Hierarchical Clustering Produces a set of nested clusters






















 space since it uses the proximity")
 • Start with a tree")






















![Pattern Preservation? • What happens to hyperclique patterns [sets of objects supporting hyperclique patterns]](https://slidetodoc.com/presentation_image_h2/4317061bd4707a2306d689f8990ba168/image-48.jpg "Pattern Preservation? • What happens to hyperclique patterns [sets of objects supporting hyperclique patterns]")

- Slides: 49
Hierarchical Clustering • Produces a set of nested clusters organized as a hierarchical tree • Can be visualized as a dendrogram – A tree like diagram that records the sequences of merges or splits
Strengths of Hierarchical Clustering • Do not have to assume any particular number of clusters – ‘cut’ the dendogram at the proper level • They may correspond to meaningful taxonomies – Example in biological sciences e. g. , • animal kingdom, • phylogeny reconstruction, • …
Hierarchical Clustering • Two main types of hierarchical clustering – Agglomerative: • Start with the points as individual clusters • At each step, merge the closest pair of clusters until only one cluster (or k clusters) left – Divisive: • Start with one, all inclusive cluster • At each step, split a cluster until each cluster contains a point (or there are k clusters) • Traditional hierarchical algorithms use a similarity or distance matrix – Merge or split one cluster at a time
Agglomerative Clustering Algorithm Compute the proximity matrix Let each data point be a cluster Repeat Merge the two closest clusters Update the proximity matrix Until only a single cluster remains • Key operation is the computation of the proximity of two clusters – Different approaches to defining the distance between clusters distinguish the different algorithms
Starting Situation • Start with clusters of individual points and a proximity matrix p 1 p 2 p 3 p 4 p 5. . . Proximity Matrix . . .
Intermediate Situation • After some merging steps, we have some clusters C 1 C 2 C 3 C 4 C 5 Proximity Matrix C 1 C 2 C 5
Intermediate Situation • We want to merge the two closest clusters (C 2 and C 5) and update the proximity matrix. C 1 C 2 C 3 C 4 C 5 Proximity Matrix C 1 C 2 C 5
After Merging • The question is “How do we update the proximity matrix? ” C 1 C 2 U C 5 C 3 C 4 ? ? ? C 3 ? C 4 ? Proximity Matrix C 1 C 2 U C 5
How to Define Inter Cluster Similarity p 1 Similarity? p 2 p 3 p 4 p 5 p 1 p 2 p 3 p 4 • MIN • MAX • Group Average p 5 . . . Proximity Matrix . . .
How to Define Inter Cluster Similarity p 1 p 2 p 3 p 4 p 5 p 1 p 2 p 3 p 4 • MIN • MAX • Group Average p 5 . . . Proximity Matrix . . .
How to Define Inter Cluster Similarity p 1 p 2 p 3 p 4 p 5 p 1 p 2 p 3 p 4 • MIN • MAX • Group Average p 5 . . . Proximity Matrix . . .
How to Define Inter Cluster Similarity p 1 p 2 p 3 p 4 p 5 p 1 p 2 p 3 p 4 • MIN • MAX • Group Average p 5 . . . Proximity Matrix . . .
Cluster Similarity: MIN • Similarity of two clusters is based on the two most similar (closest) points in the different clusters – Determined by one pair of points
Hierarchical Clustering: MIN 1 3 5 2 1 2 3 4 5 6 4 Nested Clusters Dendrogram
Strength of MIN Original Points Can handle non-globular shapes Two Clusters
Limitations of MIN Original Points Four clusters Sensitive to noise and outliers Three clusters: The yellow points got wrongly merged with the red ones, as opposed to the green one.
Cluster Similarity: MAX • Similarity of two clusters is based on the two least similar (most distant) points in the different clusters – Determined by all pairs of points in the two clusters
Hierarchical Clustering: MAX 4 1 2 5 5 2 3 3 6 1 4 Nested Clusters Dendrogram
Strengths of MAX Original Points Four clusters Three clusters: The yellow points get now merged with the green one. Less susceptible respect to noise and outliers
Limitations of MAX Original Points Tends to break large clusters Two Clusters
Cluster Similarity: Group Average • Proximity of two clusters is the average of pairwise proximity between points in the two clusters.
Hierarchical Clustering: Group Average 5 4 1 2 5 2 3 6 1 4 3 Nested Clusters Dendrogram
Hierarchical Clustering: Time and Space • O(N 2) space since it uses the proximity matrix. – N is the number of points. • O(N 3) time in many cases – There are N steps and at each step the size, N 2, proximity matrix must be updated and searched – Complexity can be reduced to O(N 2 log(N) ) time for some approaches
MST: Divisive Hierarchical Clustering Build MST (Minimum Spanning Tree) • Start with a tree that consists of any point • In successive steps, look for the closest pair of points (p, q) such that one point (p) is in the current tree but the other (q) is not • Add q to the tree and put an edge between p and q
MST: Divisive Hierarchical Clustering • Use MST for constructing hierarchy of clusters
DBSCAN is a density based algorithm. Locates regions of high density that are separated from one another by regions of low density. • Density = number of points within a specified radius (Eps) • A point is a core point if it has more than a specified number of points (Min. Pts) within Eps – These are points that are at the interior of a cluster • A border point has fewer than Min. Pts within Eps, but is in the neighborhood of a core point • A noise point is any point that is neither a core point nor a border point.
