SDT We associate information with a programming language









, 將有中間碼(intermediate code)")






 L En print (E. val) E E 1 + T")







- Slides: 28
此章介紹如何將語法依附以語意屬性值; 即 SDT. We associate information with a programming language construct by attaching attributes to the grammar symbols representing the construct. Values for attributes are computed by “semantic rules” associated with the grammar productions. There are two notations for associating semantic rules with productions, syntax-directed definitions and translation schemes. Syntax-directed definitions are high-level specifications for translations. They hide many implementation details and free the user from having to specify explicitly the order in which translation takes place. Translation schemes indicate the order in which semantic rules are to be evaluated, so they allow some implementation details to be shown. 9/15/2021 1
The translation of the token stream is the result obtained by evaluating the semantic rules (conceptual view of SDT) Input string Parse tree Dependency graph Evaluation order For semantic rules To translate a programming language construct, a compiler may need to keep track of many quantities besides the code generated for the construct. For example, the compiler may need to know the type of the construct, or the location of the first instruction in the target code, or the number of instructions generated. We therefore talk abstractly about attributes associated with constructs. An attribute may represent any quantity, e. g. , a type, a string, a memory location, or whatever. A syntax-directed definition uses a context-free grammar to specify the syntactic structure of the input. With each grammar symbol, it associates a set of attributes, and with each production, a set of semantic rules for computing values of the attributes associated with the symbols appearing in that production. The grammar and the set of semantic rules constitute the syntax directed definition. 9/15/2021 2
Attribute Grammars z. Def: An attribute grammar is a cfg G = (S, N, T, P) with the following additions: y. For each grammar symbol x there is a set A(x) of attribute values y. Each rule has a set of functions that define certain attributes of the nonterminals in the rule y. Each rule has a (possibly empty) set of predicates to check for attribute consistency Attribute grammars are grammars to which have been added attributes, attribute computation functions, and predicate functions. 9/15/2021 3
