Lexical Trigger and Latent Semantic Analysis for CrossLingual



 • For language modeling, if sufficiently good MT is available between")
 • Cross-Lingual Lexical Triggers: several content-bearing English words will signal the")




 and PT(e|c) – Created out of")

 • A pair of words (a, b) is considered")
 • Average mutual information, which measures how much knowing")
")
 and PTrig(e|c) in lieu of")
 Interpolated model:")

 • • Then SVD is performed on W, and some R")




 • Monolingual Corpora: – XINHUA: 13 million words.")

 • Baseline ASR Performance of Cross-Lingual LMs P-value are based")
 • • • Likelihood-Based Story-Specific Selection of Interpolation Weight and")
 • Likelihood-based selection of the number of English documents:")
 • The perplexity varies according to the number of English")
")
 • Comparison of Cross-Lingual Triggers and CL-LSA with Stochastic Transition")
 • Comparison of Stochastic Translation with Manually Created Dictionaries MRD:")


 , (rule)")
, R=2")
- Slides: 36
Lexical Trigger and Latent Semantic Analysis for Cross-Lingual Language Model Adaptation WOOSUNG KIM and SANJEEV KHUDANPUR 2005/01/12 邱炫盛
Outline • Introduction • Cross-Lingual Story-Specific Adaptation • Training and Test Corpora • Experimental Results • Conclusions
Introduction • Statistic language models are indispensable components of many human language technologies. e. g. ASR, IR, MT. • The best-known techniques for estimating LMs require large amounts of text in the domain and language of interest, making this a bottleneck resource. e. g. Arabic. • There have been attempts to overcome this data scarcity problem in the components of speech and language processing systems. E. g. acoustic modeling, linguistic analysis from resource-rich language to resourcedeficient language.
Introduction (cont. ) • For language modeling, if sufficiently good MT is available between resource-rich language, such as English and a resource-deficient language, say Chinese, then one may choose English documents, translate, and use resulting Chinese word statistics to adapt LMs. • Yet, the assumption of some MT capability presupposes linguistic resources may not be available for some languages. – Modest sentence-aligned parallel corpus • Two primary means of exploiting cross-lingual information for language modeling are investigated, neither of which requires any explicit MT capability – Cross-Lingual Lexical Triggers – Cross-Lingual Latent Semantic Analysis
Introduction (cont. ) • Cross-Lingual Lexical Triggers: several content-bearing English words will signal the existence of a number of content-bearing Chinese counterparts in the story. If a set of matched English-Chinese stories is provided for training, one can infer which Chinese words an English word would trigger by using statistic measure. • Cross-Lingual Latent Semantic Analysis: LSA of a collection of bilingual document-pairs provides a representation of words in both languages in a common low-dimensional Euclidean space. This provides another means for using English word-frequencies to improve the Chinese language model from English text. • It is shown through empirical evidence that while both techniques yield good statistics for adapting a Chinese Language model to a particular story, the goodness of the information varies from story to story.
Cross-Lingual Story-Specific Adaptation
Cross-Lingual Story-Specific Adaptation • • Our aim is to sharpen a language model in a resource-deficient language, by using data from a resource-rich language. Assume for the time being that a sufficiently good Chinese-English story alignment is given. Assume further that we have a stochastic translation lexicon-a probabilistic model PT(c|e) Cross-Lingual Unigram Distribution
Cross-Lingual Unigram Distribution Use cross-lingual unigram statistic to sharpen a statistic Chinese LM used for processing the test story di. C. Linear interpolation: Variation:
Obtaining the Matching English Documents di. E • • Assume that we have a stochastic reverse translation lexicon PT(e|c). Compute: • An English bag-of-words representation of the Mandarin story di. C as used in standard vector-based information retrieval. The document di. E with highest TF-IDF weighted consine-similarity is the selected: • • Called query-translation approach to CLIR
Obtaining Stochastic Translation Lexicons • Translation lexicons: PT(c|e) and PT(e|c) – Created out of multiple translations of a word – Stemming and other morphological analyses may be applied to increase the vocabulary coverage. – Alternately, they may be obtained from parallel corpus using MT techniques, such as GIZA++ tools. – Apply the translation models to entire articles, one word at a time, to get a bag of translated words. – However, obtaining translation probabilities using very long (documentsized) sentence-pair has its own issues. • For truly resource-deficient language, one may obtain a translation lexicon via optical character recognition from a printed bilingual dictionary.
