Kvantitativn metody vzkumu vzdlvn David Greger david gregerpedf

 Výběr vzorku • Vzorek (neboli výběrový soubor) skupina")

: • nevycházejí")
: Kvótní")
: Účelový")
: Anketa")
")





 • Absolutní velikost výběrového souboru je důležitější než relativní velikost")

 • Heterogenita populace ve sledovaném znaku – Čím větší")


 • Rozdělení pravděpodobnosti relativních četností")
 - napravují nestejnou pravděpodobnost výběru jednotek.")






- Slides: 27
Kvantitativní metody výzkumu vzdělávání David Greger david. greger@pedf. cuni. cz 221 900 528 (M 208)
Krok 3 Výběr vzorku (účastníků výzkumu) Výběr vzorku • Vzorek (neboli výběrový soubor) skupina jednotek, které skutečně pozorujeme • Populace (neboli základní soubor) je soubor jednotek, o kterém předpokládáme, že jsou pro něj naše závěry platné Stěžejní úkol v pedagogickém výzkumu je najít takový postup, aby výsledky, které získáme na vzorku, byly co nejvíce podobné těm, které bychom získali na celé populaci
Úvod k tvorbě výběru – metody sběru dat
Typy výběrů Výběrové techniky založené na logickém úsudku – nenáhodné výběry (empirické): • nevycházejí z teorie pravděpodobnosti • abychom byli schopni z chování vzorku předpovídat chování populace, musí struktura vzorku imitovat složení populace tak přesně, jak jen to je možné (když je v populaci řekněme 51% žen, vybereme 51% žen do vzorku, a když je v populaci 12% osob nad 65 let věku, vybereme také stejné procento starých osob do vzorku, apod. ) → kvótní výběr
Typy výběrů -nepravděpodobnostní Výběrové techniky založené na logickém úsudku – nenáhodné výběry (empirické): Kvótní výběr • imituje ve struktuře vzorku známé vlastnosti populace • může být použit jen na populaci, o které jsme dobře informováni (o jejím složení, struktuře) • dobrá shoda základního a výběrového souboru podle jednoho sledovaného znaku; v kombinaci znaků je jeho přesnost podstatně nižší • používá se tehdy, když je známa struktura základního souboru, ale základní soubor je obtížně definovatelný jako soubor konkrétních jedinců, např. proto, že neexistuje jejich žádný seznam • problém s praktickou stránkou výběru přímo v terénu
Typy výběrů -nepravděpodobnostní Výběrové techniky založené na logickém úsudku – nenáhodné výběry (empirické): Účelový výběr • založen pouze na úsudku výzkumníka o tom, co by mělo být pozorováno a o tom, co je možné pozorovat • ne příliš vědecký avšak mnohdy jediný možný přístup (např. etnické minority – neexistence seznamu všech příslušníků této minority, nutno se uspokojit se seznamy členů etnických organizací i za předpokladu, že zde nejsou organizováni zdaleka všichni) • téměř nikdy neumožňuje širokou generalizaci našich závěrů, je zde vždy nutné jasně, přesně a otevřeně definovat populaci, kterou tento náš vzorek reprezentuje
Typy výběrů -nepravděpodobnostní Výběrové techniky založené na logickém úsudku – nenáhodné výběry (empirické): Anketa • výběr jedinců založený na rozhodnutí respondenta zodpovědět otázky uveřejněné v masových sdělovacích prostředcích • nelze definovat populaci, ke které se nálezy ankety vztahují – nejsou to všichni čtenáři určitých novin či časopisů, jsou to právě jen ti, kteří zodpověděli anketu Technika sněhové koule • spíše technika identifikace populace než vytvoření reprezentativního vzorku • výběr jedinců, při kterém nás nějaký původní informátor vede k jiným členům naší cílové skupiny
Typy výběrů -pravděpodobnostní Výběrové techniky založené na teorii pravděpodobnosti – náhodné výběry: Náhodný (pravděpodobnostní) výběr • každý element musí mít stejnou šanci, že bude vybrán do vzorku • čím větší vzorek, tím menší rozdíl mezi strukturou populace a strukturou vzorku (úplné shody mezi strukturami bychom dosáhli, kdybychom zahrnuli všechny elementy populace do vzorku) • reprezentuje všechny známé i neznámé vlastnosti populace • jsme schopni odhadnout, jak se vzorek liší od populace (jak je dobrý) – pomocí směrodatné odchylky