X 0 Attribute Grammars X 1 X 2. . . Xn z. Let X 0 X 1. . . Xn be a rule z. Functions of the form S(X 0) = f(A(X 1), . . . , A(Xn)) define synthesized attributes z. Functions of the form I(Xj) = f(A(X 0), . . . , A(Xj-1)), for 1 <= j <= n, define inherited attributes z. Initially, there are intrinsic attributes on the leaves 9/15/2021 4
Attribute Grammars z Example: expressions of the form id + id yid's can be either int_type or real_type ytypes of the two id's must be the same ytype of the expression must match it's expected type(from top down) z BNF: <expr> <var> + <var> id z Attributes: yactual_type - synthesized for <var> and <expr> 9/15/2021 yexpected_type - inherited for <expr> 5
1. <assign> <var> = <expr> 2. <expr> <var>1 + <var>2 3. <expr> <var> 4. <var> A | B Rule 1 Syntax rule: <assign> <var> = <expr> Semantic rule: <expr>. expected_type <var>. actual_type Syntax rule: <expr> <var>1 + <var>2 Semantic rule: <expr>. actual_type if (<var>1. actual_type = int) and (<var>2. actual_type = int) then int else real end if Predicate: <expr>. actual_type = <expr>. expected_type 9/15/2021 Rule 2 6
Syntax rule: <expr> <var> Semantic rule: <expr>. actual_type <var>. actual_type Rule 3 Predicate: <expr>. actual_type = <expr>. expected_type Rule 4 Syntax rule: <var> A | B Semantic rule: <var>. actual_type look-up(<var>. string) To compute the attribute values, the following is a possible sequence: 1. <var>. actual_type look-up(A) (Rule 4) 2. <expr>. expected_type <var>. actual_type (Rule 1) 3. <var>1. actual_type look-up(A) (Rule 4) 4. 4) 9/15/2021 <var>2. actual_type look-up(A) (Rule 4. <expr>. actual_type either int or real 5. <expr>. expected_type = <expr>. actual_type is either (Rule 2) 7
<assign> T or F ? ⑥ Expected_type <expr> ⑤ ② Actual_type <var> Actual_type ⑤ Actual_type <var>1 ① A Actual_type <var>2 ③ = A ④ + B Now you may take a close look at the Fig. 3. 8 of a “Fully attributed” parse tree 9/15/2021 8
Attribute Grammars z. How are attribute values computed? y. If all attributes were inherited, the tree could be decorated in top-down order. y. If all attributes were synthesized, the tree could be decorated in bottom-up order. y. In many cases, both kinds of attributes are used, and it is some combination of top-down and bottom-up that must be used. 9/15/2021 9
Now let us take a look on forward branching problem. 此相為一語意處理相(semantic processing), 將有中間碼(intermediate code) 產生. 今以例示之. E. code: sequence of three-address code to evaluate E. E. place: place where E’s value resides at runtime. E id {E. code : = null, E. place : = id. place} E E(1) * E(2) {E. place : = Newtemp( ), E. code : = E(1). code // E(2). code // gen( E. place “: =“ E(1). place “*” E(2). place) } E -E(1) {E. place : = Newtemp( ), E. code : = E(1). code // gen( E. place “: =“ ‘uminus’ E(1). Place) } A id: =E {A. code : = E. code // gen(id. place “: =“ E. place) } 其語意之處理過程以 Bubble 圖示如次頁: 9/15/2021 10
