U S ATLAS Tier1 Site Report Michael Ernst


 • Below Middleware services are running on VMs • 8")
 • we have two GUMS servers gums. racf. bnl. gov,")








 atlas (12000) prod (10000) (quota) analysis (2000) himem")







 are filled in by multicore jobs")








 Data Transfer activities between")






- Slides: 37
U. S. ATLAS Tier-1 Site Report Michael Ernst mernst@bnl. gov U. S. ATLAS Facilities Workshop – March 23, 2015 1
Tier-1 High Value Equipment Deployment Plan • Capacity planning based on Pledges (23% author share) + 20% for US Physicists • FY 15 Equipment Deployment – Equipment (i. e. CPU, disk, central servers) replenished after 4 -5 years of operation 2
Tier-1 Middleware Deployment (1/2) • Below Middleware services are running on VMs • 8 CEs, two of them accept both OSG and ATLAS jobs, the other six are dedicated to ATLAS jobs: – gridgk 01 (BNL_ATLAS_1) is GRAM CE, for all OSG VOs, OSG release 3. 2. 13 – gridgk 02 (BNL_ATLAS_2) is HTCondor CE, for all OSG VOs, OSG release 3. 2. 16 – gridgk 03 (BNL_ATLAS_3) is GRAM CE, OSG release 3. 2. 13 – gridgk 04 (BNL_ATLAS_4) is GRAM CE, OSG release 3. 2. 13 – gridgk 05 (BNL_ATLAS_5) is GRAM CE, OSG release 3. 2. 13 – gridgk 06 (BNL_ATLAS_6) is GRAM CE, OSG release 3. 2. 13 – gridgk 07 (BNL_ATLAS_7) is HTCondor CE, OSG release 3. 2. 18 – gridgk 08 (BNL_ATLAS_8) is GRAM CE, OSG release 3. 2. 19 3
Tier-1 Middleware Deployment (2/2) • we have two GUMS servers gums. racf. bnl. gov, GUMS-1. 3. 18 gumsdev. racf. bnl. gov, GUMS-1. 3. 18 They are configured identical, although one is production and the other is dev. • we have one RSV monitoring host that runs RSV probes against all CEs and the d. Cache SE. services 02. usatlas. bnl. gov, OSG 3. 2. 12 • 3 redundant Condor-G submit hosts for ATLAS APF 4
https: //www. racf. bnl. gov/docs/services/cvmfs/info 5
6
7
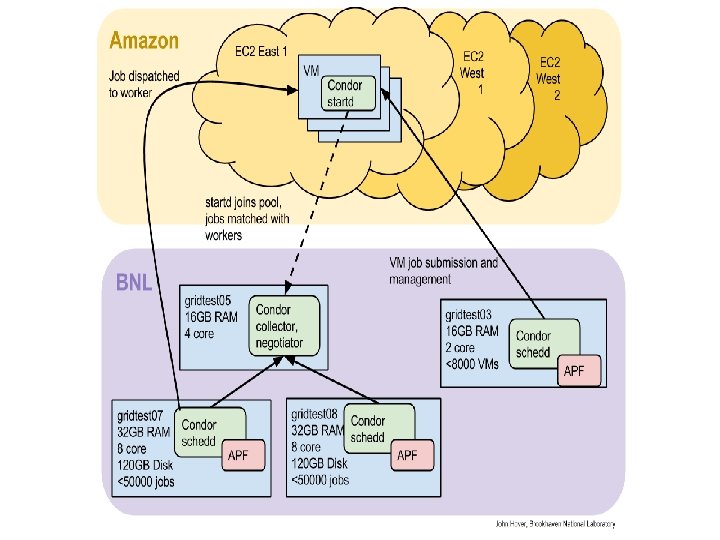
Previous, Ongoing and New ATLAS cloud efforts/activities John Hover Previous/Ongoing Some smaller-scale commercial cloud R&D (Amazon, Google) performed at BNL and CERN Currently running at medium scale (1000 jobs) on ~10 academic clouds using University of Victoria Cloud Scheduler. Heavy investment/conversion to Openstack at CERN, majority of Central Services now running on Agile Infrastructure Openstack cluster at Brookhaven National Lab (720 cores) New Collaboration with AWS and ESnet on large-scale exploration of AWS resources for ATLAS Production and Analysis (~30 k concurrent jobs in Nov) Aiming at scaling up to ~100 k concurrent jobs running in 3 AWS regions, 100 G AWS ESnet Network Peerings Use of S 3 Storage AWS-internally and between AWS and ATLAS object Storage Instances
Example us-east-1 region Amazon Web Services Be. St. Man SE Distributed among 3 EC 2 VMs 1 SRM 2 Grid. FTP server S 3 fs (Fuse based file system) 3 buckets mapped into 3 mount points per VM / region: Simple Storage Service (S 3) ATLASUSERDISK ATLASPRODDISK ATLASDATADISK SRM/Grid. FTP protocol data transmission S 3 / HTTP(S) direct access via FTS or APIs S 3/ HTTP(S) via S 3 FS ATLAS PRODUCTON DATA DISTRIBUTION SERVICES
“Impedance mismatch” between commercial and scientific computing
ATLAS Autonomous Multicore Provisioning Dynamic Allocation with Condor William Strecker-Kellogg
ATLAS Tree Structure • Use hierarchical group-quotas in Condor – Leaf-nodes in the hierarchy get jobs submitted to them and correspond 1: 1 with panda-queues – Surplus resources from underutilized queues are automatically allocated to other, busier queues • Quotas determine steady-state allocation when all queues are busy – Quota of parent groups are the sum of their children’s quotas (see next slide for diagram)
ATLAS Tree Structure <root> grid (40) atlas (12000) prod (10000) (quota) analysis (2000) himem (1000) mcore (5500) single (3500) short (1000) long (1000)
Surplus Sharing • Surplus sharing is controlled by boolean accept_surplus flag on each queue – Quotas / surplus are normalized in units of CPUs • Groups with flag can share with their siblings – Parent groups with flag allow surplus to “flow down” the tree from their siblings to their children – Parent groups without accept_surplus flag constrain surplus-sharing to among their children
