C HAPTE R 5 The Data Warehouse and




















 technological feature of the data warehouse environment is")































. One approach to CDC")



- Slides: 71
C HAPTE R 5 The Data Warehouse and Technology
MANAGING LARGE AMOUNTS OF DATA Prior to data warehousing, the terms terabytes and petabytes were unknown; data capacity was measured in megabytes The explosion of data volume came about because the data warehouse required that both detail and history be mixed in the same environment and gigabytes. With this in mind, the first and most important technological requirement for the data warehouse is the ability to manage large amounts of data, as shown in Figure 5 -1.
Figure 5 -1 Some basic requirements for technology supporting a data warehouse. Large
Large amounts of data need to be managed in many ways—through flexibility of addressability of data stored inside the processor and stored inside disk storage, through indexing, through extensions of data, through the efficient management of overflow, and so forth. In the ideal case, the data warehouse developer builds a data warehouse under the assumption that the technology that houses the data warehouse can handle the volumes required.
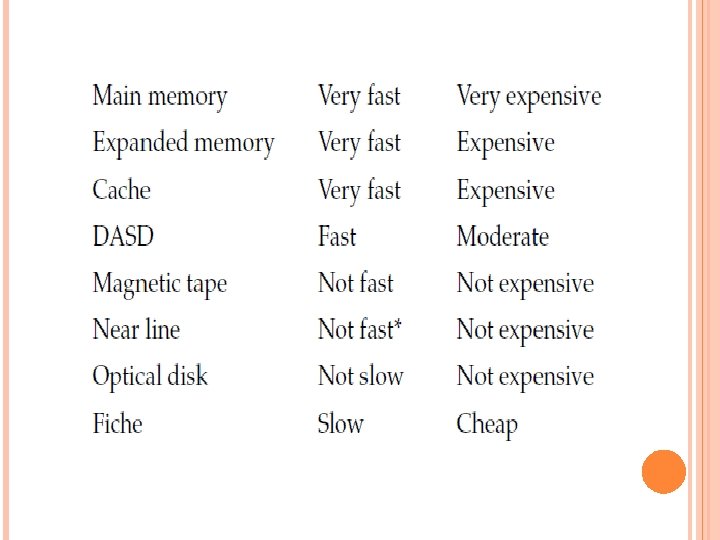
MANAGING MULTIPLE MEDIA In conjunction with managing large amounts of data efficiently and cost effectively, the technology underlying the data warehouse must handle multiple storage media. Following is a hierarchy of storage of data in terms of speed of access and cost of storage:
INDEXING AND MONITORING DATA Another extremely important component of the data warehouse is the ability both to receive data from and to pass data to a wide variety of technologies. The technology supporting the data warehouse is practically worthless if there are major constraints for data passing to and from the data warehouse. In addition to being efficient and easy to use, the interface to and from the data warehouse must be able to operate in a batch mode.
The interface to different technologies requires several considerations: Does the data pass from one DBMS to another easily? Does it pass from one operating system to another easily? Does it change its basic format in passage (EBCDIC, ASCII, and so forth)? Can passage into multidimensional processing be done easily? Can selected increments of data, such as changed data capture (CDC) be passed rather than entire tables? Is the context of data lost in translation as data is moved to other Environments?
PROGRAMMER OR DESIGNER CONTROL OF DATA PLACEMENT Because of efficiency of access and update, the programmer or designer must have specific control over the placement of data at the physical block or page level, as shown in Figure 5 -2. The programmer or designer often can arrange for the physical placement of data to coincide with its usage. In doing so, many economies of resource utilization can be gained in the access of data.
PARALLEL STORAGE AND MANAGEMENT OF DATA One of the most powerful features of data warehouse data management is parallel storage and management. The entire issue of parallel storage and management of data is a complex one. In general, when data management can be parallelized, there is no limit to the volume of data that can be managed. Instead, the limit of data that can be managed is an economic limit, not a technical limit.