DBSCAN: Core, Border, and Noise Points
DBSCAN Algorithm • Any two core points that are close enough within a distance Eps of one another are put in the same cluster. • Likewise, any border point that is close enough to a core point is put in the same cluster as the core point. • Ties may need to be resolved if a border point is close to core points from different clusters. • Noise points are discarded.
DBSCAN: Core, Border and Noise Points Original Points Point types: core, border and noise Eps = 10, Min. Pts = 4
When DBSCAN Works Well Original Points Clusters • Resistant to Noise • Can handle clusters of different shapes and sizes
When DBSCAN Does NOT Work Well Why DBSCAN doesn’t work well here?
DBSCAN: Determining EPS and Min. Pts • • • Look at the behavior of the distance from a point to its k-th nearest neighbor, called the k dist. For points that belong to some cluster, the value of k distwill be small [if k is not larger than the cluster size]. However, for points that are not in a cluster, such as noise points, the k distwill be relatively large. So, if we compute the k distfor all the data points for some k, sort them in increasing order, and then plot the sorted values, we expect to see a sharp change at the value of k distthat corresponds to a suitable value of Eps. If we select this distance as the Eps parameter and take the value of k as the Min. Pts parameter, then points for which k dist is less than Eps will be labeled as core points, while other points will be labeled as noise or border points.
DBSCAN: Determining EPS and Min. Pts • Eps determined in this way depends on k, but does not change dramatically as k changes. • If k is too small ? then even a small number of closely spaced points that are noise or outliers will be incorrectly labeled as clusters. • If k is too large ? then small clusters (of size less than k) are likely to be labeled as noise. • Original DBSCAN used k = 4, which appears to be a reasonable value for most two dimensional data sets.
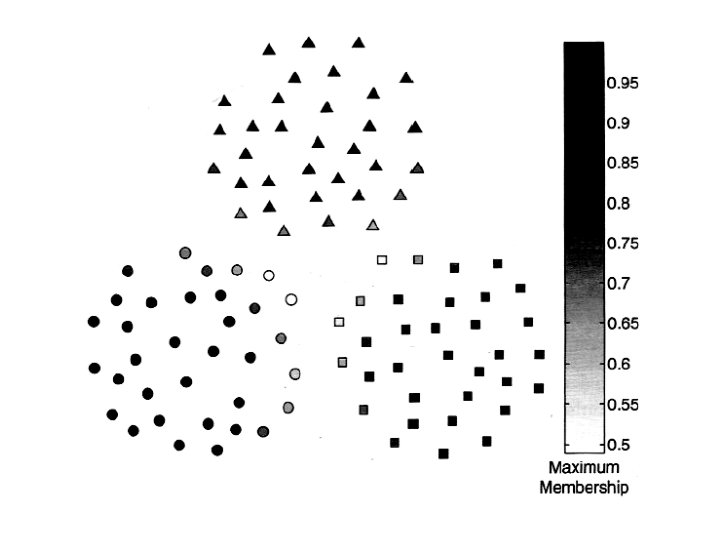
Fuzzy Clustering • Consider an object that lies near the boundary of two clusters, but is slightly closer to one of them. – In many such cases, it might be more appropriate to assign a weight wij to each object xi and each cluster Cj that indicates the degree to which the object belongs to the cluster Cj. • Fuzzy clustering is based on fuzzy set theory. • Fuzzy set theory allows an object to belong to a set with a degree of membership between 0 and 1, while fuzzy logic allows a statement to be true with a degree of certainty between 0 and 1.
Example • Consider the following example of fuzzy logic. The degree of truth of the statement "It is cloudy" can be defined to be the percentage of cloud cover in the sky, • E. g. if the sky is 50% covered by clouds, then we would assign "It is cloudy" a degree of truth of 0. 5. • If we have two sets, "cloudy days" and "non cloudy days, " then we can similarly assign each day a degree of membership in the two sets. – Thus, if a day were 25% cloudy, it would have a 25% degree of membership in "cloudy days" and a 75% degree of membership in "non cloudy days. "
Fuzzy Clusters • • Set of data points X = {xl, …, xm}, where each point, is an n dimensional point. Fuzzy collection C 1, C 2, . . . , Ck The membership weights (degrees), wij, are assigned values between 0 and 1 for each point, xi, and each cluster, Cj. We also impose the following reasonable conditions on the clusters: 1. All the weights for a given point, xi, add up to 1. 2. Each cluster, Cj, contains, with non zero weight, at least one point, but does not contain, with a weight of one, all of the points.
