Aprendizagem de Mquina Ivan Medeiros Monteiro Luis Otavio



















 : S → R, sendo: – S o conjunto")
 : (S x A) → R,")
, arbitrário Repetir ( para cada episódio ): – Inicializar")
 • Definição do problema – Encontrar a flor com")
 • s ← s 4 Ações • Escolher ação")
 • s ← s 5 Ações • Escolher ação")
 • s ← s 4 Ações • Escolher ação")
 • s ← s 1 Ações • Escolher ação")
 • s ← s 2 Ações • Escolher ação")
 • s ← s 3 Ações • Escolher ação")
 • s ← s 4 Ações • Escolher ação")
 • s ← s 1 Ações • Escolher ação")
 • s ← s 4 Ações • Escolher ação")
 • s ← s 1 Ações • Escolher ação")
 • s ← s 2 Ações • Escolher ação")
 • s ← s 5 Ações • Escolher ação")
 • Q(s 1, frente) = -0, 75 Ações •")



- Slides: 40
Aprendizagem de Máquina Ivan Medeiros Monteiro Luis Otavio Alvares
Definindo aprendizagem Dizemos que um sistema aprende se o mesmo é capaz de melhorar o seu desempenho a partir de suas experiências anteriores. O aprendizado envolve a generalização a partir da experiência O desempenho deve melhorar não apenas na repetição da mesma tarefa, mas também nas tarefas similares do domínio
O desafio do aprendizagem • Na maioria dos problemas de aprendizagem, os dados disponíveis não suficientes para garantir a generalização ótima • Por isso, os algoritmos de aprendizagem de máquinas são heurísticas que variam nos seus objetivos, na disponibilidade de dados de treinamento, nas estratégias de aprendizagem e na representação do conhecimento.
Exemplos de Problemas de aprendizagem • Reconhecimento de assinaturas • Classificar mensagens • Identificação de perfil de usuários • Interação em ambientes desconhecidos • Agrupar itens com características semelhantes • Conduzir um veículo
Tipos de aprendizagem • Supervisionado • O sistema é informado sobre seus erros e quais os resultados esperados. • Não supervisionado – O sistema precisa identificar relações existentes no seu conjunto de experiências Por Reforço Possibilita a aprendizagem a partir de interação com o ambiente
Tipos de Tarefas de Aprendizagem • Geração de modelos descritivos – Determinação de protótipos de agrupamentos – Determinação de co-ocorrências de valores de atributos • Geração de modelos preditivos – Classificação – Regressão
Modelos Descritivos • Em geral, a tarefa de geração de um modelo descritivo consiste em analisar os dados do domínio e sugerir uma partição deste domínio, de acordo com similaridades observadas nos dados – Descoberta de particionamentos – Modelo de agrupamento dos dados
Modelos Descritivos: Agrupamento Agrupar plantas em três grupos distintos com base nas medidas de suas pétalas e sépalas.
Modelos Descritivos: associativo • Um modelo associativo é um caso especial de um modelo descritivo • A tarefa de geração de um modelo associativo consiste em analisar os dados do domínio e encontrar co-ocorrências de valores de atributos. • Um modelo associativo é normalmente representado por um conjunto de regras de associação.
Modelos Associativos: Cesta de Compras Consiste em analisar transações de compras de clientes e determinar quais são os itens que frequentemente são comprados juntos. pode-se usar esta informação para desenvolver políticas de marketing e preço.
Exemplo: vendas casadas Sei quem compra A também compra B. PRODUTO PARODUTO B Compra de produto prof. Luis Otavio PRODUTO A Oferta de produto relacionado
prof. Luis Otavio
Modelos Preditivos • A tarefa de geração de um modelo preditivo consiste em aprender um mapeamento da entrada para a saída. • Neste caso, os dados contêm os valores de saída “desejados”, correspondente para cada amostra – Classificação: saídas discretas representam rótulos de classe. – Regressão: saídas contínuas representam valores de variáveis dependentes.