METADATA MANAGEMENT Typically, the technical metadata that describes the data warehouse contains the following Data warehouse table structures Data warehouse table attribution Data warehouse source data (the system of record) Mapping from the system of record to the data warehouse Data model specification Extract logging Common routines for access of data Definitions and/or descriptions of data Relationships of one unit of data to another
Business metadata is that metadata that is of use and value to the business person. Technical metadata is that metadata that is of use and value to the technician. Another consideration of metadata is that every technology in the business intelligence environment has its own metadata.
LANGUAGE INTERFACE The data warehouse must have a rich language specification. The languages used by the programmer and the DSS end user to access data inside the data warehouse should be easy to use and robust. Typically, the language interface to the data warehouse should do the following: Be able to access data a set at a time Be able to access data a record at a time Specifically ensure that one or more indexes will be used in the satisfaction of a query Have an SQL interface Be able to insert, delete, or update data
Because of the complexity of SQL, it is highly desirable to have a language interface that creates and manages the query in SQL so that the end user doesn’t have to actually know or use SQL. Efficient Loading of Data An important technological capability of the data warehouse is the ability to load the data warehouse efficiently, as shown in Figure 5 -3. The need for an efficient load capability is important everywhere, but even more so in a large warehouse.
Data is loaded into a data warehouse in two fundamental ways: a record at a time through a language interface or en masse with a utility. Another related approach to the efficient loading of very large amounts of data is staging the data prior to loading. As a rule, large amounts of data are gathered into a buffer area before being processed by extract/transfer/load (ETL) software. The staged data is merged (perhaps edited, summarized, and so forth) before it passes into the ETL layer.
EFFICIENT INDEX UTILIZATION Not only must the technology underlying the data warehouse be able to easily support the creation and loading of new indexes, but those indexes must be able to be accessed efficiently. Technology can support efficient index access in several ways: Using bit maps Having multileveled indexes Storing all or parts of an index in main memory Compacting the index entries when the order of the data being indexed allows such compaction Creating selective indexes and range indexes
COMPACTION OF DATA The very essence of success in the data warehouse environment is the ability to manage large amounts of data. Central to this goal is the ability to compact data. Of course, when data is compacted, it can be stored in a minimal amount of space. when data can be stored in a small space, the access of the data is very efficient.
COMPOUND KEYS Compound keys occur everywhere in the data warehouse environment, primarily because of the time variancy of data warehouse data and because key-foreign key relationships are quite common in the atomic data that makes up the data warehouse.
VARIABLE-LENGTH DATA Another simple but vital technological requirement of the data warehouse environment is the ability to manage variable-length data efficiently, as seen in Figure 5 -4. Variable-length data can cause tremendous performance problems when it is constantly being updated and changed.
LOCK MANAGEMENT A standard part of database technology is the lock manager, which ensures that two or more people are not updating the same record at the same time. One of the effects of the lock manager is that it consumes a fair amount of resources, even when data is not being updated. The data warehouse environment, being able to selectively turn the lock manager off and on is necessary.
INDEX-ONLY PROCESSING A fairly standard database management system feature is the ability to do index-only processing. On many occasions, it is possible to service a request by simply looking in an index (or indexes)— without going to the primary source of data. Technology that is optimal for the data warehouse environment looks for data in the indexes exclusively if such a request can be formulated and/or allow the query user to specify that such an index query has been specified.
FAST RESTORE A simple (but important) technological feature of the data warehouse environment is the capability to quickly restore a data warehouse table from non. DASD storage. When a restore can be done from secondary storage, enormous savings may be possible. Without the ability to restore data quickly from secondary storage, the standard practice is to double the amount of DASD and use one-half of the DASD as a recovery and restore repository.
