Apache Spark Dr smail ER zellikleri Geliim Spark































- Slides: 39
Apache Spark Dr. İsmail İŞERİ
Özellikleri
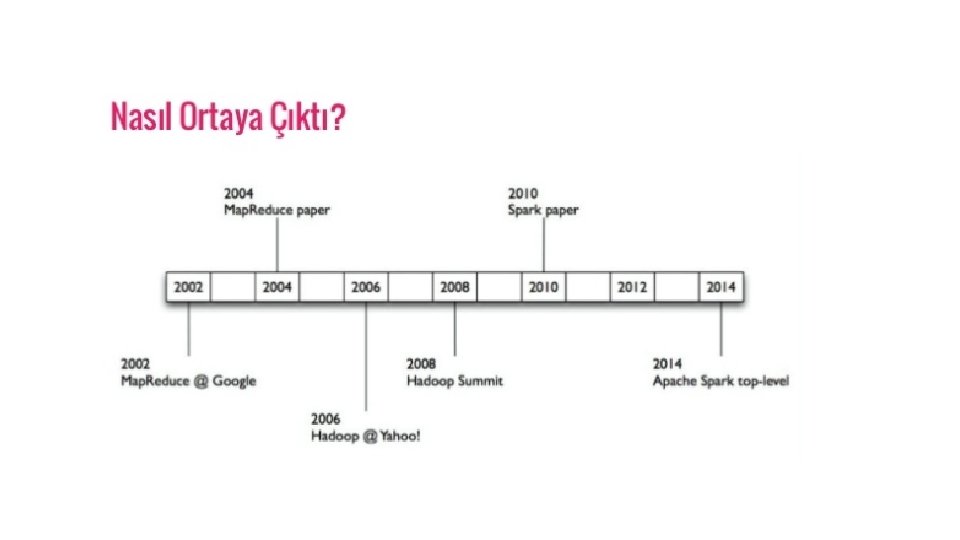
Gelişim • Spark, Hadoop’un 2009 yılında UC Berkeley’deki Matei Zaharia’nın AMPLab’ında geliştirdiği alt projelerinden biri. • 2010 yılında BSD lisansı altında Açık Kaynak kodluydu. • 2013 yılında Apache yazılım vakfına bağışlanmıştır ve Apache Spark şimdi Şubat-2014'ten itibaren üst düzey bir Apache projesi haline gelmiştir.
• Apache Spark hızlı hesaplamalar için tasarlanmış bir küme hesaplama sistemidir. • Hadoop Map. Reduce'un üstüne inşa edildi ve Etkileşimli Sorguları ve Akış İşleme'yi (Interactive Queries and Stream Processing) içeren daha fazla hesaplama türünü verimli kullanmak için Map. Reduce modelini genişletti.
• Endüstri, veri setlerini analiz etmek için Hadoop'u yoğun olarak kullanmaktadır. • Bunun nedeni, Hadoop çerçevesinin basit bir programlama modeline (Map. Reduce) dayanması ve ölçeklenebilir, esnek, hataya dayanıklı ve uygun maliyetli bir bilgi işlem çözümü sağlamasıdır. • Burada asıl mesele, büyük veri setlerinin işleme alınmasında sorgular arasında bekleme süresi ve programı çalıştırmak için bekleme süresidir. • Spark, Hadoop’un hesaplamalı bilgi işlem sürecini hızlandırmak için Apache Software Foundation tarafından geliştirildi.
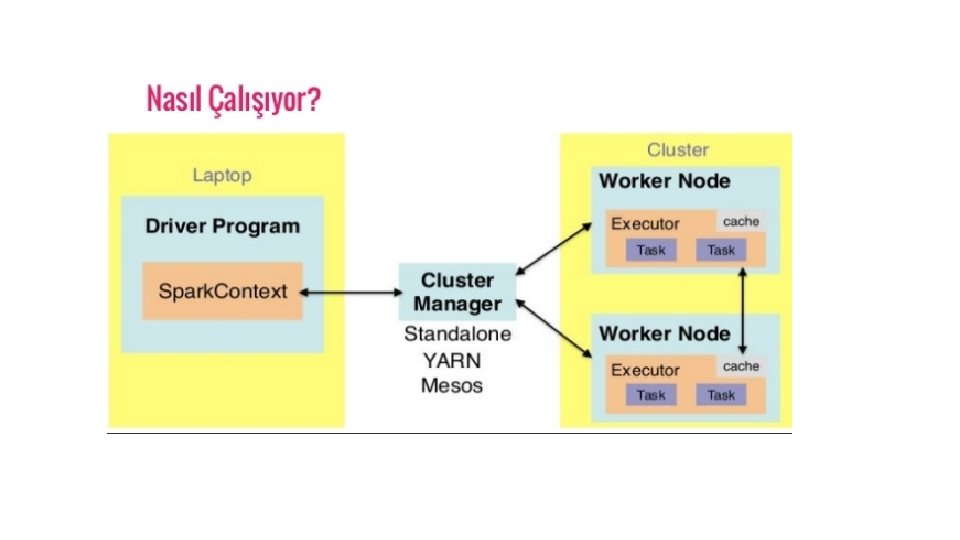
• Spark, Hadoop'un değiştirilmiş bir versiyonu değildir ve kendine ait küme yönetimine sahip olduğu için Hadoop'a bağlı değildir. • Spark, Hadoop'u iki şekilde kullanır - biri depolama, ikincisi işlemedir. Spark kendi küme yönetimi hesaplamasına sahip olduğundan beri, yalnızca depolama amacıyla Hadoop kullanır.