Surplus Sharing • Scenario: analysis has quota of 2000 and no accept_surplus; short and long have a quota of 1000 each and accept_surplus on – short=1600, long=400…possible – short=1500, long=700…impossible (violates analysis quota)
Partitionable Slots • Each batch node is configured to be partitioned into arbitrary slices of CPUs – Condor terminology: • Partitionable slots are automatically sliced into dynamic slots • Multicore jobs are thus accommodated with no administrative effort – Farm is filled depth first (default is breadth first) to reduce fragmentation • Only minimal (~1 -2%) defragmentation necessary
Where’s the problem? • Everything works perfectly with all single-core • However… Multicore jobs will not be able to compete for surplus resources fairly – Negotiation is greedy, if 7 slots are free, they won’t match an 8 -core job but will match 7 single-core jobs in the same cycle • If any multicore queues compete for surplus with single core queues, the multicore will always lose • A solution outside Condor is needed – Ultimate goal is to maximize farm utilization
Dynamic Allocation • A script watches panda queues for demand – Queues that have few or no pending jobs are considered empty – Short spikes are smoothed out in demand calculation • Script is aware of Condor’s group-structure – Builds tree dynamically from database • This facilitates altering the group hierarchy with no rewriting of the script
Dynamic Allocation • Script figures out which queues are able to accept_surplus – Based on comparing “weight” of queues • Weight defined as size of job in queue (# cores) – Able to cope with any combination of demands – Prevents starvation by allowing surplus into “heaviest” queues first • Avoids both single-core and multicore queues competing for the same resources – Can shift balance between entire sub-trees in hierarchy (e. g. analysis <--> production)
Results
Results • Dips in serial production jobs (magenta) are filled in by multicore jobs (pink) – Some inefficiency remains due to fragmentation • There is some irreducible average wait-time for 8 cores on a single machine to become free • Results look promising, will even allow opportunistic workload to backfill if all ATLAS queues drain – Currently impossible as Condor doesn’t support preemption of dynamic slots… the Condor team is close to providing a solution
OSG Opportunistic Usage at the Tier-1 Center Simone Campana - ATLAS SW&C Week 23 Bo Jayatilaka
OSG Opportunistic Usage at the Tier-1 Center Simone Campana - ATLAS SW&C Week 24
Tier-1 Production Network Connectivity • BNL connected to ESnet at 200 G • Have Tier-1 facility connected to ESnet at 200 G via BNL Science DMZ • • • 30 G OPN production circuit 10 G OPN backup circuit 40 G General IP Services 100 G LHCONE production circuit All circuits can “burst” to the maximum of 200 G, depending on available b/w
BNL WAN Connectivity in 2013 OPN 2. 5 Gbps LHCONE 3. 5 Gbps R&E + Virtual Circuits ATLAS Software and Computing Week - 26
BNL Perimeter and Science DMZ 27
Current Implementation
12 PB WNs
LAN connectivity WN T 1 Disk Storage All WN connected at 1 Gbps Typical bandwidth 10– 20 MB/s, Peak at 50 MB/s Analysis queues configured for Direct read 30
BNL in ATLAS Distributed Data Management (Apr – Dec 2012) Data Transfer activities between BNL and other ATLAS Sites 2 PB 13. 5 PB BNL to ATLAS T 1 s & T 2 s Monthly average transfer rate up to 800 MB/s; daily peaks have been observed 5 times higher MB/s Data Export Data Import BNL in navy blue ATLAS Distributed Data 31 Management Dashboard
CERN/T 1 -> BNL Transfer Performance • Regular ATLAS Production + Test Traffic • Observations (all in the context of ATLAS) – Never exceeded ~50 Gbits/sec – CERN (ATLAS EOS) -> BNL limited at ~1. 5 GB/s • Achieved >60 Gbits/s between 2 Hosts @ CERN and BNL
FTS 3 Service at BNL 33
From BNL to T 1 s 34
35
From T 1 s to BNL 36
From T 1 s and T 2 s to BNL in 2012 - 2013 37