The Mem SQL Query Optimizer A modern optimizer















) CREATE")











 Result. Table: CREATE RESULT TABLE r 0 PARTITION BY (o_custkey) AS")
 / 7. 0 as avg_yearly FROM lineitem, part WHERE")
 / 7. 0 AS avg_yearly FROM lineitem, (")
![Query Optimization Example: Enumerator Project [s 2 / 7. 0 AS avg_yearly] Aggregate [SUM(1)](https://slidetodoc.com/presentation_image_h/82cf1d085388eb9bac6cc84311101470/image-32.jpg "Query Optimization Example: Enumerator Project [s 2 / 7. 0 AS avg_yearly] Aggregate [SUM(1)")







- Slides: 39
The Mem. SQL Query Optimizer: A modern optimizer for realtime analytics in a distributed database Jack Chen, Samir Jindel, Robert Walzer, Rajkumar Sen, Nika Jimsheleishvilli, Michael Andrews Presentation by Andria Trigeorgi and Elena Constantinou Instructor: Demetris Zeinalipour University of Cyprus | EPL 646: Advanced Topics in Databases
Motivation • Enterprises need to run complex analytic queries on real-time for interactive real-time decision making • Analytical queries need to be optimized and executed very quickly 2 University of Cyprus | EPL 646: Advanced Topics in Databases
Mem. SQL • Is a distributed memory-optimized SQL database • Real-time transactional and analytical workloads • Can store data in two formats: • in-memory row-oriented • disk-backed column-oriented • Sub-second query latencies over large volumes of changing data 3 University of Cyprus | EPL 646: Advanced Topics in Databases
Mem. SQL - Architecture A • Shared-nothing architecture • Two types of nodes: • Aggregator nodes = scheduler nodes • Leaf nodes = execution nodes user query L ||||||| | A L L ||||||| |partitions | • Two ways to distribute the user data based on table • Distributed tables - rows are sharded across the leaf nodes • Reference tables - the table data is replicated across all nodes 4 University of Cyprus | EPL 646: Advanced Topics in Databases
Mem. SQL: Execution of a query • Aggregator node: Converts the query into a distributed query execution plan – DQEP • Series of DQEPs = operations which are executed on nodes • Representation of DQEPs using a SQL-like syntax and interface • Query plans are compiled to machine code and are cached, without values for the parameters 5 University of Cyprus | EPL 646: Advanced Topics in Databases
Components of the Optimizer • To find the best query execution plan with the least cost requires: • Query rewrites • Cost model of query execution • Complex queries: joins across star and snowflake schemas, sorting, grouping and aggregations, and nested subqueries → powerful and fast query optimization 6 University of Cyprus | EPL 646: Advanced Topics in Databases
Components of the Optimizer Rewriter • Applies SQL-to-SQL rewrites on the query, using heuristics or cost (based on the characteristics of the query and the rewrite itself) • Applies some rewrites in a top-down manner, while applying others in a bottom-up manner and interleaves rewrites 7 University of Cyprus | EPL 646: Advanced Topics in Databases
Components of the Optimizer Enumerator • Central component of the optimizer • Determines the distributed join order and data movement decisions • Selects the best plan, based on the cost models of the database operations and the network data movement operations • Called by the Rewriter to cost rewrites 8 University of Cyprus | EPL 646: Advanced Topics in Databases
3 Components of the Optimizer Planner • Converts the logical execution plan to a sequence of distributed query and data movement operations • Uses SQL extensions: Remote. Tables and Result. Tables 9 University of Cyprus | EPL 646: Advanced Topics in Databases