Typy výběrů -pravděpodobnostní Výběrové techniky založené na teorii pravděpodobnosti – náhodné výběry: Prostý náhodný výběr • očíslování jednotlivců v seznamu populace a jejich vybírání dle vygenerování náhodných čísel, losem (s vracením či bez) Systematický výběr • do vzorku je zahrnuta každá n-tá jednotka ze seznamu (velikost n dostaneme, vydělíme-li velikost populace velikostí požadovaného vzorku) • důležité je, aby první jedinec byl vybrán náhodně a teprve od tohoto výchozího bodu budeme vybírat každou n-tou jednotku • nelze použít, jsou-li seznamy řazeny podle nějakého systematického schématu
Typy výběrů -pravděpodobnostní Výběrové techniky založené na teorii pravděpodobnosti – náhodné výběry: Náhodný stratifikovaný výběr • populace je rozdělena do skupin homogenních vzhledem k nějakému jasnému kritériu a jedinci jsou vybíráni do vzorku náhodně z těchto skupin – technika prostého náhodného výběru (např. při výzkumu studentů určité školy vybírat jedince zvlášť pro každý ročník) • snižuje velikost směrodatné odchylky a interval spolehlivosti z důvodu homogenity skupiny – vzhledem k proměnné, podle které byly stratifikovány – proporcionální – velikost výběru z podskupiny je úměrná velikosti populace této skupiny – neproporcionální – užívá se, pokud je významně odlišný rozptyl v některé podskupině
Typy výběrů -pravděpodobnostní Vícestupňový náhodný výběr • velice drahá, pracná a náročná technika, ale důležitá a nenahraditelná • stupně výběru: – – náhodný výběr reprezentativního souboru okresů náhodný výběr obcí v každém z vybraných okresů ve velkých vybraných obcích ještě výběr menší jednotky (např. volební obvod) výběr jedinců – pokud existuje jejich seznam • takto obdržíme mnohem kompaktnější vzorek, respondenti nejsou rozptýleni po celém teritoriu, ale jsou koncentrováni do zvládnutelného počtu regionů • je-li takový výběr proveden správně, nehrozí žádné závažné zkreslení reprezentativnosti • výhodné tam, kde neexistuje žádný seznam (u většiny zajímavých populací) • pokud v bodě 4 neexistuje seznam, pokračujeme takto: • ve vybraných malých obcích (obvodech) provedeme soupis všech sídelních jednotek (bytů, domků) • vytvoříme náhodný vzorek těchto jednotek • vytvoříme seznam osob zde žijících a opět náhodně vybereme jedince do vzorku
Příklad 2 a – výběr žáků 9. tříd základní školy Výběr žáků pro výzkum hodnotové a profesní orientace populace: žáci 9. ročníku ZŠ v SR (1416 škol, 2892 tříd, cca 67000 žáků) požadavky na výběr: - reprezentativní výběr žáků, rozsah cca 250 tříd (vybírá se vždy celá třída) - na každé škole se má výzkumu účastnit pouze jedna třída - odpovídající zastoupení krajů - reprezentativní zastoupení podle „sídla školy“
Příklad 2 a – výběr žáků 9. tříd základní školy Návrh realizace výběru: Datový soubor: soubor všech tříd 9. ročníku ZŠ v SR • chceme zaručit reprezentativní zastoupení krajů a sídla školy ve výběru výběr bude realizován samostatně v každé podskupině (kraj*sídlo). Kraj a sídlo školy tedy určují tzv. straty (celkem 8*2=16 strat). • v každé stratě vybereme stejné procento tříd (# tříd ve výběru/ # tříd celkem = 250/2892 = 8. 64%). Třídy budou vybírány systematickým výběrem, tj. bude zaručena stejná pravděpodobnost výběru každé třídy. • systematický výběr je založen na pořadí tříd a vhodným uspořádáním lze dosáhnout splnění dalších požadavků. Uspořádáním tříd zaručíme výběr pouze jedné třídy na škole, nebo případně rovnoměrné rozdělení výběru na základě nějaké další zvolené charakteristiky například % dívek v 9. ročníku apod.
