Introduction Spark Spark Context Spark Application Spark Context













")











 의 elements 을")


- Slides: 37
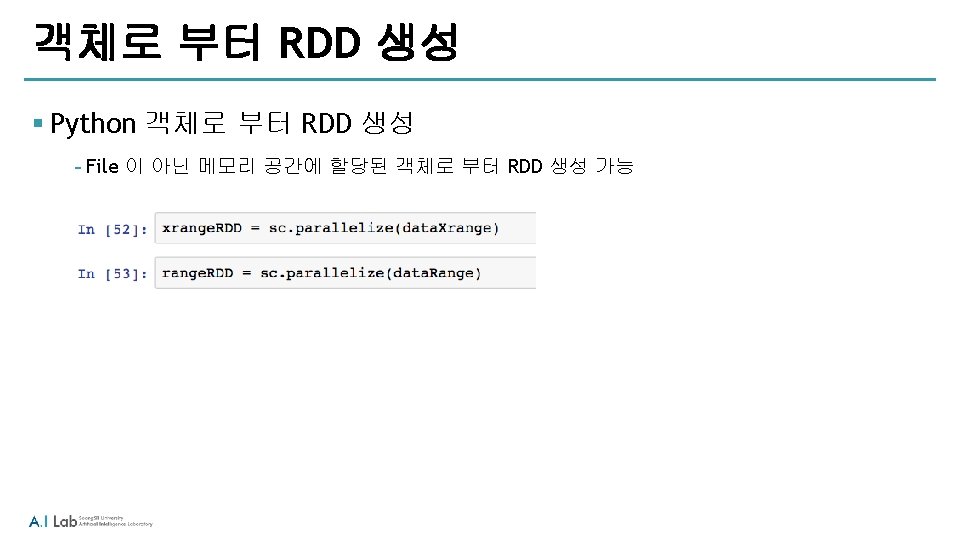
Introduction Spark § Spark Context ‐Spark Application 을 시작할 때, Spark. Context 생성으로 부터 시작 ‐Master node 에서는 동작 가능한 cores 을 사용자의 Spark Application 전용으로 할당 ‐사용자는 보통 Spark Context 를 사용하여 RDD(Resilient Distributed Datasets) 생성에 사용
Spark. Context § 기본적인 Spark. Context 시작 방법 from pyspark import Spark. Conf, Spark. Context conf = (Spark. Conf(). set. Master("local"). set. App. Name("My app"). set("spark. executor. memory", "1 g")) sc = Spark. Context(conf = conf) local mode 사용 사용자 Application 이름 executor 메모리 할당 최종 Spark. Context 를 sc 변수로 할당 § 실습 환경에서는 기본적으로 ”sc” 변수로 Spark. Context 할당되어 있음
Spark. Context
Spark. Context § Application 이름 바꾸기
RDD lineage 와 type 확인 § RDD 의 lineage 확인 § RDD 의 type 확인
