Managing securing and scaling Azure Service Fabric clusters

Managing, securing, and scaling Azure Service Fabric clusters and applications

1. 2. 3. 4. 5. 6. 7. Service Fabric Azure Client Modules Best practices for planning your cluster Best practices for business continuity planning Best practices for securing your cluster Application and Services as ARM resources Monitoring and diagnostics Road map

SDK Available Dev Box Managed Service Deployment Packages ing Com Azure soon On-Premise Data centers Azure Stack Coming soon Deployment Packages oon ing s Com Other Clouds

• • • Azure. RM. Service. Fabric powershell module az sf cli module Automates many E 2 E scenarios • • • Ships as a part of Azure Power. Shell and CLI respectively Both the modules are supported in cloud shell In preview for now, so feedback is appreciated

Ships with four parameter sets New-Azure. Rm. Service. Fabric. Cluster -Resource. Group. Name $RGname Location $clusterloc -Cluster. Size $num. Nodes -Vm. Password $pwd -Certificate. Subject. Name $subname -Certificate. Password $pwd -Certificate. Output. Folder $pfxfolder Let us see this in action.

Demo #1

Safest option: Add nodes Add-Azure. Rm. Service. Fabric. Node -Resource. Group. Name $RGname -Name $cluster. Name Node. Type $node. Type -Number $add. Num. Nodes az sf cluster node add --cluster-name --node-type --number-of-nodes-to-add resource-group -- Remove-Azure. Rm. Service. Fabric. Node -Resource. Group. Name $RGname -Name $cluster. Name Node. Type $node. Type -Number $add. Num. Nodes az sf cluster node remove --cluster-name --node-type --number-of-nodes-to-remove --resource-group Let us see this in action.

Demo #2

Key points: this document

Define what the cluster will be used for Determine the node types and sizes Are there any unique compliance or security requirements?


Reliability Tier Bronze Silver Gold System service replica set size 3 5 7 Platinum 9

• Run production workloads in Azure at Silver or higher • Adjust the reliability tier on scale out or in Reliability Tier Bronze Silver Gold Platinum System service replica set size 3 5 7 9 Recommended for Cluster Size of 3 5 or 6 7 or 8 9 and up; Cross AZ or Cross Region

Durability Tier Infra privilege time out Available on VMs SKUs Bronze 0 mins All supported VM SKUs Silver 10 mins All supported VM SKUs Gold 120 mins Full node SKUs like D 15_V 2, G 5

Service replica lifecycle events Durability Tier Bronze Silver Gold Infra privilege time out 0 mins 120 mins Available on VMs SKUs All supported VM SKUs Full node SKUs like D 15_V 2, G 5 Read this carefully : https: //docs. microsoft. com/en-us/azure/service-fabric-cluster-capacity

Keep a written, updated, Business Continuity Define what your RPO and RTO are • RPO The Recovery Point Objective (RPO) determines the amount of data you can afford to lose in a disaster • RTO The Recovery Time Objective (RTO) is the maximum tolerable length of time that your service can be down after a disaster occurs Backup your application state to meet your RPO Set up clusters across Availability Zones or Even Regions.
 are physically separated locations within an Azure region 3 zones in")
Availability Zones (AZ) are physically separated locations within an Azure region 3 zones in each AZ-enabled region Each zone has independent power, network, and cooling. Each AZ has 1 to infinite # of DCs. No DC shared by two zones. VM to VM network latency: Intra-AZ < 1 ms, inter-AZ < 2 ms

Subnet #1 Availability Zone #1 VMSS #3 VMSS #1 VMSS #2 Traffic Manager Subnet #1 Availability Zone #2 Single VNet Subnet #3 Availability Zone #3

Use a cross AZ cluster when • Want to survive an azure zone going down • RPO and RTO = 0 • Slightly higher write latency than a cluster in a single AZ Back up your application State irrespective • To be used for regional failures and OOPS recovery Minimum Cluster size • Has to be across 3 or more AZs • Primary node type - 9 VMs minimum

Has to span at least 3 regions. Use it when the • Want to survive an azure region going down • RPO and RTO = 0 • Higher write latency than across AZ is acceptable Back up your application State • To be used for OOPS recovery Minimum Cluster size • Has to be across 3 or more Regions • Primary node type – 9 VMs minimum