• Spark'ın ana özelliği, bir uygulamanın işlem hızını artıran bellek içi küme hesaplama özelliğidir. (In-memory)
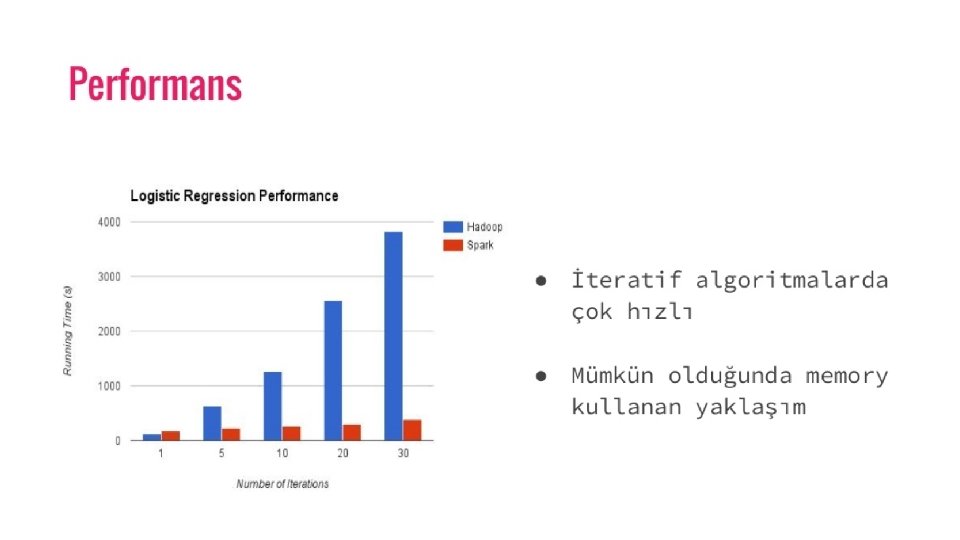
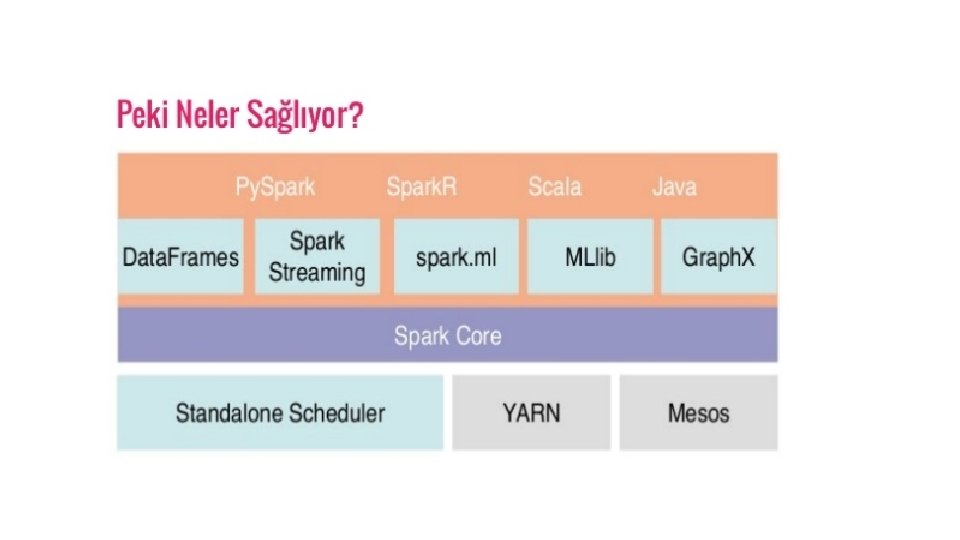
• Hız: Spark, bir uygulamanın Hadoop kümesinde, bellekte 100 kata kadar ve diskte çalışırken 10 kata kadar daha hızlı çalışmasına yardımcı olur. Bu, okuma / yazma işlemlerinin sayısını diske düşürerek mümkündür. Ara işlem verilerini bellekte depolar. • Birden çok dili destekler - Spark, Java, Scala veya Python'da yerleşik API'ler sunar. Bu nedenle, uygulamaları farklı dillerde yazabilirsiniz. Spark, etkileşimli sorgulama için 80 üst seviye operatörle geliyor. • Advanced Analytics - Spark, yalnızca Map Reduce ‘ u desteklemez. Ayrıca SQL sorgularını, Veri akışını, Makine öğrenmesini (ML) ve Grafik algoritmalarını da destekler.
