Exam Data Mining Preparation Exam January 4 2019




 of an XOR")

 § R 2 = 1−SSres/SStot § SSres = Σ(yi−fi)2 §")
")
")
")
")
")
")
")
")


 and a")
 and")







- Slides: 27
Exam Data Mining Preparation
Exam § January 4, 2019 § 14: 00 – 17: 00 § rooms Gorl 01 and Gorl 02
Material § Slides of lectures § see http: //datamining. liacs. nl/Da. Mi/ § Practicals § Handouts Association Analysis (up to 6. 4 (incl. )) § Paper Maximally Informative k-Itemsets § Book § Weka/Cortana § (example exam and model answers)
Exam § Mixture of § topics § level § knowledge/application § Emphasis on big picture and understanding § technical details mostly not essential § apply standard algorithms on simple example data
Short Questions § Give an example (e. g. with some data) of an XOR problem with four binary attributes, of which one is the target § Give two advantages of hierarchical clustering, compared to a more standard algorithm such as k-means § Explain the difference between 10 -fold cross validation and leave-one-out. In what circumstances would you choose for the second alternative?
Regression § Both Regression Trees and Model Trees can be used for regression. Explain the major difference between these two methods § Explain why an RT is often bigger than an MT on the same data § The measure R 2 is often used to asses the quality of a regression model. Give the definition of this measure, and explain why this definition makes sense. If helpful, use a diagram to explain the intuition behind this definition
R 2 (R squared) § R 2 = 1−SSres/SStot § SSres = Σ(yi−fi)2 § SStot = Σ(yi−y)2 predicted difference between actual and horizontal line
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. § Give the cross table (contingency table) of this subgroup. Put the subgroup S and its complement S’ on the left, and the values of the target (T and F) at the top. Also add the totals of the columns and rows at the bottom and right of the table.
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target T subgroup F S S’ 1000
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target subgroup T F 100 900 S S’ 1000
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target T subgroup F S 200 S’ 800 100 900 1000
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target T subgroup S F 90 200 S’ 800 100 900 1000
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target T subgroup F S 90 200 S’ 10 800 100 900 1000
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. target subgroup T F S 90 110 200 S’ 10 790 800 100 900 1000
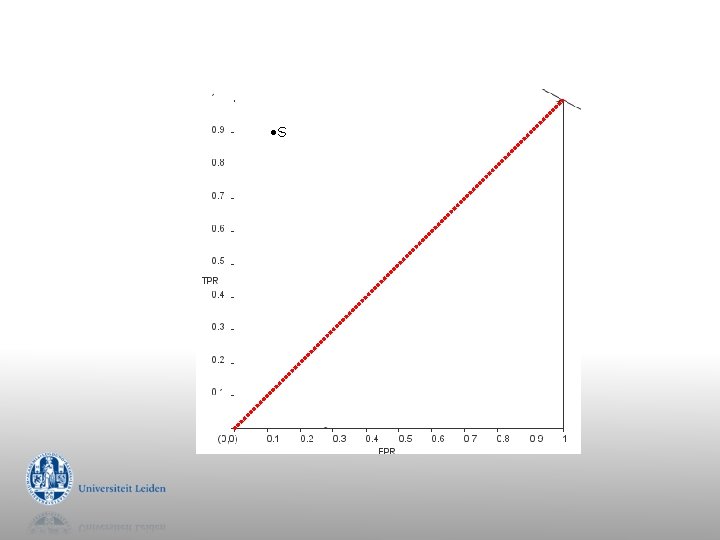
Subgroup Discovery Assume a dataset with multiple attributes, of which one is the (binary) target. The dataset contains 1000 examples, of which 100 are positive. Let’s assume that we have evaluated a subgroup S on the data, and it turns out that it covers 20% of the dataset. Additionally, 90 positive cases turn out to be covered by S. § Draw the ROC space for this dataset, and indicate the location of S.
Subgroup Discovery § Give two examples of a quality measure for binary targets, and draw the isometrics of the measures. Additionally, indicate which isometrics represent positive values. Information Gain
Other Measures Precision Correlation coefficient Gini index Foil gain
Decision Trees Assume a dataset of two numeric attributes (x and y) and a binary target. The 10, 000 examples are uniformly distributed over the area [0. . 10]x[0. . 10]. An example is positive if it is situated inside a circle with radius 3 and center point (3, 3). Else, it is negative. § Give an example of a decision tree of depth 2 (so at most two splits per path from the root to the leaf), as it probably will be produced by an algorithm based on information gain.
Vraag: Decision Tree Assume a dataset of two numeric attributes (x and y) and a binary target. The 10, 000 examples are uniformly distributed over the area [0. . 10]x[0. . 10]. An example is positive if it is situated inside a circle with radius 3 and center point (3, 3). Else, it is negative. § Give a suggestion for how this dataset can be modelled more easily and precisely with a decision tree.
Entropy The table below contains 4 binary attributes X T T F F Y T T T F F F Z T T F F T F § Compute the entropy of each attribute § Compute the information gain from Z to T § Give an upper bound on the joint entropy of ZT and argue why this is an upper bound § Compute the joint entropy of ZT
FP Mining transactions 1 2 3 4 5 Milk Bread Diapers Cookies Milk Cookies § Draw the itemset lattice and indicate: § (M) Maximal, (C) Closed, (N) frequent but not closed/maximal, (I) infrequent. Assume minsup = 0. 3 § Association rules: Find a pair of itemsets a, b for which holds:
FP Mining transactions 1 2 3 4 5 Milk Bread Items = {Bread, Cookies, Diapers, Milk} Diapers Cookies N C B M B, C Minsup = 0. 3 support count ≥ 2 Milk Cookies I B, D N C C D I B, M N C, D I I B, C, D B, C, M M C C, M I B, D, M I B, C, D, M C D, M M C, D, M
FP Mining transactions 1 2 3 4 5 Milk Bread Items = {Bread, Cookies, Diapers, Milk} Diapers Cookies Milk Cookies σ(a) = σ(b) OK: {Milk} {Cookies} Not OK: {Bread} {Milk, Cookies}
Clustering object 1 2 3 4 X 1 0 7 4 3 x 2 0 8 8 0 n Cluster the values by means of the k-Means algorithm n Initialise with random cluster centers (0, 6) en (7, 2) n Describe the iterations until k-Means converges
k-Means 3 object 1 2 3 4 X 1 0 7 4 3 x 2 0 8 8 0 2 c 1 c 2 1 4 Cluster using C 1=(0, 6), C 2=(7, 2) n Recompute cluster centers n Cluster 1: {1, 3} n C 1’: ((0+4)/2, (0+8)/2)=(2, 4) n Cluster 2: {2, 4} n C 2’: ((3+7)/2, (0+8)/2)= (5, 4) n E. g. point 2: n d(2, c 1)=sqrt(72+22)=sqrt(53) n d(2, c 2)=sqrt(0+62)=sqrt(36) -> c 2
k-Means 3 2 c 1’ c 2’ 1 4 Cluster using c 1’ (2, 4) and c 2’ (5, 4) n Recompute cluster centers n C 1’={1, 4} n C 1’: ((0+3)/2, (0+0)/2)=(1. 5, 0) n C 2’={2, 3} n C 2’: ((4+7)/2, (8+8)/2)= (5. 5, 8) n E. g. , point 4: n d(4, c 1’)=sqrt(12+42)=sqrt(17) -> c 1’ n d(4, c 2’)=sqrt(22+42)=sqrt(20) n Clusters don’t change anymore n Converged, stop