Cross-Lingual Lexical Triggers • It seems plausible that most of information one gets from the crosslingual unigram LM is in the form of the altered statistics of topic-specific Chinese words conveyed by the statistics of content-bearing English words in the matching story. • The translation lexicon used for obtaining the information is an expensive resource. • If one were only interested in the conditional distribution of Chinese words given some English words, there is no reason to require translation as an intermediate step. • In monolingual setting, the mutual information between lexical-pairs cooccurring anywhere within a long “window” of each other has been used to capture statistical dependencies not covered by N-gram LMs.
Cross-Lingual Lexical Triggers (cont. ) • A pair of words (a, b) is considered a trigger-pair if, given a word-position in a sentence, the occurrence of a in any of the preceding word-positions significantly alter the probability that the following word in the sentence is b: a is said to trigger b. (The set of preceding word-positions is variably defined. e. g. sentence, paragraph, document. ) • In the cross-lingual setting, a pair of words (e, c) to be a trigger-pair. ( Given an English-Chinese pair of aligned documents) • Translation-pair will be natural candidates for translation-pair, however, it is not necessary for a trigger-pair to also be a translation pair. – E. g. Belgrade may trigger the Chinese translation of Serbia, Kosovo, China, embassy and bomb.
Cross-Lingual Lexical Triggers (cont. ) • Average mutual information, which measures how much knowing the value of one random variable reduces the uncertainty of about another, has been used to identify trigger-pairs. • Compute the average mutual information for every English-Chinese wordpair (e, c): • There are |E|x|C| possible English-Chinese word-pairs which may be prohibitively large to search for the pairs with the highest mutual information. So filter out infrequent words in each language, ex. <5, then measure I(e; c) for all possible pairs, sort them by I(e; c) and select top one million pairs.
Cross-Lingual Lexical Triggers (cont. )
Estimating Trigger LM Probabilities • • Estimate probability PTrig(c|e) and PTrig(e|c) in lieu of the translation probability PT(c|e) and PT(e|c). PTrig(c|e) is based on the unigram frequency of c among Chinese word tokens in that subset of aligned documents di. C which have e in di. E. • Alternative: • I(e; c)=0 whenever (e, c) is not a trigger-pair, and find it to be more effective.
Estimating Trigger LM Probabilities (cont. ) Interpolated model:
Cross-Lingual Latent Semantic Analysis • CL-LSA is a standard automatic technique to extract corpus-based relations between words or documents. • Assume that a document-aligned Chinese-English bilingual corpus is provided. First step is to represent the corpus as a word-document cooccurrence frequency matrix W in which each row represent a word I one of the two language, and each column a document-pair. • W is M×N matrix. M=|C∪E|, N is the number of document-pairs. • Each element wij of W contains the count of the ith word in the jth document -pair. • Next, each row of W is weighted by some function, which deemphasizes frequent (function) words in either language, such as the inverse of the number of documents in which the word appears.
CL-LSA (cont. ) • • Then SVD is performed on W, and some R <<min {M, N}. . • In the rank-R approximation, the jth column W*j of W or document-pair dj. E and dj. C, is a linear combination of the columns of U×S, the weight for the linear combination being provided by the jth column of VT • Similarly,
Cross-Language IR • CL-LSA provides a way to measure the similarity between a Chinese query and English document without using a translation lexicon PT(e|c). • Construct a word-document matrix using the English corpus. All rows corresponding the Chinese vocabulary item have zeros in this matrix. • Project dj. E into semantic space and obtain the R-dimensional representations • Similarly, project Chinese query di. C and calculate consine-similarity between query and documents.
LSA-Derived Translation Probabilities • • • Use CL-LSA framework to construct the translation model PT(c|e). In matrix W, each word is represented as a row no matter whether it is English or Chinese. Project words into R-dimensional space yields row of U, and measure the semantic similarity by consine-similarity. Word-word translation model Exploit a large English corpus to improve Chinese LMs, as well as the use of a document-aligned Chinese-English corpus to overcome the need for a translation lexicon.
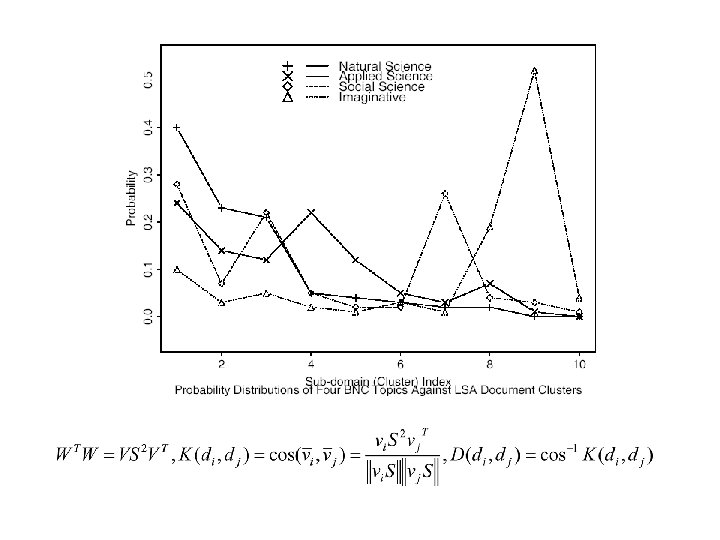