Spark Hadop Üzerine Kurulur
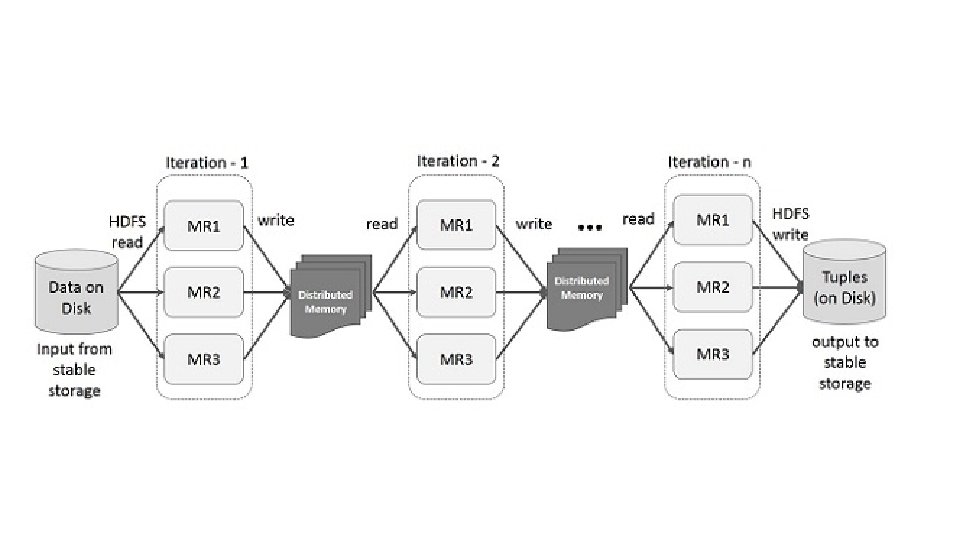
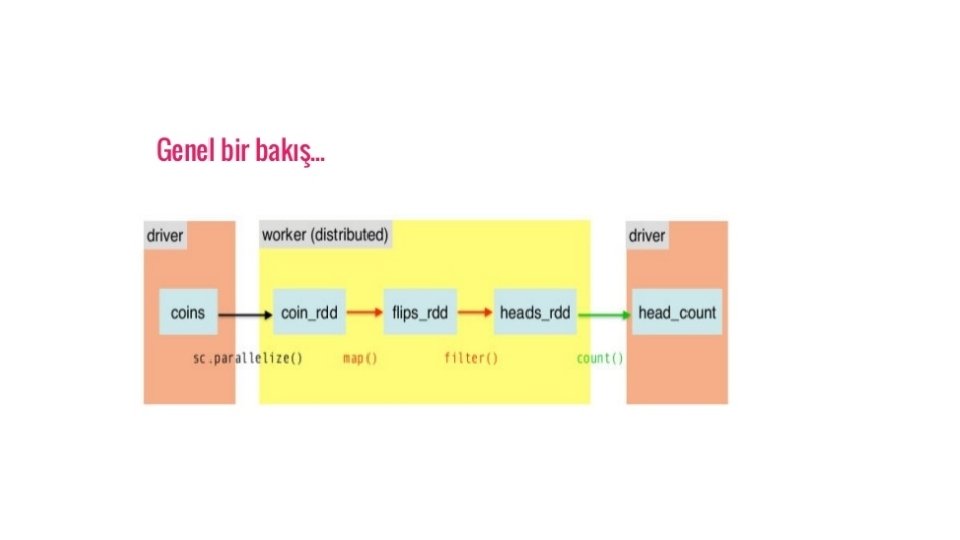
• Spark RDD kullanarak Veri Paylaşımı • Map. Reduce'da çoğaltma, serileştirme ve disk GÇ nedeniyle veri paylaşımı yavaş. Hadoop uygulamalarının çoğu, zamanın% 90'ından fazlasını HDFS okuma-yazma işlemleri yaparak geçiriyorlar. • Bu sorunu tanıyan araştırmacılar, Apache Spark adlı özel bir framework geliştirdiler. Spark ana fikri, Esnek Dağıtılmış Veri Kümeleri'dir (RDD); bellek içi işlem hesaplamasını destekler. • Bu, hafızanın durumunu işler arasında bir nesne olarak depoladığı ve nesnenin bu işler arasında paylaşılabilir olduğu anlamına gelir. Bellekteki veri paylaşımı, ağdan ve Diskten 10 ila 100 kat daha hızlıdır.
• Spark RDD'de İteratif İşlemler • Aşağıda verilen çizim, Spark RDD'deki yinelemeli işlemleri göstermektedir. Ara sonuçları Kararlı depolama (Disk) yerine dağıtılmış bir hafızaya kaydeder ve sistemi daha hızlı hale getirir. • Not : Dağıtılmış hafıza (RAM) ara sonuçları saklamak için yeterli değilse (İŞ'in Durumu), bu sonuçları diskte depolar.
Zengin API