map 함수 § map 함수에 sub 함수를 전달함으로서 각 partition의 모든 데이터에 대해 sub 함수 적용 Spark 에서 map 함수 적용 과정 sub partition #1 partition #2 partition #3 partition #4 RDD 1 RDD 2
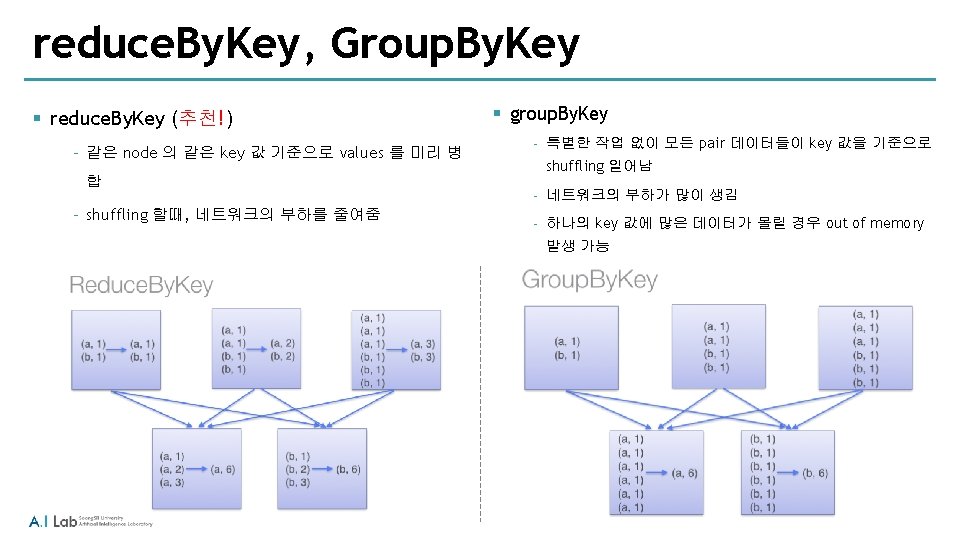
group. By. Key § group. By. Key
group. By. Key § group. By. Key / group. By. Key with sum(value)
group. By. Key § group. By. Key with map / group. By. Key with map. Values
group. By. Key § group. By. Key , map. Values
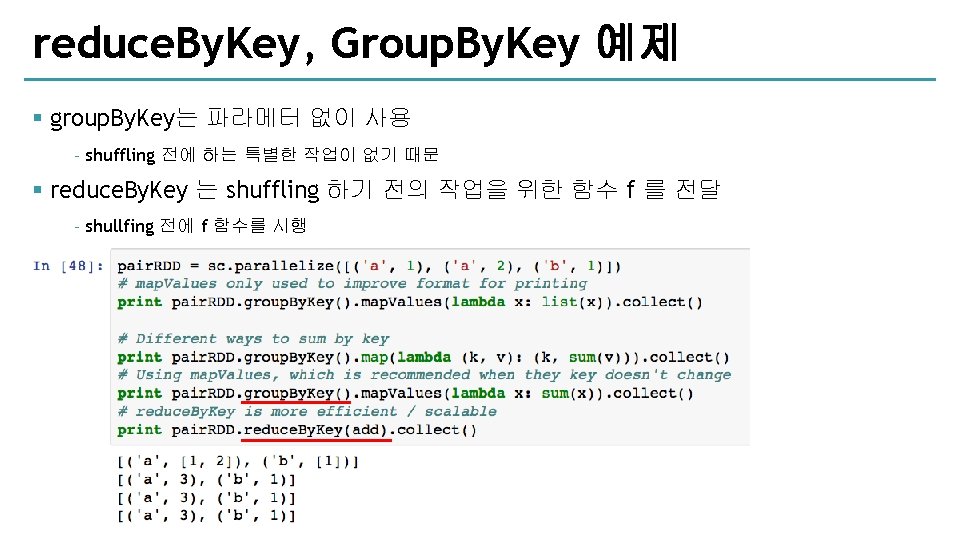
reduce. By. Key § reduce. By. Key
count. By. Value § count. By. Value
Map : python & py. Spark § map : python & py. Spark
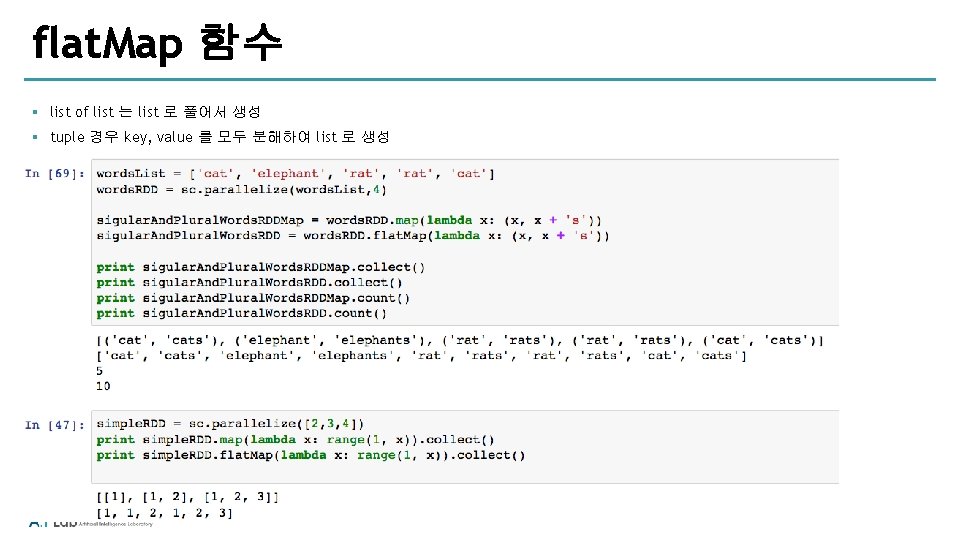
py. Spark map & flat. Map § py. Spark map & flat. Map Result of pyspark map Result of pyspark flatmap
py. Spark flat. Map reduce. By. Key § py. Spark flat. Map reduce. By. Key
word. Count : py. Spark flat. Map reduce. By. Key sort. By. Key § Word. Count : py. Spark flat. Map, reduce. By. Key, Sort. By. Key