OTHER TECHNOLOGICAL FEATURES It is noteworthy that many other features of DBMS technology found in the classical transaction processing DBMS play only a small role (if they play a role at all) in the support of the data warehouse environment. Some of those features include the following: Transaction integrity High-speed buffering Row- or page-level locking Referential integrity VIEWs of data Partial block loading
DBMS TYPES AND THE DATA WAREHOUSE With the advent of data warehousing and the recognition of DSS as an integral part of the modern information systems infrastructure, a new class of DBMS has arisen. This class can be called a data warehouse-specific DBMS. Processing in the data warehouse, though, is quite different. Data warehouse processing can be characterized as load-and-access processing.
Data warehouses manage massive amounts of data because they contain the following: Granular, atomic detail Historical information Summary as well as detailed data The first and most important difference between a classical, general-purpose. DBMS and a data warehouse-specific DBMS is how updates are performed. Because recordlevel, transaction-based updates are a regular feature of the general-purpose DBMS, the general-purpose DBMS must offer facilities for such items as the following:
Locking COMMITs Checkpoints Log tape processing Deadlock Backout A second major difference between a generalpurpose DBMS and a data warehouse-specific DBMS regards basic data management. a general-purpose. DBMS, data management at the block level includes space that is reserved for future block expansion at the moment of update or insertion. Typically, this space is referred to as freespace.
Another relevant difference between the data warehouse and the general purpose environment that is reflected in the different types of DBMS is indexing. A general-purpose DBMS environment is restricted to a finite number of indexes. This restriction exists because as updates and insertions occur, the indexes themselves require their own space and their own data management.
CHANGING DBMS TECHNOLOGY An interesting consideration of the information warehouse is changing the DBMS technology after the warehouse has already been populated. change may be in order for several reasons: DBMS technologies may be available today that simply were not an option when the data warehouse was first populated. The size of the warehouse has grown to the point that a new technological approach is mandated. Use of the warehouse has escalated and changed to the point that the current warehouse DBMS technology is not adequate.
The basic DBMS decision must be revisited from time to time. Should the decision be made to go to a new DBMS technology, what are the considerations? A few of the more important ones follow: Will the new DBMS technology meet the foreseeable requirements? How will the conversion from the older DBMS technology to the newer DBMS technology be done? How will the transformation programs be converted?
MULTIDIMENSIONAL DBMS AND THE DATA WAREHOUSE One of the technologies often discussed in the context of the data warehouse is multidimensional DBMS processing (sometimes called OLAP processing). Multidimensional database management systems, or data marts, provide an information system with the structure that allows an organization to have very flexible access to data, to slice and dice data any number of ways, and to dynamically explore the relationship between summary and detail data.
Consider the differences between the multidimensional DBMS and the data warehouse: The data warehouse holds massive amounts of data; the multidimensional DBMS holds at least an order of magnitude less data. The data warehouse is geared for a limited amount of flexible access; the multidimensional DBMS is geared for very heavy any unpredictable access and analysis of data. The data warehouse contains data with a very lengthy time horizon(from 5 to 10 years); the multidimensional DBMS holds a much shorter time horizon of data. The data warehouse allows analysts to access its data in a constrained fashion; the multidimensional DBMS allows unfettered access. Instead of the data warehouse being housed in a multidimensional DBMS, the multidimensional DBMS and the data warehouse enjoy a complementary relationship
Following is the relational foundation for multidimensional DBMS data marts: Strengths: Can support a lot of data. Can support dynamic joining of data. Has proven technology. Is capable of supporting general-purpose update processing. If there is no known pattern of usage of data, then the relational structure is as good as any other.
Weaknesses: Has performance that is less than optimal. Cannot be purely optimized for access processing. Following is the cube foundation for multidimensional DBMS data marts: Strengths: Performance that is optimal for DSS processing. Can be optimized for very fast access of data. If pattern of access of data is known, then the structure of data can be optimized. Can easily be sliced and diced. Can be examined in many ways.
Weaknesses: Cannot handle nearly as much data as a standard relational format. Does not support general-purpose update processing. May take a long time to load. If access is desired on a path not supported by the design of the data, the structure is not flexible. Questionable support for dynamic joins of data.