Modelos Preditivos: Classificação Dado um conjunto de treinamento, com exemplos rotulados das plantas, aprender a classificá-las corretamente com base em suas medidas.
Modelos Preditivos: Classificação • Reconhecimento de assinaturas – A partir de um conjunto de assinaturas de uma pessoa, utilizadas para o treinamento do modelo, identificar se uma nova assinatura pertence a esta pessoa. • Classificação de mensagens – A partir de um conjunto de mensagens definidas pelo usuário como SPAM, identificar se a nova mensagem é SPAM ou não.
Aprendizagem por Reforço • Técnica que possibilita a aprendizagem a partir da interação com o ambiente. • A interação com o ambiente permite inferir relações de causa e efeito sobre as conseqüências de nossas ações e sobre o que fazer para atingir nossos objetivos. • Aprender por reforço significa aprender o que fazer como realizar o mapeamento de situações em ações (comportamento) - de modo a maximizar um sinal numérico de recompensa.
Aprendizagem por Reforço • Não se dispõe da informação sobre quais ações devem ser tomadas, mas o ambiente permite uma avaliação crítica das ações realizadas. • O sistema de aprendizagem deve descobrir quais ações têm mais chances de produzir recompensa, e realizá-las. • Nos casos mais interessantes e difíceis as ações podem afetar não apenas a recompensa imediata mas também a próxima situação e através dela todas as recompensas subseqüentes.
Aprendizagem interativa através de agentes • Um agente pode ser visto como uma modelagem conceitual que utiliza a forma de interação, através de percepções e ações, na tentativa de alcançar uma solução para o problema. • O objeto com o qual o agente interage é chamado de ambiente • A interação se dá com o agente selecionando ações e o ambiente respondendo a estas ações apresentando novas situações para o agente.
Política de Ações Definição do problema • A cada instante de tempo t: – O agente está no estado st – Executa uma ação at – Que o leva para o estado st+1 – Com isso agente recebe uma recompensa r(st, at) • Objetivo: – Encontrar a política de ações que maximize o total de recompensas recebidas pelo agente.
Função de Utilidade • U(s) : S → R, sendo: – S o conjunto dos estados – R o conjunto dos reais, representando o valor da utilidade • Normalmente representado como uma tabela que mapeia cada estado em sua utilidade • Constrói um modelo de transição de estados
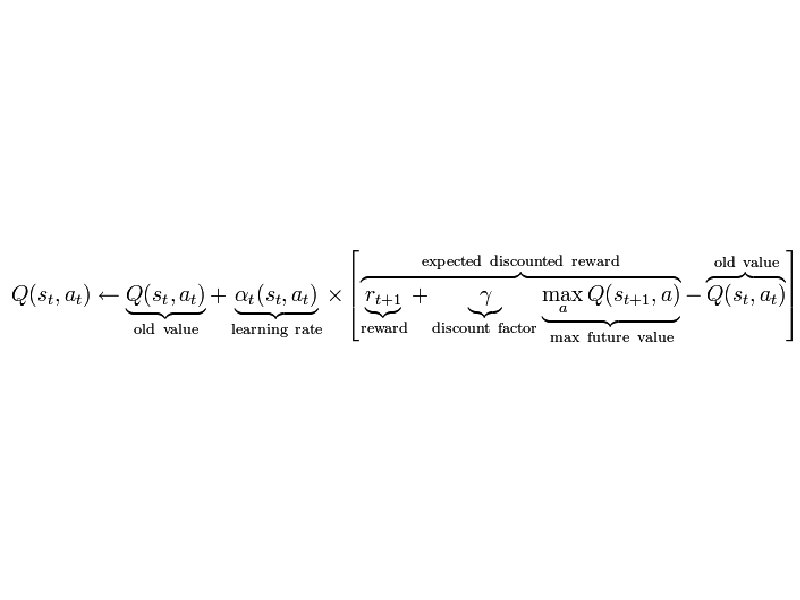
Método de Valor das Ações • Qπ(s, a) : (S x A) → R, onde: – S é o conjunto dos estados possíveis. – A é o conjunto das ações possíveis – R é o conjunto real que representa os valores de recompensa recebidos pelo agente. • Pode ser representada como uma tabela com o valor de cada par (estado X ação) • Método utilizado pelo algoritmo Q-Learning
