Unified Parallel C Kathy Yelick EECS U C













 • Iterations are independent • Each thread gets a bunch")



")
![UPC Matrix Multiplication Code /* mat_mult_1. c */ #include <upc_relaxed. h> shared [N*P /THREADS]](https://slidetodoc.com/presentation_image_h2/46e5bc0b9ba39ac8d2e1e4e969a67dcb/image-21.jpg "UPC Matrix Multiplication Code /* mat_mult_1. c */ #include <upc_relaxed. h> shared [N*P /THREADS]")











 – Based on Open 64 compiler for")
 -> programmability •")




 Extends applicability of PHIPAC Incorporated in Matlab")


 floating point registers –")
- Slides: 42
Unified Parallel C Kathy Yelick EECS, U. C. Berkeley and NERSC/LBNL NERSC Team: Dan Bonachea, Jason Duell, Paul Hargrove, Parry Husbands, Costin Iancu, Mike Welcome, Christian Bell Some slides from: Tarek El Ghazawi and Bill Carlson
Outline • Motivation for a new class of languages – Programming models – Architectural trends • Overview of Unified Parallel C (UPC) – Programmability advantage – Performance opportunity • Status – Next step • Related projects
Programming Model 1: Shared Memory • Program is a collection of threads of control. – Many languages allow threads to be created dynamically, • Each thread has a set of private variables, e. g. local variables on the stack. • Collectively with a set of shared variables, e. g. , static variables, shared common blocks, global heap. – Threads communicate implicitly by writing/reading shared variables. – Threads coordinate using synchronization operations on shared variables Shared y =. . x. . . x =. . . Private P 0 P 1 . . . Pn
Programming Model 2: Message Passing • Program consists of a collection of named processes. – Usually fixed at program startup time – Thread of control plus local address space -- NO shared data. – Logically shared data is partitioned over local processes. • Processes communicate by explicit send/receive pairs – Coordination is implicit in every communication event. – MPI is the most common example send P 0, X recv Pn, Y Y P 0 X P 1 . . . Pn
Advantages/Disadvantages of Each Model • Shared memory 1. Programming is easier • Can build large shared data structures – Machines don’t scale • SMPs typically < 16 processors (Sun, DEC, Intel, IBM) • Distributed shared memory < 128 (SGI) – Performance is hard to predict and control • Message passing + Machines easier to build from commodity parts – Can scale (given sufficient network) – Programming is harder • Distributed data structures only in the programmers mind • Tedious packing/unpacking of irregular data structures
Global Address Space Programming • Intermediate point between message passing and shared memory • Program consists of a collection of processes. – Fixed at program startup time, like MPI • Local and shared data, as in shared memory model – But, shared data is partitioned over local processes – Remote data stays remote on distributed memory machines – Processes communicate by reads/writes to shared variables • Examples are UPC, Titanium, CAF, Split-C • Note: These are not data-parallel languages – heroic compilers not required
GAS Languages on Clusters of SMPs • SMPs are the fastest commodity machine, so used as a node in large-scale clusters • Common names: – CLUMP = Cluster of SMPs – Hierarchical machines, constellations • Most modern machines look like this: – Millennium, IBM SPs, (not the t 3 e). . . • What is an appropriate programming model? – Use message passing throughout • Unnecessary packing/unpacking overhead – Hybrid models • Write 2 parallel programs (MPI + Open. MP or Threads) – Global address space • Only adds test (on/off node) before local read/write