Important Contributions • Rewriter calls Enumerator to cost rewritten queries based on distributed cost • Enumerator uses pruning techniques (heuristics), to enumerate faster • Parts of the join graph run as bushy joins 10 University of Cyprus | EPL 646: Advanced Topics in Databases
Steps to optimize a query 11 1. Forms an operator tree for the query and sent it to the query optimizer 2. Rewriter applies the beneficial query rewrites to the operator tree 3. Enumerator uses a search space exploration algorithm with pruning to find the best plan for join order 4. Planner generates the DQEP, that consists SQL-like DQEP Steps, and these steps can be sent as queries over the network to be executed on nodes across the cluster University of Cyprus | EPL 646: Advanced Topics in Databases
Rewriter: Cost-Based Rewrites • Column Elimination transformation: removes any projection columns that are never used → reduce I/O cost and network resources • Group-By Pushdown: reorders a ‘group by’ before a join to evaluate the group by earlier • This transformation is not always beneficial, depending on the sizes of the joins and the cardinality of the group by → needing of cost estimates 12 University of Cyprus | EPL 646: Advanced Topics in Databases
Rewriter: Heuristic Rewrites • Sub-Query Merging: Merges subselects • Disadvantage: In the case of joining very large numbers of tables under a number of simple views, merging all the subselects would result in a single large join of all these tables → discards information about the structure of the join graph & expensive for the Enumerator to effectively optimize • Solution: Uses heuristics to detect this type of situation and avoid merging all the views in such cases 13 University of Cyprus | EPL 646: Advanced Topics in Databases
Interleaving of Rewrites Outer Join • • • 14 Inner Join Pushing a predicate down may enable Outer Join to Inner Join conversion if that predicate rejects NULLs of the outer table Interleaving of two rewrites: going top-down over each select block (before processing any subselects ) and apply 1) Outer Join to Inner Join and then 2) Predicate Pushdown Rewrites like bushy join are done bottom-up, because they are costbased University of Cyprus | EPL 646: Advanced Topics in Databases
Costing Rewrites • Estimation of the cost of a candidate query transformation by calling the Enumerator, to see how the transformation affects the potential execution plans of the query tree • The Enumerator determines the best execution plan taking into account data distribution, because a rewrite can affect the efficient distributed plan that the Optimizer can chose 15 University of Cyprus | EPL 646: Advanced Topics in Databases
Costing Rewrites CREATE TABLE T 1 (a int, b int, shard key (b)) CREATE TABLE T 2 (a int, b int, shard key (a), unique key (a)) Q 1: SELECT sum(T 1. b) AS s FROM T 1, T 2 WHERE T 1. a = T 2. a GROUP BY T 1. a, T 1. b Q 2: SELECT V. s from T 2, (SELECT a, sum(b) as s FROM T 1 GROUP BY T 1. a, T 1. b )V WHERE V. a = T 2. a; �� 1=200, 000 be the rowcount of T 1 and �� 2=50, 000 be the rowcount of T 2 lookup cost of �� J=1 units (unique key on T 2. a ) the group-by is executed using a hash table with an average cost of �� G=1 units per row ���� Q 1=�� 1�� J+�� 1�� J�� G=200, 000�� J+20, 000�� G=220, 000 ���� Q 2=�� 1�� G+�� 1�� G�� J=200, 000�� G+50, 000�� J=250, 000 16 University of Cyprus | EPL 646: Advanced Topics in Databases