Rozsah výběru (velikost vzorku) • Absolutní velikost výběrového souboru je důležitější než relativní velikost (viz vysvětlení další slide) • Čím větší vzorek, tím spolehlivější a reprezentativnější zjištění dostaneme (pokud použijeme vhodný výběr) • S rostoucí velikostí vzorku klesá chyba způsobená výběrem • Je však zapotřebí vždy pravdivě referovat o způsobu výběru vzorku a případných omezeních z toho plynoucích
Výběrová chyba • Zkreslení/odchylka mezi základním souborem a výběrem. • Na základě výběrové chyby lze stanovit interval spolehlivosti, který při námi požadované spolehlivosti udává rozpětí hodnot zahrnujících odhadovaný populační parametr. • Výběrová chyba souvisí se třemi faktory: 1. sampling fraction (poměr mezi velikostí výběru a populace (f=n/N); 2. s 2 - směrodatná odchylka a 3. n - velikost výběru. (Blíže viz text Soukup/Kočvarová v Moodlu) • Pokud je poměr mezi velikostí výběru a populace 1/10 nebo menší, vychází hodnota blízko k 1 a můžeme ji zanedbat. • => Při tvorbě výběru nemusíme zvažovat velikost populace, pokud je minimálně 10 x větší než výběr.
Faktory ovlivňující velikost vzorku (2) • Heterogenita populace ve sledovaném znaku – Čím větší variabilita, tím větší vzorek budeme potřebovat • Typy analýz (statistických), které budeme chtít provádět – Některé stat. metody vyžadují větší vzorky
Výběrová chyba • Zkreslení/odchylka mezi základním souborem a výběrem. • S rostoucí velikostí výběru klesá výběrová chyba.
Vzorce pro stanovení velikosti výběru Vzorec pro odhad velikosti prostého náhodného výběru dle Kalton (1983), blíže viz text Soukup a Kočvarová v moodle s. 521. Ve vzorci nefiguruje velikost cílové populace, ta neovlivňuje velikost výběru (400 jednotek z 10 tisíc tak zajišťuje srovnatelnou přesnost jako z 10 milionů, za předpokladu srovnatelné variability).
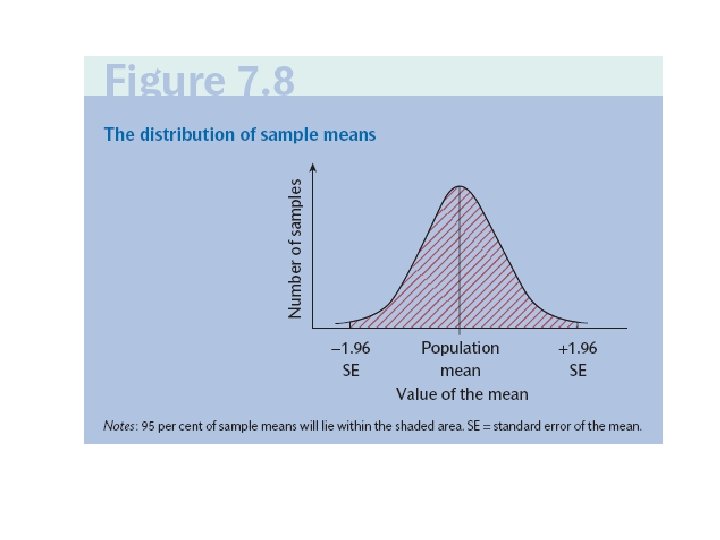
Normální rozdělení – N(0, 1) • Rozdělení pravděpodobnosti relativních četností
Nejčastější typy vah ve výzkumu • designové (stratifikační) - napravují nestejnou pravděpodobnost výběru jednotek. Váhy jsou nepřímo úměrné pravděpodobnosti zahrnutí jednotek, konstruují se již při realizaci výběru. • poststratifikační - částečně napravují nezamýšlenou nevyváženost výběru. Poté, co provedeme šetření zjistíme, že struktura našeho souboru (váženého pomocí designových vah) neodpovídá struktuře celé populace. Snažíme se proto soubor vyvážit podle několika zvolených základních znaků …
