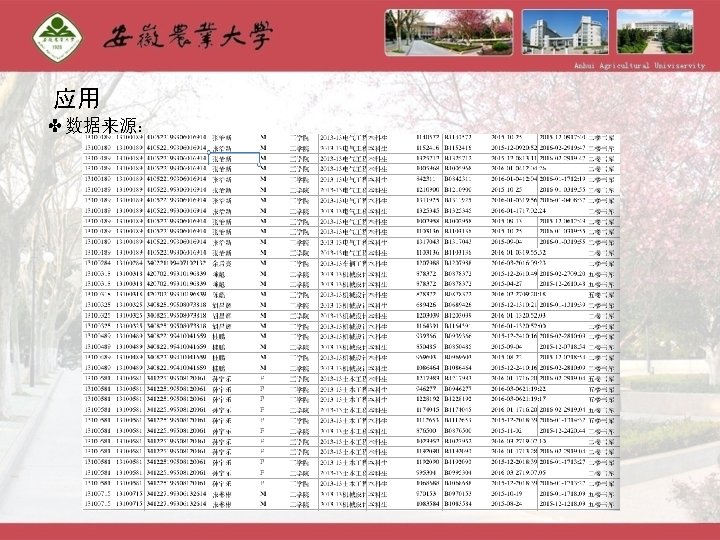
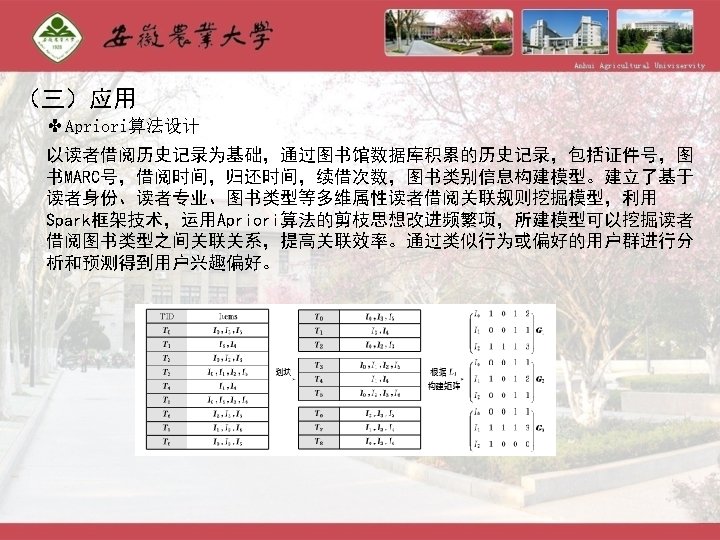
Spark Spark Streaming Graphx MLlib Machine learning Spark













Spark生态系统 Spark Streaming Graphx MLlib Machine learning Spark Mesos YARN Tachyon HDFS MPI Map. Reduce Spark SQL
Spark程序运行模式-独立(Standlone)模式 zookeeper Master Slave Task Driver Task Your. Application Executor Slave Task Executor")
二、Spark平台的相关技术 (二)Spark程序运行模式-独立(Standlone)模式 zookeeper Master Slave Task Driver Task Your. Application Executor Slave Task Executor Driver Your Application

Operator示例 RDD 1 Operation 1 2 3 partitions 4 5 6 7 RDD 2 Operation 2 3 4 MAP( + 1 ) 5 6 SAVEASTEXTFILE(“HD FS: //…”) 7 8 作用在RDD上的operation Storage System HDFS


一个完整的实例:wordcount import org. apache. spark. _ import Spark. Context. _ object Word. Count { def main(args: Array[String]) { if (args. length != 3 ){ println("usage is org. test. Word. Count <master> <input> <output>") return } Master地址 作业名称 val sc = new Spark. Context(args(0), "Word. Count", Spark安装 目录 System. getenv("SPARK_HOME"), Seq(System. getenv("SPARK_TEST_JAR"))) val text. File = sc. text. File(args(1)) val result = text. File. flat. Map(line => line. split("\s+")) 输入数据所在目录,比如: hdfs: //host: port/input/data. map(word => (word, 1)). reduce. By. Key(_ + _) result. save. As. Text. File(args(2)) } } 数据输出目录,比如: hdfs: //host: port/output/data 依赖的jar包