Topic-dependent language models • • • The combination of the story-dependent unigram models with a storyindependent trigram model using linear interpolation seems to be a good choice as they are complementary. Construct monolingual topic-dependent LMs and contrast performance with CL-lexical triggers and CL-LSA. Use well-known k-means clustering algorithm. Use a bag-of-words centroid to represent each topic. Each topic-centroid ti has highest TF-IDF weighted consine-similarity. We believe that the topic-trigram model is a better model, making for informative, even if unfair comparison.
Training and Test Corpora • Parallel Corpus: Hong Kong News – Used for training of GIZA++, construction of trigger-pairs and crosslingual experiment. – Contains 18, 147 document-aligned documents. (actually a sentencealigned corpus) – Dates from July 1997 to April 2000. – Removes a few articles containing nonstandard Chinese characters. – 16, 010 for training, 750 for testing. – 4. 2 M-word Chinese training set, 177 K-word Chinese test set. – 4. 3 M-word English training set, 182 K-word English test set.
Training and Test Corpora (cont. ) • Monolingual Corpora: – XINHUA: 13 million words. Estimate baseline trigram LM – HUB-4 NE: estimate a trigram model from 96 K words in the transcription for training acoustic model. – NAB-TDT: contemporaneous English texts, 45000 articles containing about 30 million words.
Experimental Results • Cross-Lingual Mate Retrieval: CL-LSA vs. Vector-based IR • use well-tuned translation dictionary PT(e|c) (by GIZA++) in Vector-based IR. • Due to memory limitation, 693 was the maximum.
Experimental Results (cont. ) • Baseline ASR Performance of Cross-Lingual LMs P-value are based on the standard NIST MAPSSWE test. http: //www. sportsci. org/resource/stats/pvalues. html http: //www. ndhu. edu. tw/~power/ The improvement brought by CL-interpolated LM is not statistically significant on XINHUA. On HUB-4 NE, Chinese LM text is scare, the CL-interpolated LM delivers considerable benefits via the large English Corpus.
Experimental Results (cont. ) • • • Likelihood-Based Story-Specific Selection of Interpolation Weight and the Number of English Documents per Mandarin Story N-best documents: – experimented with values of 1, 10, 30, 50, 80, 100 and found that N=30 is best for LM performance, but only marginally better than N=1. All documents above a similarity threshold: – the argument against always taking a predetermined number of the best matching documents may be that it ignores the goodness of match. – Threshold=0. 12 gives the lowest perplexity, the reduction is insignificant. – the number of documents selected now varies story to story. • Some stories even the best matching document falls below the threshold. – This points to the need for a story-specific strategy for choosing the number of English documents.
Experimental Results (cont. ) • Likelihood-based selection of the number of English documents:
Experimental Results (cont. ) • The perplexity varies according to the number of English documents, and the best performance is achieved at different points for each story. • For each choice of the number of documents, also λ, is chosen to maximize the likelihood of the first pass output. • Choose 1000 -best-matching English documents and divide the dynamic range of their similarity score into 10 interval. • Choose top one-tenth, not necessarily the top 100 documents, compute PCL-unigram(c|di. E), determine λ that maximizes the likelihood of the first pass output of only the utterances in that story, and record this likelihood. • Repeat this in top two-tenth, three-tenth, and so on. • Obtain the likelihood as a function of similarity threshold. • Called Likelihood-based story-specific adaptation scheme
Experimental Results (cont. )
Experimental Results (cont. ) • Comparison of Cross-Lingual Triggers and CL-LSA with Stochastic Transition Dictionaries
Experimental Results (cont. ) • Comparison of Stochastic Translation with Manually Created Dictionaries MRD: machine-readable dictionary, 18 K English-to-Chinese entries and 24 K Chinese-to-English entries from LDC translation lexicon. Use MRD in place of a stochastic translation lexicon PT(e|c). http: //www. ldc. upenn. edu/Projects/Chinese/LDC_ch. htm MRD leads to a reduction in perplexity, no reduction in WER.
Conclusions • A statistically significant improvement in ASR WER and in perplexity. • Our methods are even more effective when LM training text is hard to come by. • We have proposed methods to build cross-lingual language model, which do not require MT. • By using mutual information statistics and latent semantic analysis form document-aligned corpus, we can extract a significant amount of information for language modeling. • Future work – Develop maximum entropy models to more effectively combine the multiple information source.
• Separability between intra- and inter-topic pairs is much better in the LSA space than in the original space.
, (drawing) , (rule)
• W=7 x 4 matrix (word-command matrix), R=2