Součet vah Nejčastější možnosti, jak určit součet vah: • Velikost populace - dostáváme přímo odhady (úhrny) pro celou populaci, ale statistické testy a intervaly spolehlivosti počítané standardními metodami jsou zkreslené. • Velikost výběru - nejčastěji užívaná možnost, statistické testy a intervaly spolehlivosti počítané standardními metodami vycházejí přesně za předpokladu prostého náhodného výběru. Pozn. : za standardní metody jsou zde považovány metody, které předpokládají prostý náhodný výběr a nezahrnují do výpočtu informaci o komplexním designu – např. nástroje modulu SPSS Base …
Designové váhy • vyvažují nestejnou pravděpodobnost výběru jednotky • jsou úměrné 1/ pravděpodobnost výběru jednotky • př. : V každém kraji je do výzkumu vybráno 30 základních škol. Protože počet škol v krajích se liší, pravděpodobnost výběru školy je 30/počet škol v kraji váha je úměrná počtu škol v kraji. Pozn. : Váhu lze interpretovat jako vyjádření toho, kolik podobných jednotek případ reprezentuje…
Poststratifikační váhy • Napravují nevyváženost výběru, zjištěnou dodatečně po realizaci šetření. • Výpočet je založen na stejné úvaze jako u designových vah, ale praxe je složitější: provázanost kriterií by si přímočarém postupu vynutila příliš mnoho skupin a nepoužitelně velký rozptyl vah … • I dobré váhy odstraní jen část chyby vnesené nekvalitním designem.
Poststratifikační váhy • Problém: soubor se po sběru dat a stanovení designových vah neshoduje s kvótami (ČSÚ) – Pozn. : Nutnost vážení lze ověřit testem chí-kvadrát • Pokud je chyba jen u jednoho až tří znaků, je obvykle možné použít obdobný vzorec jako pro designové váhy (musíme aplikovat také na průniky kategorií) • Pokud je dimenzionalita větší, je situace složitější …
Vážení dat: Designové váhy • Smysl: Vyrovnání nerovnoměrností výběru • Váhy dané designem výběru (design weights) – Váha nepřímo úměrná pravděpodobnosti výběru (např. tedy úměrná „velikosti“ domácnosti, pokud vybíráme jednoho respondenta z každé navštívené domácnosti: pravděpodobnost výběru respondenta je zde totiž tím vyšší, čím méně pro výběr přijatelných lidí zde žije) – U složitějších výběrových designů tyto pravděpodobnosti musíme napřed propočítat (obvykle jde o násobení pr. sti výběru v jednotlivých fázích výběru)
Vážení: Poststratifikační váhy • Poststratifikační vyrovnání s distribucí populace – Kompenzuje zejména non-response apod. – Nelze čekat zázraky, nejlepším případě vyrovná asi 50 % chyby výběrového designu a provedení. – V nejhorším případě dokonce může data ještě více poškodit • Totiž jsou-li poruchy dat a non-response korelovány s proměnnými, podle kterých vážíme • Postup: – váha = očekávaný podíl / zjištěný podíl – Např. máme-li 25 % žen a v populaci jich má být 50 %, bude váha 50/25 = 2, 0 (strata jsou dána pohlavím) • Je-li strat mnoho, povede to však k nepříjemným nerovnoměrnostem vah – viz dále