Bubble Input a : = b * -c $ id a ““ id a ““ 9/15/2021 id : = id * -id$ . place. CODE : = : = id * -id$ id b ““ E b ““ : = E b ““ * -id $ * - * - * id c ““ $ E t 1: = -c $ 11
id a ““ E t 2 : = b*t 1 : = S a a : = t 2 $ $ t 1 : = -c t 2 : = b*t 1 a : = t 2 但是有些不妙的問題卻發生了: (1) forward branching, (2)inserting GOTO instruction. 9/15/2021 12
<label> : : = id: { if id. place. quad is defined then error(“Duplicate label defined”); else id. place. quad = Next. Quad; backpatch( id. place. fwdref, Next. Quad); } <stmt> : : = goto id { if id. place. quad is defined then gen(‘goto’ id. place. quad) : else append( id. place. fwdref, Next. Quad) ; gen( ‘goto’ ? ); } Backpatch 是一旦找到id 之location 值, 則 回填任何與此 id相關之等待goto? 處 append 是將此未定義之id. place. fwdref位置linking 到list 中, 以做為未來 backpatch之用. 9/15/2021 13
S : : = if E then S 1 <else> S 2 fi {backpatch(E. true, S 1. 1 stquad); backpatch(E. false, S 2. 1 stquad); S. next : = merge(<else>. quad, S 1. next, S 2. next)} <else> : : = else {<else>. quad : = Nextquad; gen(‘goto’ ? ) } S : : = while E do S 1 done {backpatch(E. false, S 1. next ); backpatch( E. true, S 1. 1 stquad); S. next = E. false; S. 1 stquad = E. 1 stquad; gen( ‘goto’ E. 1 stquad) } 也也人將文法改成 S : : = if E then S 1 M else S 2 fi M : : = 9/15/2021 14
現在用一實例說明 SDD(例 5. 1) L En print (E. val) E E 1 + T E. val : = E 1. val + T. val E T E. val : = T. val T T 1 * F T. val : = T 1. val * F. val T F T. val : = F. val F (E) F. val : = E. val F digit F. val : = digit. lexval 9/15/2021 18
用 3*5+4 n 這個輸入字串與上上一頁之SDD, 可得annotated parse tree 如下圖, 而由下而上計算整棵parse tree, 則可列印 19. L n E. val = 19 E. val = 15 + T. val=15 T. val=3 F. val=3 digit. lexcal=3 9/15/2021 * F. val=5 T. val=4 F. val=4 digit. lexcal=5 3*5+4 n 之標上屬性的語法解析樹 20
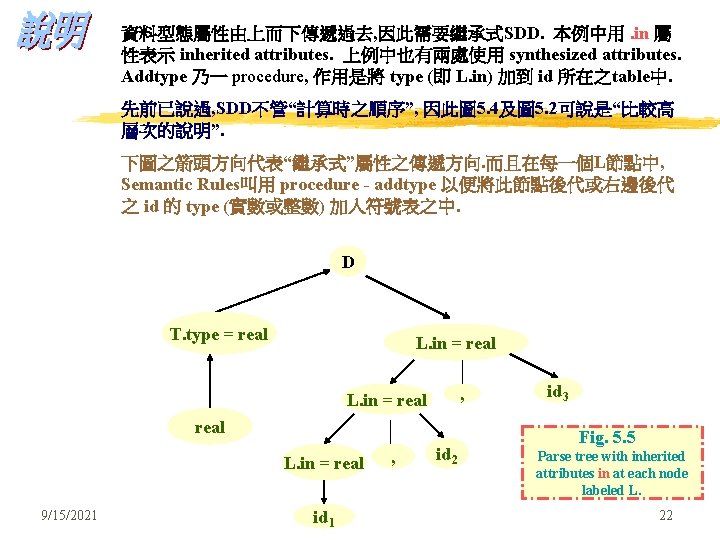
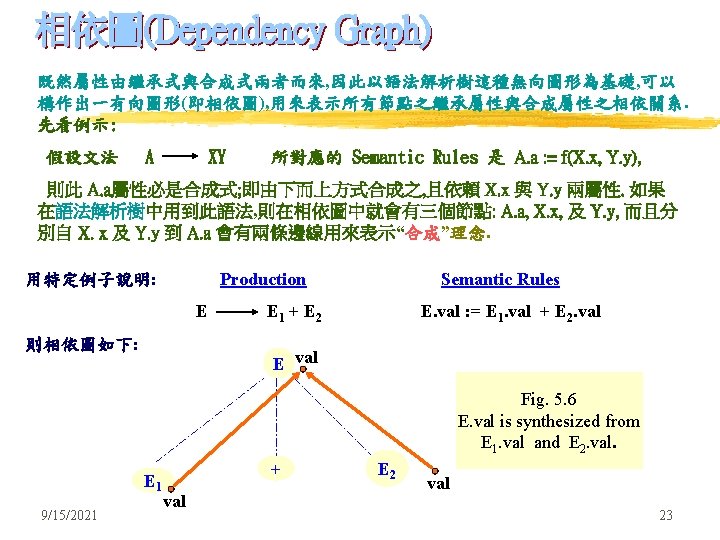
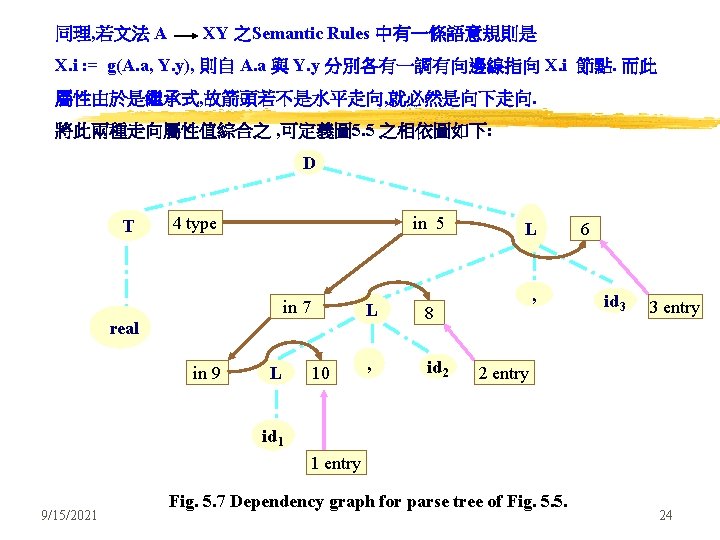
S-attributes 已看過, 現在轉為研究 Inherited Attributes. 眾所周知, 繼承式屬性即表示解析樹中節點之屬性值來自此節點之祖先或同輩各 節點之屬性值. 何以要有此 Inherited Attributes ? Ans: 因為有些屬性來自parse tree之由上而下順序情況時之上層節點. 舉例來說: 像 data type, upper bound 或 lower bound 等皆然. 用例示說明此觀點: (例 5. 3) production Semantic Rules D TL L. in : = T. type (Inherited) T int T. type : = integer (Synthesized) T real T. type : = real (Synthesized) L L 1, id L 1. in : = L. in (Inherited) addtype(id. entry, L. in) (Inherited) L id 圖 5. 4 9/15/2021 先定義宣告部之文法及其對應之語意規則 用L. in 繼承式屬性之SDD 21