Algoritmo Q-Learning Inicializar Q(s, a), arbitrário Repetir ( para cada episódio ): – Inicializar s – Repetir ( para cada passo até o objetivo ): • • • Escolher a ação a com base na política derivada de Q (ex: gulosa) Realizar a ação a Observar o recompensa r e o novo estado s' V = r + maxa' Q(s', a') = função de valor para a política Q(s, a) = Q(s, a) + α[V – Q(s, a)] s ← s' , a ← a‘
Exemplo: Desviando de obstáculo (Início) • Definição do problema – Encontrar a flor com o menor desgaste possível. Ações – Estados • S = {s 1, s 2, s 3, s 4, s 5, s 6} – Ações possíveis • A = {Frente, Cima, Baixo} – Inicialização • Q(s, a) = 0, ∀s, ∀a • = 0. 5 • α = 0. 5 recompensa Recompensa
Desviando de obstáculo (Época 1) • s ← s 4 Ações • Escolher ação baseado em Q – Q(s 4, frente)=0 – Q(s 4, cima)=0 • Ação: frente • r = -100 • s' ← s 5 • V = r + maxa' Q(s', a') – V = -100 + 0. 5* maxa' Q(s 5, a') • V= -100 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 4, frente) = Q(s 4, frente) + 0. 5*[-100 – 0] • Q(s 4, frente) = - 50 Recompensa
Desviando de obstáculo (Época 1) • s ← s 5 Ações • Escolher ação baseado em Q – Q(s 5, frente)=0 – Q(s 5, cima)=0 • Ação: frente • r=1 • s' ← s 6 • V = r + maxa' Q(s', a') – V = 1 + 0. 5* maxa' Q(s 6, a') • V= 1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 5, frente) = Q(s 5, frente) + 0. 5*[1 – 0] • Q(s 5, frente) = 0. 5 Recompensa
Desviando de obstáculo (Época 2) • s ← s 4 Ações • Escolher ação baseado em Q – Q(s 4, frente)=-50 – Q(s 4, cima)=0 • Ação: cima • r = -1 • s' ← s 1 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 1, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 4, cima) = Q(s 4, cima) + 0. 5*[-1 – 0] • Q(s 4, cima) = - 0. 5 Recompensa
Desviando de obstáculo (Época 2) • s ← s 1 Ações • Escolher ação baseado em Q – Q(s 1, frente)=0 – Q(s 1, baixo)=0 • Ação: frente • r = -1 • s' ← s 2 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 2, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 1, frente) = Q(s 1, frente) + 0. 5*[-1 – 0] • Q(s 1, frente) = - 0. 5 Recompensa
Desviando de obstáculo (Época 2) • s ← s 2 Ações • Escolher ação baseado em Q – Q(s 2, frente)=0 – Q(s 2, baixo)=0 • Ação: frente • r = -1 • s' ← s 3 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 3, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 2, frente) = Q(s 2, frente) + 0. 5*[-1 – 0] • Q(s 2, frente) = - 0. 5 Recompensa
Desviando de obstáculo (Época 2) • s ← s 3 Ações • Escolher ação baseado em Q – Q(s 3, baixo)=0 • Ação: baixo • r=1 • s' ← s 6 • V = r + maxa' Q(s', a') – V = 1 + 0. 5* maxa' Q(s 6, a') • V= 1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 3, baixo) = Q(s 3, baixo) + 0. 5*[1 – 0] • Q(s 3, baixo) = 0. 5 Recompensa
Desviando de obstáculo (Época 3) • s ← s 4 Ações • Escolher ação baseado em Q – Q(s 4, frente)=-50 – Q(s 4, cima)=-0. 5 • Ação: cima • r = -1 • s' ← s 1 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 1, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 4, cima) = Q(s 4, cima) + 0. 5*[-1 + 0. 5] • Q(s 4, cima) = - 0. 75 Recompensa
