Decision Tree JyhDa Wei 1 Induction of Decision

 Attributes = {Outlook, Temperature, Humidity, Wind} Play. Tennis =")
 機率事件= {yes, no}")
 = - log 2(Pi) 5 壹電視主播蕭彤雯")




 h=I(S)= f(p)= p p 1=1, p 2=0 – Entropy h = 0")
 p p 1=1, p 2=p 3=p 4=0 – Entropy h = 0")




")
 Classes: m=2 A={“Science”, “Engineering”, “Business”} I(s 1, s 2)=0. 9988 120")
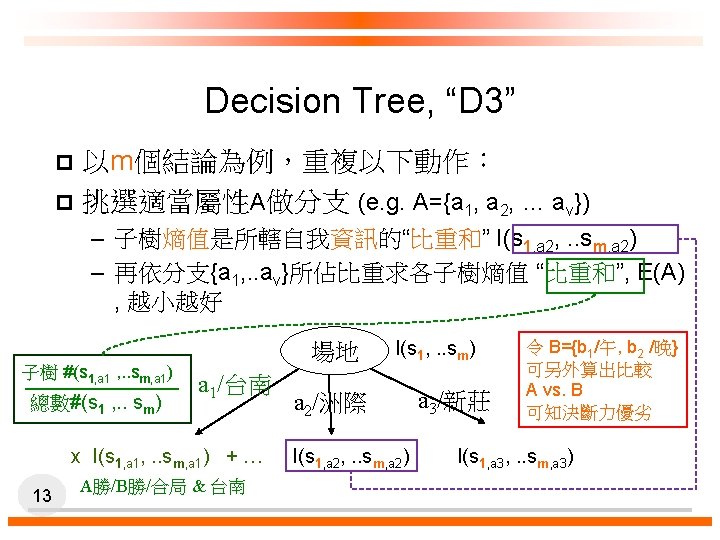
. Relevance analysis – Calculate expected info required to classify an arbitrary")
 Calculate expected info required to classify a given sample if S")
 4. Initial working relation (W 0) derivation – R = 0.")


 分類= {yes, no}")