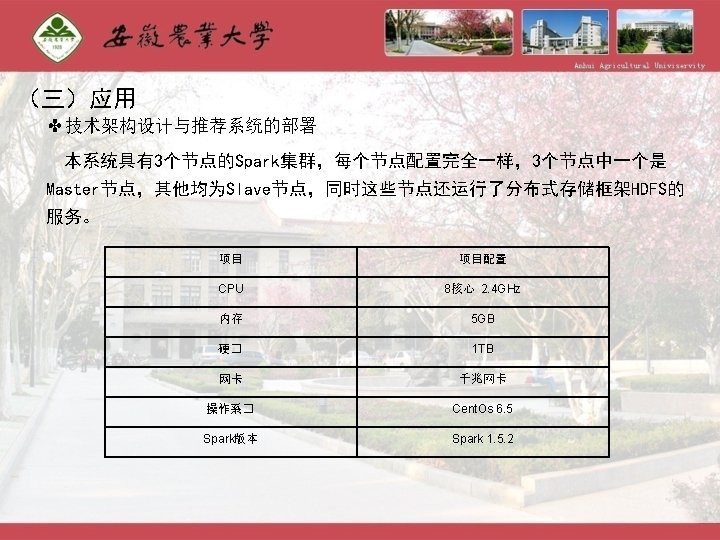
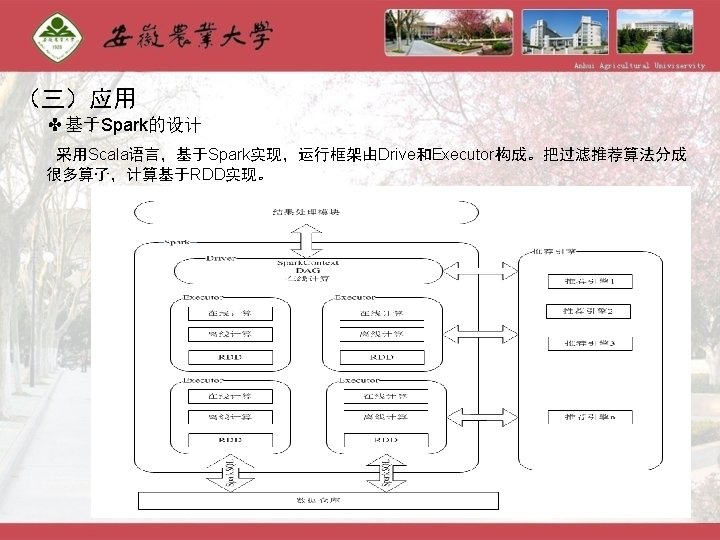
应用 ✤技术架构和部署架构 Web Service Spark MVC 离 线 加 层 Logback ���理� ����理� Mahout")
(三)应用 ✤技术架构和部署架构 Web Service Spark MVC 离 线 加 层 Logback ���理� ����理� Mahout Spark streaming Map/Reduce MLLib JDBC FTP HDFS 具 Sqlite Spark HDFS HBase 数据层访问层 数据层
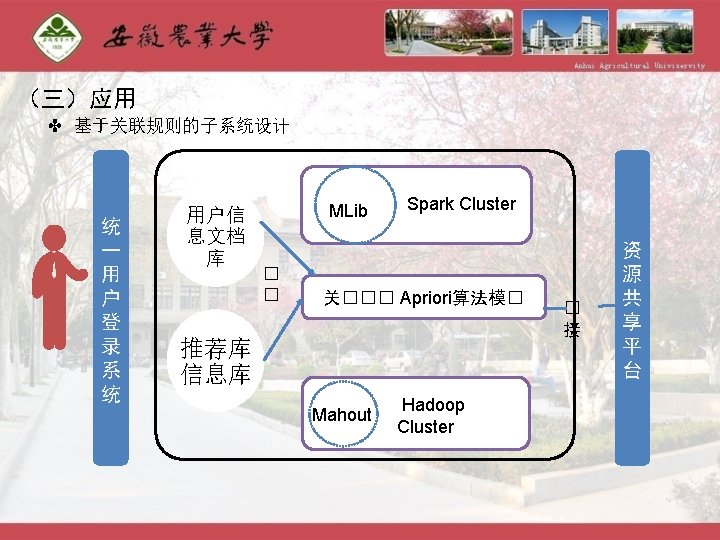

- Slides: 31