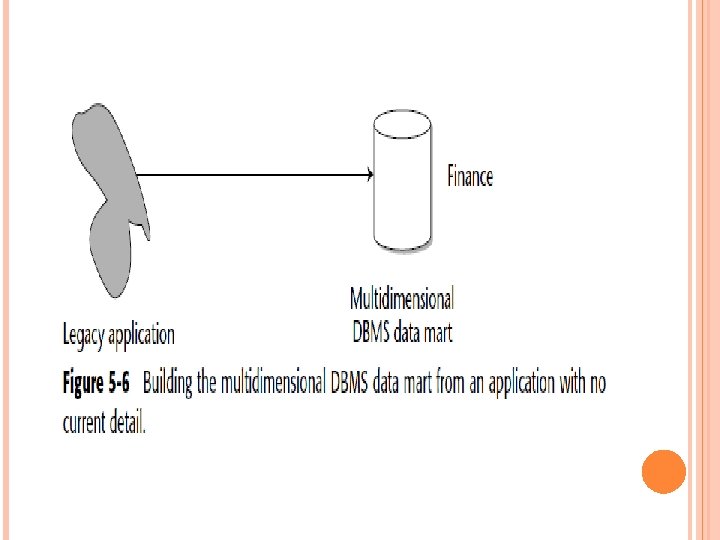
Figure 5 -6 shows the flow of data from the legacy environment directly to the multidimensional DBMS. The design is appealing because it is straightforward and easily achieved. A programmer can immediately start to work on building it.
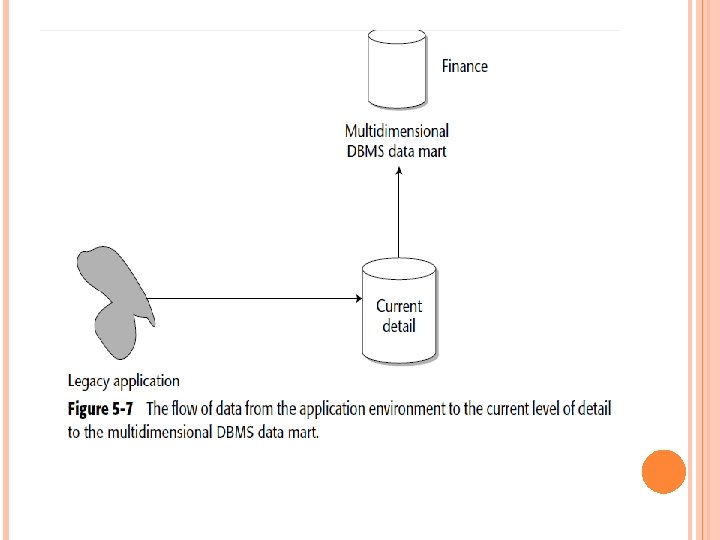
Figure 5 -7 illustrates the feeding of the multidimensional DBMS environment from the current level of detail of the data warehouse environment. Old, legacy operational data is integrated and transformed as it flows into the data warehouse. Once in the data warehouse, the integrated data is stored in the current level of detailed data. From this level, the multidimensional DBMS is fed. At first glance, there may not appear to be substantive differences between the architectures shown in Figure 5 -6 and Figure 5 -7. In fact, putting data first into a data warehouse may even appear to be a wasted effort.