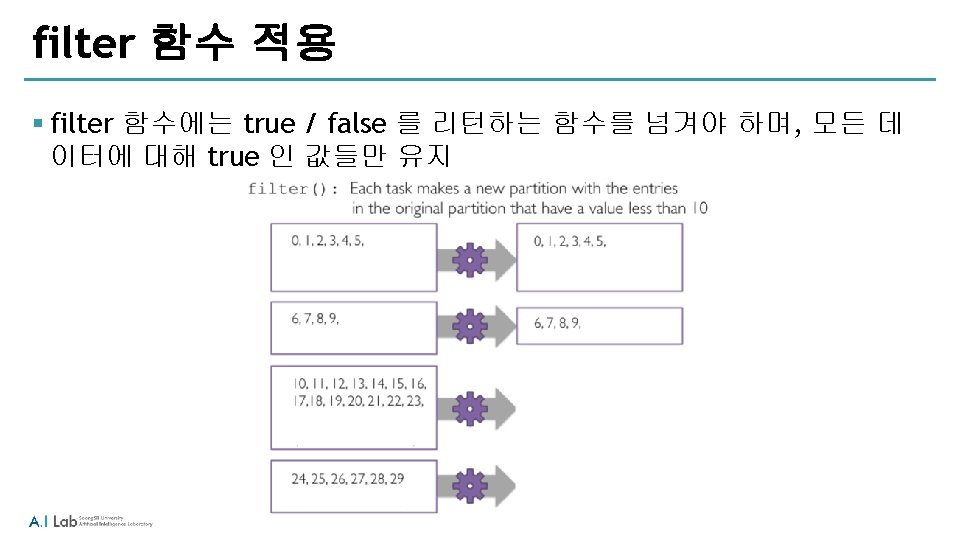
reduce 함수 § hodoop의 reduce 와 유사하며, reduce 함수의 파라매터로 function 을 전달 ‐ reduce 에 전달할 function은 항상 associative 하고 commutative 해야 함 ‐ associative : a + (b + c) = (a + b) + c e. g. 2 + (3 + 4) = (2 + 3) + 4 ‐ commutative : a + b = b + a e. g. 2 + 3 = 3 + 2 partition 변경에 따라 값이 다름!!
reduce. By. Key, Group. By. Key 사용한 Word. Count : dictionary type
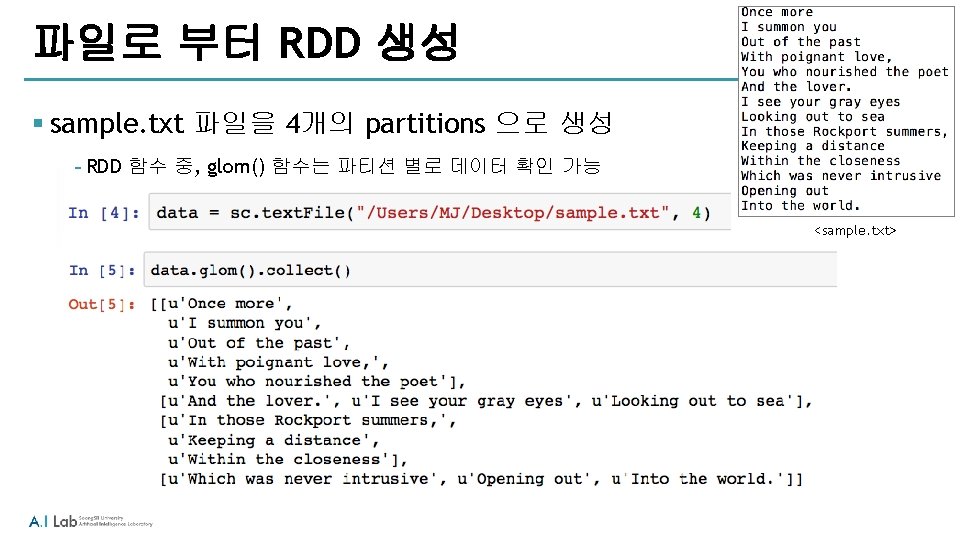
Word. Count key 를 tuple의 value 로 인식하여 정렬하라는 의미 1 2 3 4 <sample. txt> * reduce. By. Key 함수는 22 p 에 설명
join 함수 § 특정 delimiter 를 사용하여 Sequence 타입(list, tuple, etc) 의 elements 을 연결 ‐element의 타입이 string 형태만 가능
map. Partitions, map. Partitions. With. Index 함수 § map. Partitions 함수 ‐자신의 Partition 안에서만 f 함수 연산 § map. Partitions. With. Index 함수 ‐index 가 자동으로 추가된 tuple(index, Sequence type) 형태의 데이터를 자신의 Partition 에서만 f 함수 연산 sequence 타입의 객체 int, sequence 타입
End !