 32 未完成分割的subset, 以多數決進行決策")
 p Leo Breiman, 2001 p Random resampling (Bootstrapping) p Not requiring")
- Slides: 33
Decision Tree 魏志達 Jyh-Da Wei 1
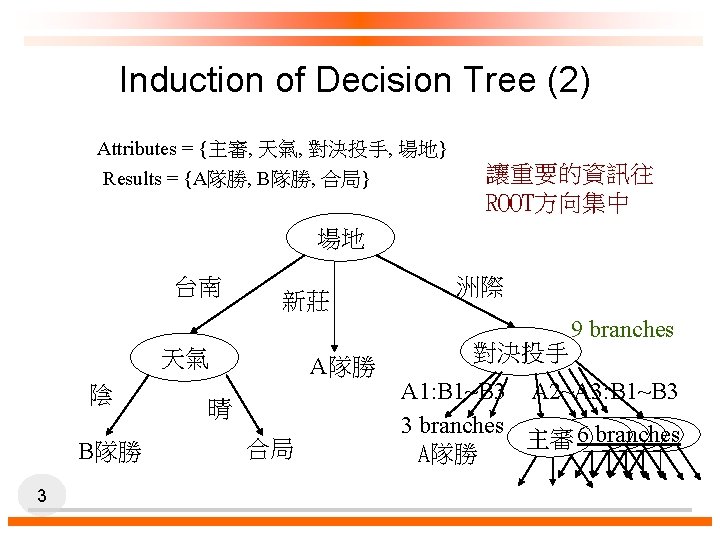
Induction of Decision Tree (1) Attributes = {Outlook, Temperature, Humidity, Wind} Play. Tennis = {yes, no} Outlook sunny rain Humidity high no 2 1. Why not Humidity? overcast Wind no normal yes strong no weak yes 2. For what?
attr 1 attr 2 attr 3 … result 樣本空間 (sample space) 機率事件= {yes, no} 或 {A勝, B勝, 合局} (Random variable Event) Decision Tree = 切割樣本空間(使它越來越不亂) (1) Self-Information (事件) (2) Entropy (樣本空間) 4
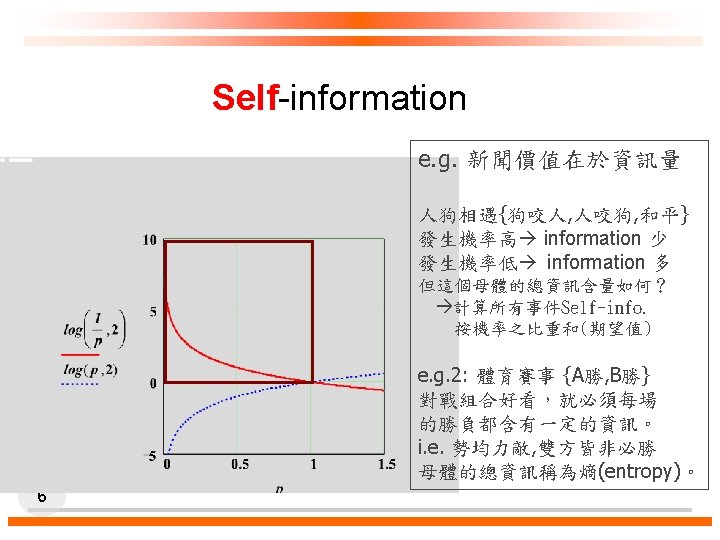
Self-information log 2(1/pi) = - log 2(Pi) 5 壹電視主播蕭彤雯
Example (m=2) h=I(S)= f(p)= p p 1=1, p 2=0 – Entropy h = 0 f(p) p p 1=p 2=1/2 – Entropy h = 1 11
Example (m=4) p p 1=1, p 2=p 3=p 4=0 – Entropy h = 0 p p 1=p 2=1/2, p 3=p 4=0 – Entropy h = 1 p p 1=p 2=p 3=p 4=1/4 – Entropy h = 2 Think: 決策樹的最後分支該有什麼特質? 能否讓這個特質與最後分支提早出現? 12
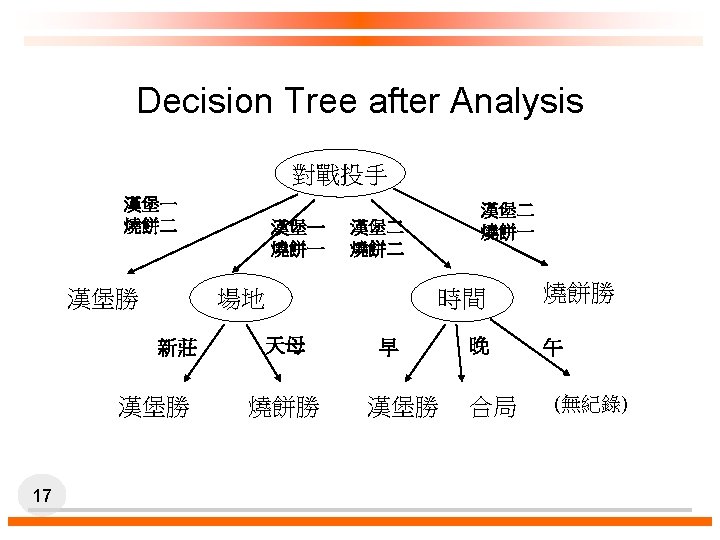
Entropy and Information Gain p p S contains si tuples of class Ci for i = {1, …, m} Information measures info required to classify any arbitrary tuple m=3: {A勝, B勝, 合局} p Entropy of attribute A with values {a 1, a 2, …, av} v=3: {台南, 洲際, 新莊} p p 14 Information gained by branching on attribute A (越大越好)
16
p Break 19
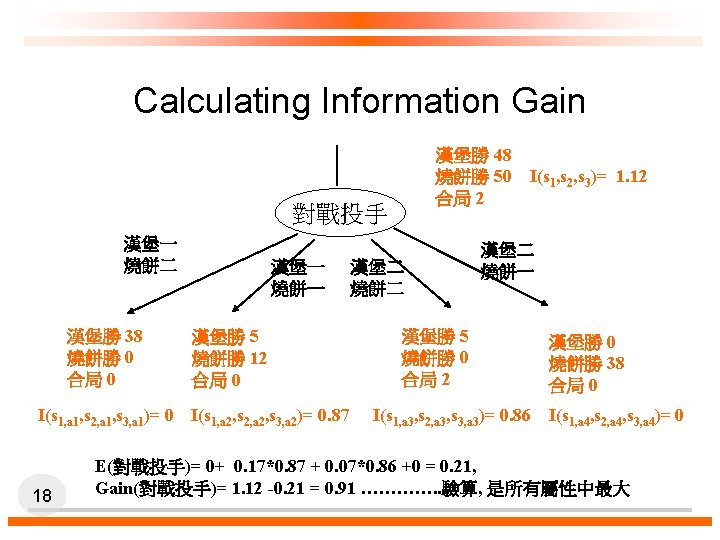
Example II : Scholarship Owners Candidate relation for Target class: Scholarship owner ( =120) Note: 最高會有 2 x 3 x 2 x 2 x 3=72 細項組合, 但有些組合沒出現實例 20 Candidate relation for Contrasting class: Other students ( =130)
Scholarship Owners (1) Classes: m=2 A={“Science”, “Engineering”, “Business”} I(s 1, s 2)=0. 9988 120 “Science”“Engineering” “Business” 0. 9183 21 0. 9892 130 E(A)= 0 84 42 36 46 0 42 Y N Y N 126/250 Iscience + 82/250 Iengineering+ 42/250 Ibusiness =0. 7873