Desviando de obstáculo (Época 3) • s ← s 1 Ações • Escolher ação baseado em Q – Q(s 1, frente)=-0. 5 – Q(s 1, baixo)=0 • Ação: baixo • r = -1 • s' ← s 4 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 4, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 1, baixo) = Q(s 1, baixo) + 0. 5*[-1 – 0] • Q(s 1, baixo) = - 0. 5 Recompensa
Desviando de obstáculo (Época 3) • s ← s 4 Ações • Escolher ação baseado em Q – Q(s 4, frente)=-50 – Q(s 4, cima)=-0. 75 • Ação: cima • r = -1 • s' ← s 1 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 1, a') • V= -1 - 0. 5 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 4, cima) = Q(s 4, cima) + 0. 5*[-1. 5 + 0. 75] • Q(s 4, cima) = - 1. 125 Recompensa
Desviando de obstáculo (Época 3) • s ← s 1 Ações • Escolher ação baseado em Q – Q(s 1, frente)=-0. 5 – Q(s 1, baixo)=-0. 5 • Ação: frente • r = -1 • s' ← s 2 • V = r + maxa' Q(s', a') – V = -1 + 0. 5* maxa' Q(s 2, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 1, frente) = Q(s 1, frente) + 0. 5*[-1 + 0. 5] • Q(s 1, frente) = - 0. 75 Recompensa
Desviando de obstáculo (Época 3) • s ← s 2 Ações • Escolher ação baseado em Q – Q(s 2, frente)=-0. 5 – Q(s 2, baixo)= 0 • Ação: baixo • r = -100 • s' ← s 5 • V = r + maxa' Q(s', a') – V = -100 + 0. 5* maxa' Q(s 5, a') • V= -1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 2, baixo) = Q(s 2, baixo) + 0. 5*[-100 + 0] • Q(s 2, baixo) = - 50 Recompensa
Desviando de obstáculo (Época 3) • s ← s 5 Ações • Escolher ação baseado em Q – Q(s 5, frente)=0. 5 – Q(s 5, cima)= 0 • Ação: frente • r=1 • s' ← s 6 • V = r + maxa' Q(s', a') – V = 1 + 0. 5* maxa' Q(s 6, a') • V= 1 • Q(s, a) = Q(s, a) + α[V – Q(s, a)] – Q(s 5, frente) = Q(s 5, frente) + 0. 5*[1 - 0. 5] • Q(s 5, frente) = 0. 75 Recompensa
Desviando de obstáculo (Época 4) • Q(s 1, frente) = -0, 75 Ações • Q(s 1, baixo) = - 0, 5 • Q(s 2, frente) = -0. 5 • Q(s 2, baixo) = - 50 • Q(s 3, baixo) = 0. 5 • Q(s 4, frente) = - 50 • Q(s 4, cima) = -1, 125 • Q(s 5, frente) = 0, 75 • Q(s 5, cima)= 0. 0 Recompensa
Dilema: Aproveitar x Explorar • Quando gulosamento aproveitar da estimação atual da função de valor e escolher ação que a maximiza? • Quando curiosamente explorar outra ação que pode levar a melhorar estimação atual da função valor ? • Taxa de exploração = proporção de escolhas curiosas • Geralmente se começa com uma taxa de exploração alta que vai decrescendo com o tempo.
Maldição da Dimensionalidade • O número de estados possíveis cresce exponencialmente com quantidade de características representadas • Conseqüentemente o tempo de treinamento e número de exemplos necessários também • Q-Learning só pode ser aplicado a problemas relativamente pequenos
Exemplo Arm Robot Problem: http: //www. applied-mathematics. net/ (clicar em control e depois em Q-learning, bem embaixo) Eps: taxa de exploração