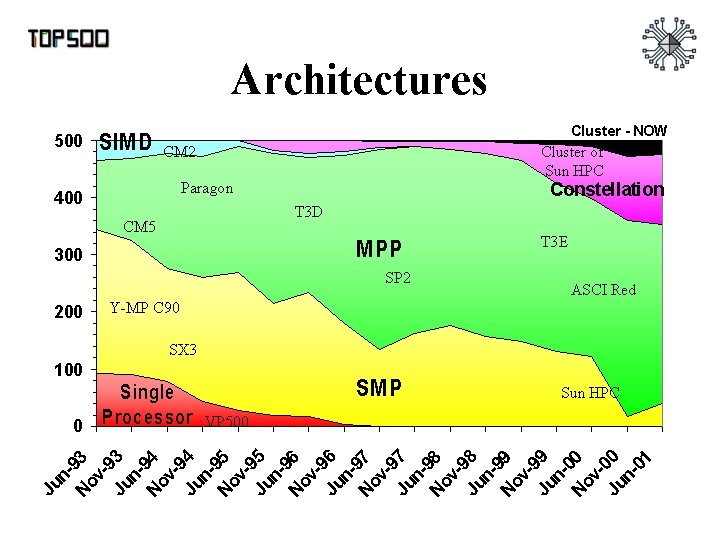
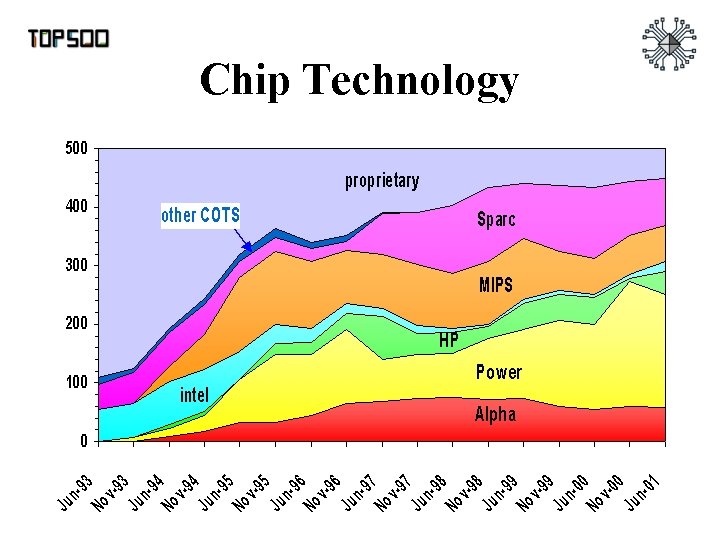
Top 500 Supercomputers • Listing of the 500 most powerful computers in the world - Yardstick: Rmax from LINPACK MPP benchmark Ax=b, dense problem Rate performance Size - Dense LU Factorization (dominated by matrix multiply) • Updated twice a year SC‘xy in the States in November – Meeting in Mannheim, Germany in June – All data (and slides) available from www. top 500. org – Also measures N-1/2 (size required to get ½ speed)
Outline • Motivation for a new class of languages – Programming models – Architectural trends • Overview of Unified Parallel C (UPC) – Programmability advantage – Performance opportunity • Status – Next step • Related projects
Parallelism Model in UPC • UPC uses an SPMD model of parallelism – A set if THREADS threads working independently • Two compilation models – THREADS may be fixed at compile time or – Dynamically set at program startup time • MYTHREAD specifies thread index (0. . THREADS-1) • Basic synchronization mechanisms – Barriers (normal and split-phase), locks • What UPC does not do automatically: – Determine data layout – Load balance – move computations – Caching – move data • These are intentionally left to the programmer
Shared and Private Variables in UPC • A shared variable has one instance, shared by all threads. – Affinity to thread 0 by default (allocated in processor 0’s memory) • A private variable has an instance per thread • Example: int x; // private copy for each processor shared int y; // one copy on P 0, shared by all others x = 0; y = 0; x += 1; y += 1; • After executing this code – x will be 1 in all threads; y will be between 1 and THREADS • Shared scalar variable are somewhat rare because: – cannot be automatic (declared in a function) (Why not? )
UPC Pointers Global address space • Pointers may point to shared or private variables • Same syntax for use, just add qualifier shared int *sp; int *lp; • sp is a pointer to an integer residing in the shared memory space. • sp is called a shared pointer (somewhat sloppy). x: 3 sp: lp: Shared sp: lp: Private
Shared Arrays in UPV • Shared array elements are spread across the threads shared int x[THREADS] /*One element per thread */ shared int y[3][THREADS] /* 3 elements per thread */ shared int z[3*THREADS] /* 3 elements per thread, cyclic */ • In the pictures below – Assume THREADS = 4 – Elements with affinity to processor 0 are red x y blocked z cyclic Of course, this is really a 2 D array
Work Sharing with upc_forall() • Iterations are independent • Each thread gets a bunch of iterations • Simple C-like syntax and semantics upc_forall(init; test; loop; affinity) statement; • Affinity field to distribute the work – Round robin – Chunks of iterations • Semantics are undefined if there are dependencies between iterations – Programmer has indicated iterations are independent
Vector Addition with upc_forall • The loop in vadd is common, so there is upc_forall: • 4 th argument is int expression that gives “affinity” • Iteration executes when: • affinity%THREADS is MYTHREAD /* vadd. c */ #include <upc_relaxed. h> #define N 100*THREADS shared int v 1[N], v 2[N], sum[N]; void main() { int i; upc_forall(i=0; i<N; i++; i) sum[i]=v 1[i]+v 2[i]; }
Layouts in General • All non-array objects have affinity with thread zero. • Array layouts are controlled by layout specifiers. layout_specifier: : null layout_specifier [ integer_expression ] • The affinity of an array element is defined in terms of the • block size, a compile-time constant, and THREADS a runtime constant. • Element i has affinity with thread ( i / block_size) % PROCS.
