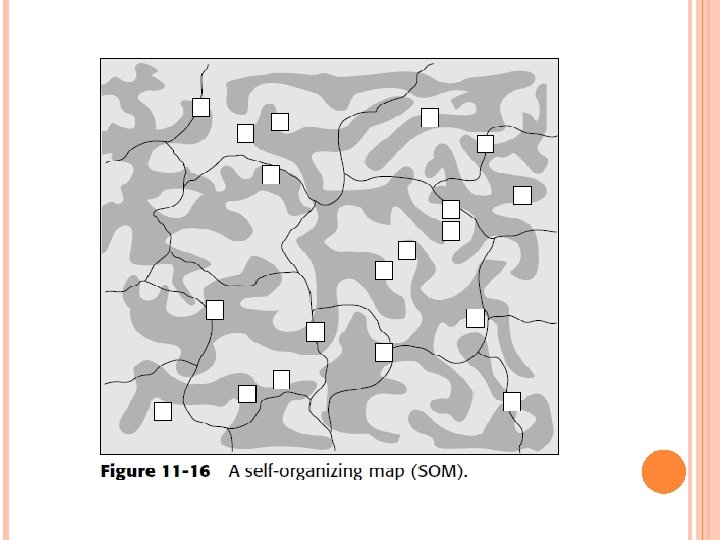
A SELF-ORGANIZING MAP (SOM) The result is a self-organizing map (SOM). The SOM produces a display that appears to be a topographical map. The SOM shows how different words and the documents are clustered, and displayed according to themes. Figure 11 -16 shows a visualization for the unstructured environment. The SOM has different features. One feature is the clustering of information based on the data found in different documents. By looking at clusters, data that has common characteristics and relationships can be grouped for easy reference.
One important aspect of an SOM is the ability to quickly relate documents. Once the analyst has examined the SOM, if you want to look at a document, then direct access of the document can be allowed.
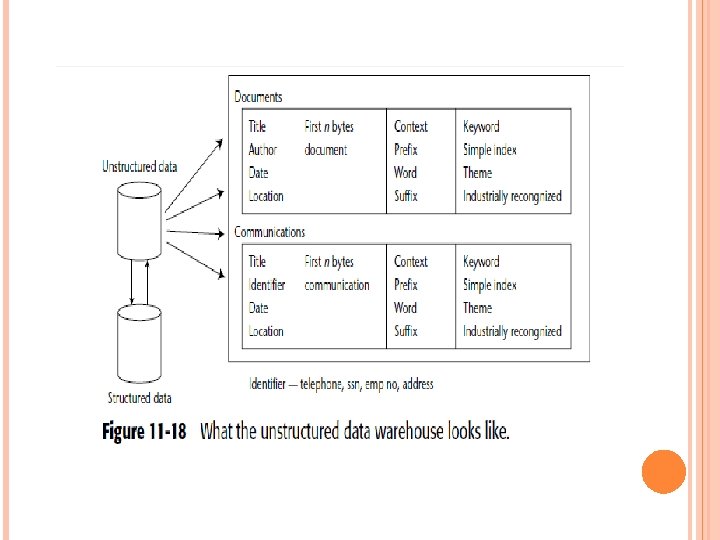
THE UNSTRUCTURED DATA WAREHOUSE What exactly does the structure of the unstructured data warehouse look like? Figure 11 -18 shows a high-level view of the unstructured data warehouse. In Figure 11 -18, the unstructured data warehouse is divided into two basic organizations—one part for documents and another part for communications.
The communications section is for shorter messages. Communications include email, memos, letters, and other short missives. The data that can be stored in each section includes the following: The first n bytes of the document The document itself (optional) The communication itself (optional) Context information Keyword information
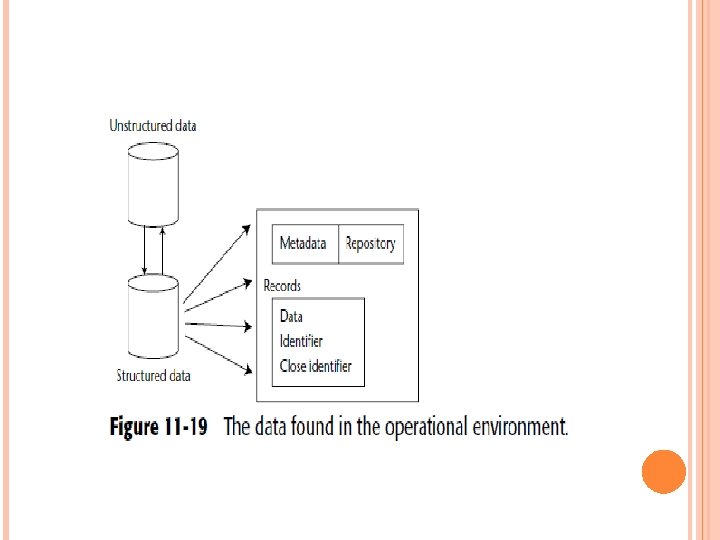
FITTING THE TWO ENVIRONMENTS TOGETHER For all practical purposes, the unstructured environment contains data that is incompatible with data from the structured environment. Unstructured data might as well be running AC, and structured data might as well be DC. It is text that relates the two environments, a shown in Figure 11 -19 shows that the structured environment consists of several components, including the following: At an abstract level—metadata and a repository At a record level—raw data, identifiers, and close identifiers
An identifier is an occurrence of data that serves to specifically identify a record. Typical of identifiers are Social Security number, employee number, and driver’s license number. Close identifiers are identifiers where there is a good probability that a solid identification has been made. Close identifiers include names, addresses, and other identifying data. The difference between an identifier and a close identifier is the sureness of the identification.
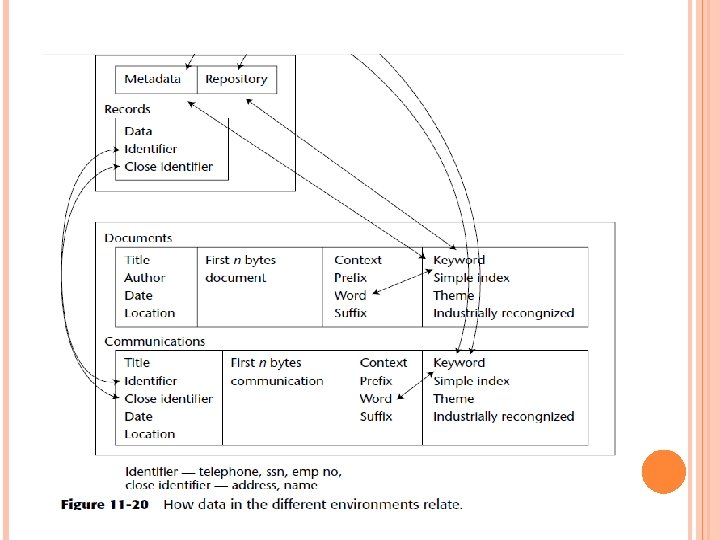
Figure 11 -20 shows the data types that are found in the structured environment and the unstructured environment. On the top are the data types from the structured environment. On the bottom are the data types from the unstructured environment. The unstructured environment is divided into two basic categories— documents and communications. In the documents category are found documentidentifying information such as title, author, data of document, and location of document.
Figure 11 -20 shows that identifiers from the structured environment can be matched with identifiers from the unstructured environment. Close identifiers from the structured environment can probabilistically be matched with close identifiers from the unstructured environment. Keywords can be matched from the unstructured environment with either metadata or repository data from the structured environment.