Costing Rewrites • Run the query in a distributed setting • T 2 is sharded on T 2. a, but T 1 is not sharded on T 1. a → compute this join by reshuffling • �� R=3 units per row ���� Q 1=�� 1�� R+�� 1�� J�� G=200, 000(�� R+�� J)+20, 000�� G=620, 000 ���� Q 2=�� 1�� G+�� 1�� G�� R+�� 1�� G�� J=200, 000�� G +50, 000(�� R+�� J)=400, 000 17 University of Cyprus | EPL 646: Advanced Topics in Databases
Bushy Joins • Finding the optimal join permutation extremely costly and time consuming • Many database systems do not consider bushy joins limiting their search join trees • Query rewrite mechanism to generate bushy join plans is not new and has already been explored • Mem. SQL use Bushy joins plan • Use heuristic – based approach which consider only hopeful bushy joins University of Cyprus | EPL 646: Advanced Topics in Databases
Bushy Plan Heuristic • The rewrite mechanism consider promising bushy joins by forming one or more subselects. • The enumerator to determine the cost in order to decide which candidate option is better University of Cyprus | EPL 646: Advanced Topics in Databases
Generate bushy plans - Algorithm 1. Build a graph where vertexes represent tables and edges represent join predicate 2. Identify candidate satellite tables 3. Select only the satellite tables, which are the tables connected to only other table in the graph 4. Identify seed tables, which are tables that are connected to at least two different tables, at least one of which is a satellite table. 5. For each seed table: a. Compute the cost C 1 of the current plan b. Create a derived table containing the seed table joined to its adjacent satellite tables c. Apply the Predicate Pushdown rewrite followed by the Column Elimination rewrite d. Compute the cost C 2. If C 1 < C 2, discard the changes made in steps (b) and (c), and otherwise keep them. University of Cyprus | EPL 646: Advanced Topics in Databases
University of Cyprus | EPL 646: Advanced Topics in Databases
Enumerator • Optimizes the join plan within each select block • Processes the select blocks bottom-up • Huge search space → bottom-up System-R with sharding distribution Shard keys: (1) predicate columns of equality joins and (2) grouping columns 26 University of Cyprus | EPL 646: Advanced Topics in Databases
Enumerator Data Movement Operations: • Broadcast: Tuples are broadcasted from each leaf node to all other leaf nodes Broadcast Cost: R D • Reshuffle: Tuples are moved from each leaf node to a target leaf node based on a hash of a chosen set of distribution columns Reshuffle Cost: 1 / N (R D + R H) 27 University of Cyprus | EPL 646: Advanced Topics in Databases
Planner: Remote Tables and Result Tables Remote Tables • Communication between each leaf and all the partitions Problem: Each partition querying all other partitions Result Tables (SQL SELECT ) • Store intermediate results for each partition and then compute the final select 28 University of Cyprus | EPL 646: Advanced Topics in Databases
Planner SELECT * FROM x JOIN y WHERE x. a = y. a AND x. b < 2 AND y. c > 5 (table x is sharded on a but table y is not) Reshuffle Broadcast 1. CREATE RESULT TABLE r 1 AS SELECT * FROM x WHERE x. b < 2 (on every partition) 1. CREATE RESULT TABLE r 1 PARTITION BY (y. a) AS SELECT * FROM y WHERE y. c > 5 (on every partition) 2. CREATE RESULT TABLE r 2 AS SELECT * FROM REMOTE(r 1) (on every node) 3. SELECT * FROM r 2 JOIN y WHERE y. c > 5 AND r 2. a = y. a (on 2. SELECT * FROM x JOIN REMOTE(r 1(p)) WHERE x. b < 2 AND x. a = r 1. a (on every partition) 29 University of Cyprus | EPL 646: Advanced Topics in Databases
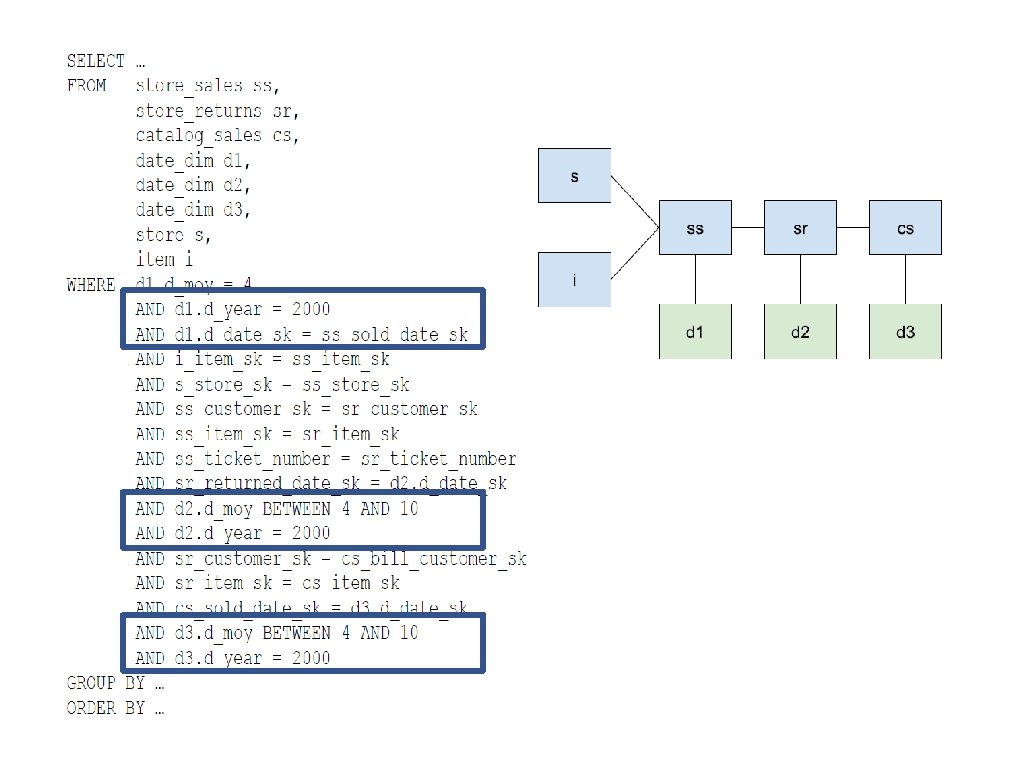
DQEP Example SELECT FROM WHERE c_custkey, o_orderdate orders, customer o_custkey = c_custkey AND o_totalprice < 1000 Problem: The shard keys of the tables do not exactly match with the join keys Solution: Data movement operation 30 University of Cyprus | EPL 646: Advanced Topics in Databases