Demo #3

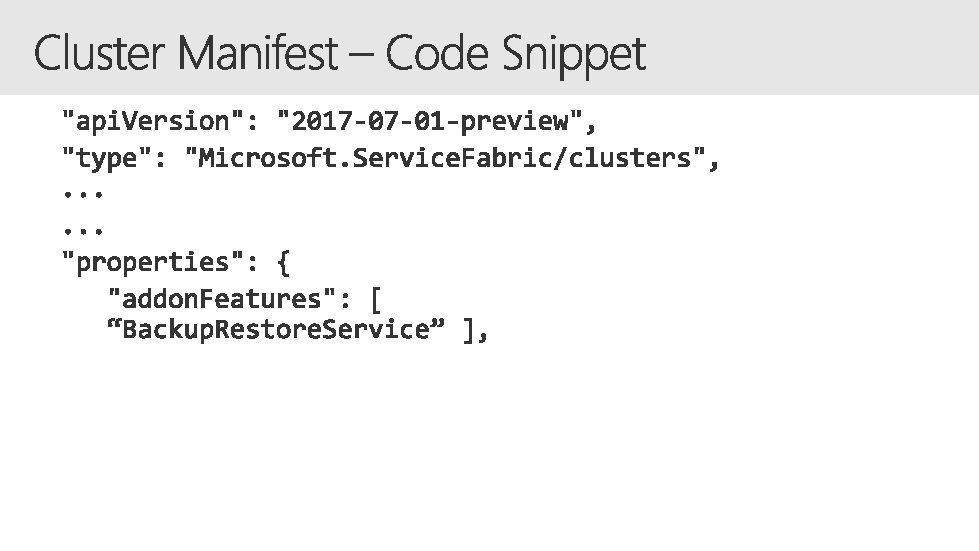
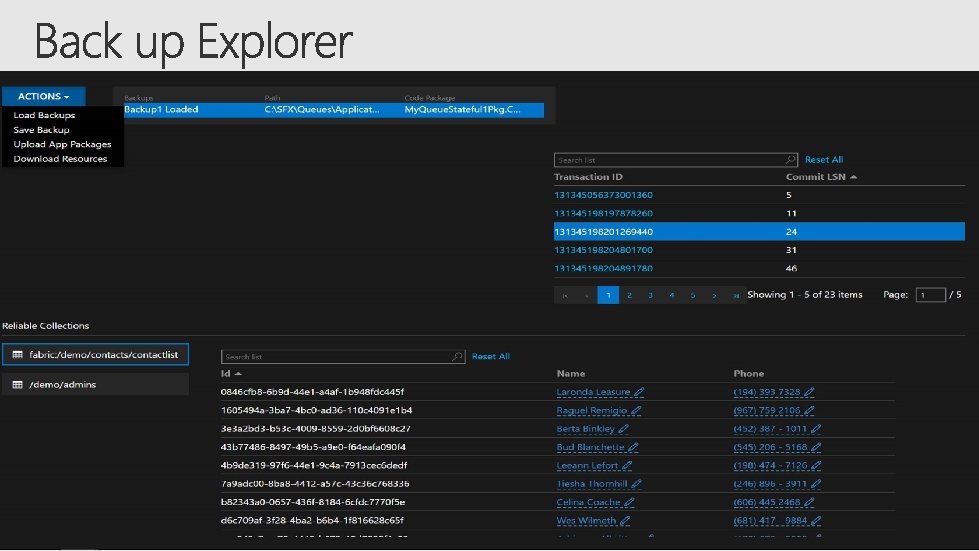
• • • Supports both Reliable Actors and reliable Services. Allows for custom backup policies– backup schedule, retention, backup location etc Supports backup policies at application, service or partition level. Works on both Azure and on-premise clusters. Supports enumerating backups and viewing them in Backup Explorer Supports restoration of a partition from a backups. • • Create xstore account (Azure) or file share for uploading backups Enable Backup Restore service by adding it as add. On. Feature. Best Practice • Enable backup service on your cluster, if you run stateful services in your cluster

Demo #4

Types of Disasters RPO and RTO = 0, Write latency acceptable RPO and RTO > 0 Regional Outage Cross-regional SF cluster Stand up a new cluster, restore from backup Data Center Outage Cross AZ (3+) SF cluster Stand up a new cluster, restore from backup Cluster down (Very low probability for crossregional clusters) Stand up a new cluster, restore from backup Deploy across 5+ FDs, 5+ UDs, Design for write quorum losses Stand up a new cluster, restore from backup Restore from backup Machine / Node down Other sources of data loss or “oops” Deploy across 5+ FDs, 5+ UDs, Design for write quorum losses

Use the ARM template to customize your cluster Use the ARM template to drive changes to your Resource Group Avoid using implicit commands to tweak your resources Treat your cluster configuration as code


Demo #5

Always use a secure cluster Additionally consider the following:

Always use a secure cluster: use AD Additionally consider the following:

this document

Demo #7

Cluster and Node state Is the cluster healthy? Are all the nodes up? Detect and diagnose hardware and infrastructure issues Application and Service state Upgrade status, number of services and replicas Detect software and app issues, reduce service downtime Resource Usage Do all the nodes need to be up? What is the average CPU usage? Understand resource consumption and drive better business decisions Performance Tracking Is there any unexpected latency? Are the services responsive? Optimize application, service, and infrastructure performance Custom Application Metrics Is your app being used in the way that you expected? Is solution effective? Generate business insights and improvements

Cluster and Node state Is the cluster healthy? Are all the nodes up? Detect and diagnose hardware and infrastructure issues Application and Service state Upgrade status, number of services and replicas Detect software and app issues, reduce service downtime Resource Usage Do all the nodes need to be up? What is the average CPU usage? Understand resource consumption and drive better business decisions Performance Tracking Is there any unexpected latency? Are the services responsive? Optimize application, service, and infrastructure performance Custom Application Metrics Is your app being used in the way that you expected? Is solution effective? Generate business insights and improvements

Cluster and Node state Is the cluster healthy? Are all the nodes up? Detect and diagnose hardware and infrastructure issues Application and Service state Upgrade status, number of services and replicas Detect software and app issues, reduce service downtime Resource Usage Do all the nodes need to be up? What is the average CPU usage? Understand resource consumption and drive better business decisions Performance Tracking Is there any unexpected latency? Are the services responsive? Optimize application, service, and infrastructure performance Custom Application Metrics Is your app being used in the way that you expected? Is solution effective? Generate business insights and improvements

Cluster and Node state Is the cluster healthy? Are all the nodes up? Detect and diagnose hardware and infrastructure issues Application and Service state Upgrade status, number of services and replicas Detect software and app issues, reduce service downtime Resource Usage Do all the nodes need to be up? What is the average CPU usage? Understand resource consumption and drive better business decisions Performance Tracking Is there any unexpected latency? Are the services responsive? Optimize application, service, and infrastructure performance Custom Application Metrics Is your app being used in the way that you expected? Is solution effective? Generate business insights and improvements

Cluster and Node state Is the cluster healthy? Are all the nodes up? Detect and diagnose hardware and infrastructure issues Application and Service state Upgrade status, number of services and replicas Detect software and app issues, reduce service downtime Resource Usage Do all the nodes need to be up? What is the average CPU usage? Understand resource consumption and drive better business decisions Performance Tracking Is there any unexpected latency? Are the services responsive? Optimize application, service, and infrastructure performance Custom Application Metrics Is your app being used in the way that you expected? Is solution effective? Generate business insights and improvements

Demo #6


1. 2. 3. 4. 5. 6. 7. Service Fabric Azure Power. Shell or CLI Module Best practices for planning your cluster Best practices for securing your cluster Best practices for business continuity planning Application and services as ARM resources Monitoring and diagnostics Road map http: //aka. ms/servicefabric

Day Time Session Code Session Room Monday Sept 25 th 4 PM – 5. 15 PM BRK 3208 Azure Service Fabric overview and the road ahead OCCC S 310 Tuesday Sept 26 th 12. 30 PM – 1. 45 PM BRK 3331 Azure Service Fabric for Linux OCCC W 224 Wednesday Sept 27 th 12: 05 PM - 12: 25 PM THR 2159 Monitor your microservices with Application Insights OCCC South Expo Theater #1 Wednesday Sept 27 th 2: 15 PM - 3: 30 PM BRK 3189 Modernizing existing. NET applications with Windows Containers and Azure cloud OCCC S 310 Wednesday Sept 27 th 2. 15 PM – 3. 30 PM BRK 2190 Orchestrating one million containers with Azure Service Fabric OCCC W 208 AB Wednesday Sept 27 th 4 PM – 5. 15 PM BRK 3209 Managing, securing, and scaling Azure Service Fabric clusters and applications OCCC S 310 HOL 3041 Deploying and scaling Windows and Linux containers on Azure Service Fabric Hands-on Labs Room Any time

Service Fabric developer SDK http: //aka. ms/Service. Fabric. SDK Service Fabric documentation http: //aka. ms/Service. Fabricdocs Learn from samples, free clusters and labs http: //aka. ms/Service. Fabric. Samples http: //aka. ms/try. Service. Fabric Comprehensive resources list https: //aka. ms/focuson/asf Questions, comments, issues http: //aka. ms/Service. Fabric. Forum https: //github. com/azure/service-fabric-issues
- Slides: 44