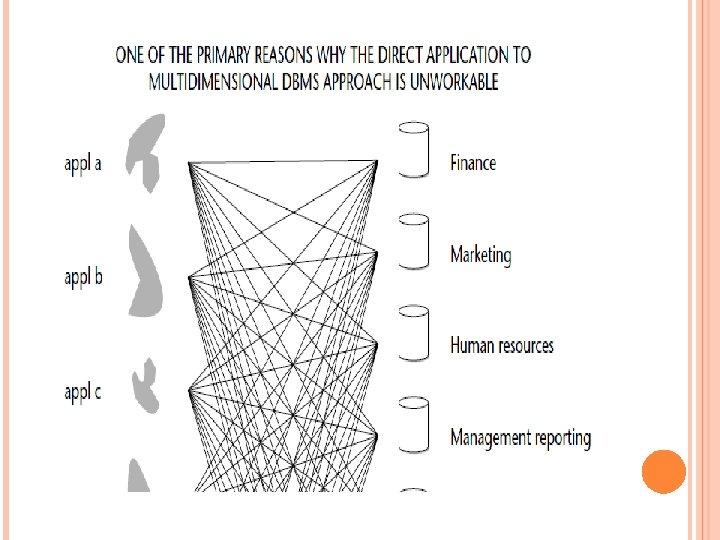
In Figure 5 -8, this scenario has been expanded into a realistic scenario where there are multiple multidimensional DBMSs being directly and individually fed from the legacy systems environment.
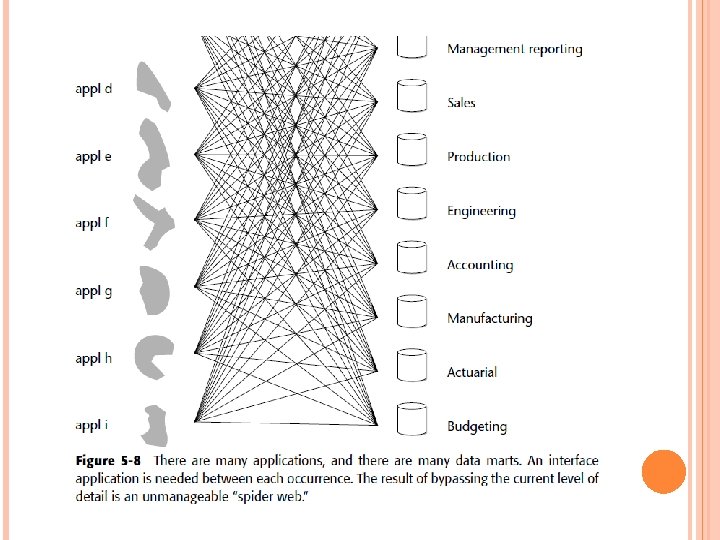
Figure 5 -8 shows that multiple multidimensional DBMSs are being fed directly from the same legacy applications. The amount of development required in extraction is enormous. Each different departmental multidimensional DBMS must have its own set of extraction programs developed for it on a customized basis. There is no integrated foundation when the multidimensional DBMSs are fed directly from the legacy systems environment. Each departmental, multidimensional DBMS has its own interpretation as to how different applications should be integrated.
The amount of development work required for maintenance is enormous. A single change in an old legacy application ripples through many extraction programs. The amount of hardware resources consumed is great. The same legacy data is sequentially and repeatedly passed for each extraction process for each department. The complexity of moving data directly from the legacy environment to the multidimensional DBMS environment precludes effective metadata management and control.
The lack of reconcilability of data is an issue. When a difference in opinion exists among various departments, each having its own multidimensional DBMS, there is no easy resolution. Each time a new multidimensional DBMS environment must be built, it must be built from the legacy environment, and the amount of work required is considerable.
DATA WAREHOUSING ACROSS MULTIPLE STORAGE MEDIA One interesting aspect of a data warehouse is the dual environments often created when a large amount of data is spread across more than one storage medium. One processing environment is the DASD environment where online, interactive processing is done. Logically, the two environments combine to form a single data warehouse. Physically, however, the two environments are very different.
In many cases, the underlying technology that supports the DASD environment is not the same technology that supports the mass store environment. Part of the DASD-based data warehouse resides on one vendor’s technology and another part of the data warehouse resides on another vendor’s database technology. If the split is deliberate and part of a larger distributed data warehouse, such a split is just fine.