Fuzzy c means algorithm Select an initial fuzzy pseudo partition, i. e. , randomly assign values to all the wij subject to the constraint that the weights for any object must sum up to 1. repeat Compute the centroid of each cluster using the fuzzy pseudo partition. Recompute the fuzzy pseudo partition, i. e. , the wij. until The centroids don't change.
Computing centroids • Similar to the traditional definition except that all points are considered • Any point can belong to any cluster, at least somewhat. • The contribution of each point to the centroid is weighted by its membership degree. • What happens in the case of traditional crisp sets? • All wij are either 0 or 1, this definition reduces to the traditional definition of a centroid. • As p gets larger, the partition becomes fuzzier. • p=2 good value.
Updating the Fuzzy Pseudo partition • This step involves updating the weights wij associated with the ith point and jth cluster. • Intuitively, the weight wij [which indicates the degree of membership of point xi in cluster Cj] should be relatively high if xi is close to centroid cj [if dist(xi, cj) is low] and relatively low if xi is far from centroid cj [if dist(xi, cj) is high]. • If wij = 1/dist(xi, cj) [which is the numerator of equation] then this will indeed be the case. • However, the membership weights for a point will not sum to one unless they are normalized; i. e. , divided by the sum of all the weights as we do in the equation.
HICAP: Hierarchical Clustering with Pattern Preservation Xiong, Steinbach, Tan, and Kumar 2003
Pattern Preserving Clustering: Motivation • In many domains, there are groups of objects that are involved in strong patterns that are key for understanding the domain. – In text mining, collections of words that form a topic. – In genomics, sequences of nucleotides that form a functional unit. • We want to design a clustering method that preserves these patterns, i. e. that puts the objects supporting these patterns in the same cluster. • Otherwise, the resulting clusters will be harder to understand interpret. – The value of a data analysis is greatly diminished for end
Review: Cross support patterns • They are patterns that relate a high frequency itemsuch as milk to a low frequency itemsuch as caviar. • Likely to be spurious because their correlations tend to be weak. – E. g. confidence of {caviar} {milk} is likely to be high, but still the pattern is spurious, since there isn’t probably any correlation between caviar and milk. • Observation: On the other hand, the confidence of {milk} {caviar} is very low. • Cross support patterns can be detected and eliminated by examining the lowest confidence rule that can be extracted from a given itemset. – Such confidence should be above certain level for the pattern to not be cross support one.
Review: Finding lowest confidence • Recall the anti monotone property of confidence: conf( {i 1 , i 2} {i 3, i 4, …, ik} ) conf( {i 1 , i 2 , i 3} {i 4, …, ik} ) • This property suggests that confidence never increases as we shift more items from the left to the right hand side of an association rule. • Hence, the lowest confidence rule that can be extracted from a frequent itemset contains only one item on its left hand side.
Review: Finding lowest confidence • Given a frequent itemset {i 1, i 2, i 3, i 4, …, ik}, the rule {ij} {i 1 , i 2 , i 3, ij-1, ij+1, i 4, …, ik} has the lowest confidence if s(ij) = max {s(i 1), s(i 2), …, s(ik)} • This follows directly from the definition of confidence as the ratio between the rule's support and the support of the rule antecedent.
Review: Finding lowest confidence • Summarizing, the lowest confidence attainable from a frequent itemset {i 1, i 2, i 3, i 4, …, ik}, is • This is also known as the h confidence measure or all confidence measure. • Cross support patterns can be eliminated by ensuring that the h confidencevalues for the patterns exceed some user specified threshold hc. • h confidence is anti monotone, i. e. , h confidence({i 1, i 2, …, ik}) h confidence({i 1, i 2, …, ik+1 }) and thus can be incorporated directly into the mining algorithm.
Hyperclique Patterns • An itemset P = {i 1, i 2, …, im} is a hyperclique pattern if h confidence(P) > hc, where hc is a user specified minimum h confidence threshold. Some hyperclique patterns identified from words of a (news) document collection.
Pattern Preservation? • What happens to hyperclique patterns [sets of objects supporting hyperclique patterns] when data is clustered by standard clustering techniques, e. g. , how are they distributed among clusters? – Experimentally found that hypercliques are mostly destroyed by standard clustering techniques. • Reasons – Clustering algorithms have no built in knowledge of these patterns and have goals that may be in conflict with preserving patterns, • e. g. , minimize distance of points from their closest cluster centroid. – Many clustering techniques are not overlapping, i. e. clusters cannot contain the same object (for hierarchical clustering, clusters on the same level cannot contain the same objects). • But, patterns are typically overlapping.
HICAP Algorithm • Find maximal hyperclique patterns – Non-maximal hypercliques will tend to be absorbed by their corresponding maximal hyperclique pattern and not affect the clustering process. – Thus, using all hyperclique patterns would cause a great deal of overhead with little if any gain. • Perform a group average hierarchical clustering – The starting clusters are hyperclique patterns and the points not covered by hyperclique patterns. – Except for the starting point, the clustering algorithm is the same as the group average approach. – Since hypercliques are overlapping, resulting clustering may also be overlapping.