2 D Array Layouts in UPC • Array a 1 has a row layout and array a 2 has a block row layout. shared [m] int a 1 [n][m]; shared [k*m] int a 2 [n][m]; • If (k + m) % THREADS = = 0 them a 3 has a row layout shared int a 3 [n][m+k]; • To get more general HPF and Sca. LAPACK style 2 D blocked layouts, one needs to add dimensions. • Assume r*c = THREADS; shared [b 1][b 2] int a 5 [m][n][r][c][b 1][b 2]; • or equivalently shared [b 1*b 2] int a 5 [m][n][r][c][b 1][b 2];
Domain Decomposition for UPC • Exploits locality in matrix multiplication • A (N P) is decomposed row-wise into blocks of size (N P) / THREADS as shown below: • B(P M) is decomposed column wise into M/ THREADS blocks as shown below: Thread 0 P 0. . (N*P / THREADS) -1 (N*P / THREADS). . (2*N*P / THREADS)-1 Thread THREADS-1 M Thread 0 Thread 1 N P ((THREADS-1) N*P) / THREADS. . (THREADS*N*P / THREADS)-1 Thread THREADS-1 • Note: N and M are assumed to be multiples of THREADS Columns 0: (M/THREADS)-1 Columns ((THREAD-1) M)/THREADS: (M-1)
UPC Matrix Multiplication Code /* mat_mult_1. c */ #include <upc_relaxed. h> shared [N*P /THREADS] int a[N][P], c[N][M]; // a and c are row-wise blocked shared matrices shared[M/THREADS] int b[P][M]; //column-wise blocking void main (void) { int i, j , l; // private variables upc_forall(i = 0 ; i<N ; i++; &c[i][0]) { for (j=0 ; j<M ; j++) { c[i][j] = 0; for (l= 0 ; l P ; l++) c[i][j] += a[i][l]*b[l][j]; } } }
Notes on the Matrix Multiplication Example • The UPC code for the matrix multiplication is almost the same size as the sequential code • Shared variable declarations include the keyword shared • Making a private copy of matrix B in each thread might result in better performance since many remote memory operations can be avoided • Can be done with the help of upc_memget
Overlapping Communication in UPC • Programs with fine-grained communication require overlap for performance • UPC compiler does this automatically for “relaxed” accesses. – Acesses may be designated as strict, relaxed, or unqualified (the default). – There are several ways of designating the ordering type. • A type qualifier, strict or relaxed can be used to affect all variables of that type. • Labels strict or relaxed can be used to control the accesses within a statement. strict : { x = y ; z = y+1; } • A strict or relaxed cast can be used to override the current label or type qualifier.
Performance of UPC • Reason why UPC may be slower than MPI – Shared array indexing is expensive – Small messages encouraged by model • Reasons why UPC may be faster than MPI – MPI encourages synchrony – Buffering required for many MPI calls • Remote read/write of a single word may require very little overhead • Cray t 3 e, Quadrics interconnect (next version) • Assuming overlapped communication, the real issues is overhead: how much time does it take to issue a remote read/write?