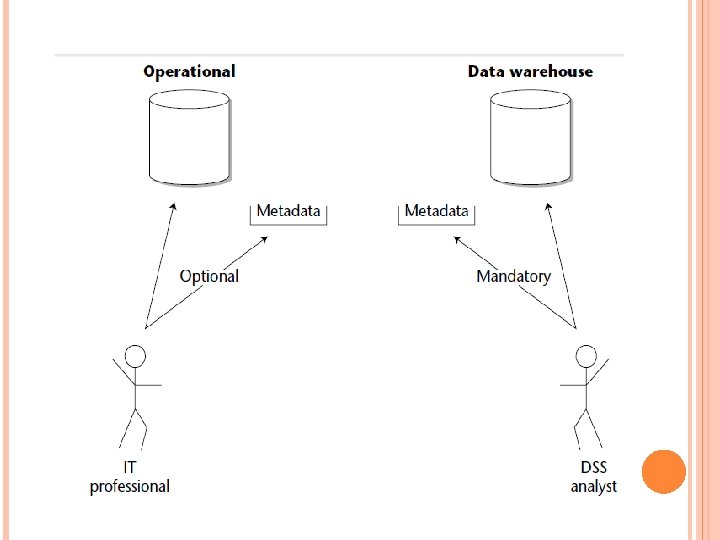
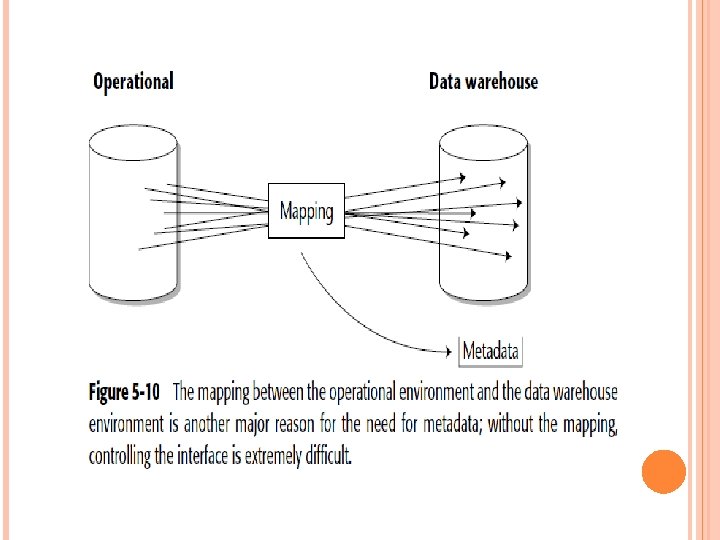
THE ROLE OF METADATA IN THE DATA WAREHOUSE ENVIRONMENT The role of metadata in the data warehouse environment is very different from the role of metadata in the operational environment. In the operational environment, metadata is treated almost as an afterthought and is relegated to the same level of importance as documentation. The importance of its role in the data warehouse environment is illustrated in Figure 5 -9. Two different communities are served by operational metadata and data warehouse metadata.
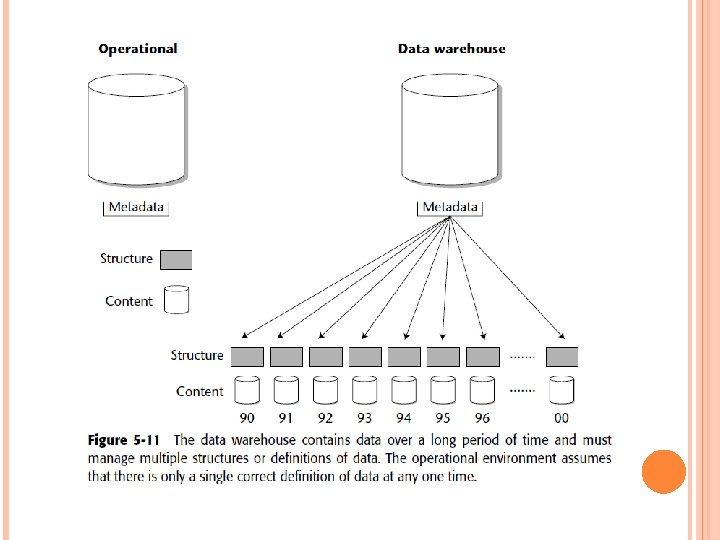
Yet another important reason for the careful management of metadata in the data warehouse environment is shown in Figure 5 -11. As mentioned, data in a data warehouse exists for a lengthy time span—from 5 to 10 years.