Scholarship Owners (2). Relevance analysis – Calculate expected info required to classify an arbitrary tuple – Calculate entropy of each attribute: e. g. major # scholarship owners in “Science” 22 Number of other students in “Science”
Scholarship Owners (3) Calculate expected info required to classify a given sample if S is partitioned according to the attribute Calculate information gain for each attribute – Information gain for all attributes 23
Scholarship Owners (4) 4. Initial working relation (W 0) derivation – R = 0. 1 亦可設定閥值篩選留下強的屬性,不完整建立 D 3 – remove irrelevant/weakly relevant attributes from candidate relation => drop gender, birth_country – remove contrasting class candidate relation 5. 但若要建立完整D 3, 每個分支後的子樹要各自 24 重新統計, 而採用各自最佳的後續分支策略。
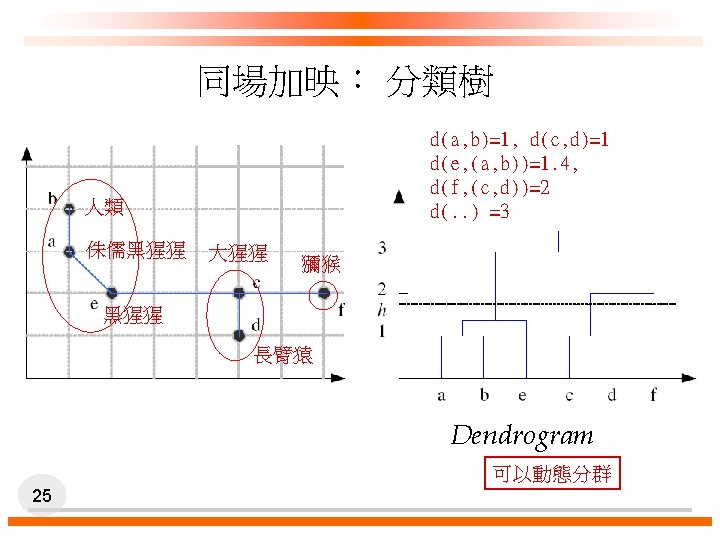
Agglomerative Clustering p p Start with N groups each with one instance and merge two closest groups at each iteration Distance between two groups Gi and Gj: – Single-link: – Complete-link: – Average-link, centroid 26 族群之間的距離有三式可選用
27
attr 1 attr 2 attr 3 … result 樣本空間 (sample space) 分類= {yes, no} 或 {A勝, B勝, 合局} 如果各項量測值是連續值 attr 1, attr 2, …are continuous value? 28
Recursive Partitioning Choose the split that reduces impurity the most p Split points become nodes on the tree p – Attribute – Threshold 29
Attribute and Threshold p Split points become nodes on the tree – Attribute – Threshold p Derived attribute – e. g. w/h 30
Cut on the Same Attribute? ? 31
Cross Validation and Tree Pruning Unseen data Training data (# splits) 32 未完成分割的subset, 以多數決進行決策
Random Forest (RF) p Leo Breiman, 2001 p Random resampling (Bootstrapping) p Not requiring cross validation p Decision by Voting 33