DQEP Example (1) Result. Table: CREATE RESULT TABLE r 0 PARTITION BY (o_custkey) AS SELECT orders. o_orderdate as o_orderdate, orders. o_custkey as o_custkey FROM orders WHERE orders. o_totalprices < 1000 (2) Remote. Table: SELECT customer. c_custkey as c_custkey, r 0. o_orderdate as o_orderdate FROM REMOTE(r 0(p)) JOIN customer WHERE r 0. o_custkey = customer. c_custkey 31 University of Cyprus | EPL 646: Advanced Topics in Databases
Query Optimization Example SELECT sum(l_extendedprice) / 7. 0 as avg_yearly FROM lineitem, part WHERE p_partkey = l_partkey AND p_brand = 'Brand#43' AND p_container = 'LG PACK' AND l_quantity < ( SELECT 0. 2 * avg(l_quantity) FROM lineitem WHERE l_partkey = p_partkey ) 32 University of Cyprus | EPL 646: Advanced Topics in Databases
Query Optimization Example: Rewriter SELECT Sum(l_extendedprice) / 7. 0 AS avg_yearly FROM lineitem, ( SELECT 0. 2 * Avg(l_quantity) AS s_avg, l_partkey AS s_partkey FROM lineitem, part WHERE p_brand = 'Brand#43' scalar subquery → join AND p_container = 'LG PACK' AND p_partkey = l_partkey GROUP BY l_partkey moving the join down ) sub WHERE s_partkey = l_partkey AND l_quantity < s_avg 33 University of Cyprus | EPL 646: Advanced Topics in Databases
Query Optimization Example: Enumerator Project [s 2 / 7. 0 AS avg_yearly] Aggregate [SUM(1) AS s 2] Gather partitions: all Aggregate [SUM(lineitem_1. l_extendedprice) AS s 1] Filter [lineitem_1. l_quantity < s_avg] Nested. Loop. Join |---Index. Range. Scan lineitem AS lineitem_1, | KEY (l_partkey) scan: [l_partkey = p_partkey] Broadcast Hash. Group. By [AVG(l_quantity) AS s_avg] groups: [l_partkey] Nested. Loop. Join |---Index. Range. Scan lineitem, | KEY (l_partkey) scan: [l_partkey = p_partkey] Broadcast Filter [p_container = 'LG PACK' AND p_brand = 'Brand#43'] Table. Scan part, PRIMARY KEY (p_partkey) 34 University of Cyprus | EPL 646: Advanced Topics in Databases broadcast
Query Optimization Example: Enumerator - DQEP CREATE RESULT TABLE r 0 AS SELECT p_partkey FROM part WHERE p_brand = 'Brand#43’ AND p_container = 'LG PACK'; Result. Tables CREATE RESULT TABLE r 1 AS SELECT 0. 2 * Avg(l_quantity) AS s_avg, l_partkey as s_partkey FROM REMOTE(r 0), lineitem WHERE p_partkey = l_partkey Remote. Tables GROUP BY l_partkey; SELECT Sum(l_extendedprice) / 7. 0 AS avg_yearly FROM REMOTE(r 1), lineitem WHERE p_partkey = s_partkey AND l_quantity < s_avg 35 University of Cyprus | EPL 646: Advanced Topics in Databases
Experiments • TCP-H Benchmark • Compare Mem. SQL with “A” • “A” is column-oriented distributed database (analytical DB) University of Cyprus | EPL 646: Advanced Topics in Databases
Compare Mem. SQL –“A” University of Cyprus | EPL 646: Advanced Topics in Databases
With and without rewrites University of Cyprus | EPL 646: Advanced Topics in Databases
Optimization time University of Cyprus | EPL 646: Advanced Topics in Databases
Related Work SQL Server Parallel Data Warehouse – PDX • Use a query optimizer built on top on the Microsoft SQL Server optimizer Orca • Designed for bid data • Top – down query optimizer • Can run out site the database system as a standalone system -> support different computing architecture such as Hadoop • Use Data e. Xchange Language – DXL Vertica • For column storage data that is organized into projections • Implements rewriters University of Cyprus | EPL 646: Advanced Topics in Databases
The Mem. SQL Query Optimizer The end Thanks for watching. Any questions? 41 University of Cyprus | EPL 646: Advanced Topics in Databases