CONTEXT AND CONTENT With the lengthy spectrum of time that is part of a data warehouse comes a new dimension of data-context. Suppose a manager asks for a report from the data warehouse for 1995. The report is generated, and the manager is pleased. In fact, the manager is so pleased that a similar report for 1990 is requested. Because the data warehouse carries historical information, such a request is not hard to accommodate. The report for 1990 is generated. Now the manager holds the two reports—one for 1995 and one for 1990— in his hands and declares that the reports are a disaster.
When context is added to the contents of data over time, the contents and the context become quite enlightening. To interpret and understand information over time, a whole new dimension of context is required. Three Types of Contextual Information Three levels of contextual information must be managed: Simple contextual information Complex contextual information External contextual information
Simple contextual information relates to the basic structure of data itself, and includes such things as these: The structure of data The encoding of data The naming conventions used for data The metrics describing the data, such as: How much data there is How fast the data is growing What sectors of the data are growing How the data is being used
Complex contextual information describes the same data as simple contextual information, but from a different perspective. This type of information addresses such aspects of data as these: Product definitions Marketing territories Pricing Packaging Organization structure Distribution
External contextual information is information outside the corporation that nevertheless plays an important role in understanding information over time. Some examples of external contextual information include the following: Economic forecasts: Inflation Financial trends Taxation Economic growth Political information Competitive information Technological advancements Consumer demographic movements
CAPTURING AND MANAGING CONTEXTUAL INFORMATION Complex and external contextual types of information are hard to capture and quantify because they are so unstructured. Compared to simple contextual information, external and complex contextual types of information are amorphous.
LOOKING AT THE PAST You could argue that the information systems profession has had contextual information in the past. Some of these shortcomings are as follows: The information management attempts were aimed at the information systems developer, not the end user. Attempts at contextual management were passive. Attempts at contextual information management were in many cases removed from the development effort. Attempts to manage contextual information were limited to only simple contextual information.
REFRESHING THE DATA WAREHOUSE Once the data warehouse is built, attention shifts from the building of the data warehouse to its day-to -day operations. The first step most organizations take in the refreshment of data warehouse data is to read the old legacy databases. As a general-purpose strategy, however, repeated and direct reads of the legacy data are very costly. The expense of direct legacy database reads mounts in two ways. First, the legacy DBMS must be online and active during the read process.
Two basic techniques are used to trap data as an update is occurring in the legacy operational environment. One technique is called data replication; the other is called change data capture. A trigger is set that causes the update activity to be captured. One of the advantages of replication is that the process of trapping can be selectively controlled. Only the data that needs to be captured is, in fact, captured. Another advantage of replication is that the format of the data is “clean” and well-defined.
The second approach to efficient refreshment is changed data capture(CDC). One approach to CDC is to use the log tape to capture and identify the changes that have occurred throughout the online day. Many obstacles are in the way, including the following: The log tape contains much extraneous data. The log tape format is often arcane. The log tape contains spanned records. The log tape often contains addresses instead of data values. The log tape reflects the idiosyncrasies of the DBMS and varies widely from one DBMS to another.
There is a second approach to CDC: lift the changed data out of the DBMS buffers as change occurs. In this approach, the change is reflected immediately. So, reading a log tape becomes unnecessary, and there is a time-savings from the moment a change occurs to when it is reflected in the warehouse.
TESTING In the classical operational environment, two parallel environments are set up —one for production and one for testing. The production environment is where live processing occurs. The testing environment is where programmers test out new programs and changes to existing programs.
It is very unusual to find a similar test environment in the world of the data warehouse, for the following reasons: Data warehouses are so large that a corporation has a hard time justifying one of them, much less two of them. The nature of the development life cycle for the data warehouse is iterative. For the most part, programs are run in a heuristic manner, not in a repetitive manner.