UPC versus MPI for Edge detection a. Execution time b. Scalability • Performance from Cray T 3 E • Benchmark developed by El Ghazawi’s group at GWU
UPC versus MPI for Matrix Multiplication a. Execution time b. Scalability • Performance from Cray T 3 E • Benchmark developed by El Ghazawi’s group at GWU
UPC vs. MPI for Sparse Matrix-Vector Multiply • Short term goal: – Evaluate language and compilers using small applications • Show advantage of t 3 e network model and UPC • Performance on Compaq machine worse: - Serial code - Communication performance - New compiler just released • Longer term, identify large application
Particle/Grid Methods in UPC ? • Experience so far in a related language – Titanium, Java-based GAS language – Immersed boundary method • Most time in communication between mesh and particles • Currently uses bulk communication • May benefit from SPMV trick
EM 3 D Performance in Split-C Language on CM-5 Maxwells Equations on an Unstructured 3 D Mesh: Explicit Method Irregular Bipartite Graph of varying degree (about 20) with weighted edges v 1 v 2 w 1 w 2 H E B D Basic operation is to subtract weighted sum of neighboring values for all E nodes for all H nodes
Split-C: Performance Tuning on the CM 5 • Tuning affects application performance
Outline • Motivation for a new class of languages – Programming models – Architectural trends • Overview of Unified Parallel C (UPC) – Programmability advantage – Performance opportunity • Status – Next step • Related projects
UPC Implementation Effort • UPC efforts elsewhere – – – IDA: t 3 e implementation based on old gcc GMU (documentation) and UMC (benchmarking) Compaq (Alpha cluster and C+MPI compiler (with MTU)) Cray, Sun, and HP (implementations) Intrepid (SGI compiler and t 3 e compiler) • UPC Book: – T. El-Ghazawi, B. Carlson, T. Sterling, K. Yelick • Three components of NERSC effort 1) Compilers (SP and PC clusters) + optimization (DOE) 2) Runtime systems for multiple compilers (DOE + NSA) 3) Applications and benchmarks (DOE)
Compiler Status • NERSC compiler (Costin Iancu) – Based on Open 64 compiler for C – Parses and type-checks UPC – Code generation for SMPs underway • Generate C on most machines, possibly IA 64 later – Investigating optimization opportunities • Focus of this compiler is high level optimizations • Intrepid compiler – Based on gcc (3. x) – Will target our runtime layer on most machines – Initial focus is t 3 e, then Pentium clusters
Runtime System • Characterizing network performance – Low latency (low overhead) -> programmability • Optimization depend on network characteristics – T 3 e was ideal – Quadrics reports very low overhead coming – Difficult to access low level SP and Myrinet
Next Step • Undertake larger application effort • What type of application? – Challenging to write in MPI (e. g. , sparse direct solvers) – Irregular communication (e. g. , PIC) – Well-understood algorithm
Outline • Motivation for a new class of languages – Programming models – Architectural trends • Overview of Unified Parallel C (UPC) – Programmability advantage – Performance opportunity • Status – Next step • Related projects
3 Related Projects on Campus • Titanium – High performance Java dialect – Collaboration with Phil Colella and Charlie Peskin • Be. BOP: Berkeley Benchmarking and Optimization – Self-tuning numerical kernels – Sparse matrix operations • Pyramid mesh generator (Jonathan Shewchuk)
Locality and Parallelism Conventional Storage Proc Hierarchy Cache L 2 Cache Proc Cache L 2 Cache L 3 Cache Memory • Large memories are slow, fast memories are small. • Storage hierarchies are large and fast on average. • Parallel processors, collectively, have large, fast memories -- the slow accesses to “remote” data we call “communication”. • Algorithm should do most work on local data. potential interconnects L 3 Cache
Tuning pays off – ATLAS (Dongarra, Whaley) Extends applicability of PHIPAC Incorporated in Matlab (with rest of LAPACK)
Speedups on SPMV from Sparsity on Sun Ultra 1/170 – 1 RHS
Speedups on SPMV from Sparsity on Sun Ultra 1/170 – 9 RHS
Future Work • Exploit Itanium Architecture – 128 (82 -bit) floating point registers – – – • 9 HW formats: 24/8(v), 24/15, 24/17, 53/11, 53/15, 53/17, 64/15, 64/17 • Many few load/store instructions fused multiply-add instruction predicated instructions rotating registers for software pipelining prefetch instructions three levels of cache • Tune current and wider set of kernels – Improve heuristics, eg choice of r x c • Incorporate into – SUGAR – Information Retrieval