Tbbszrs lineris regresszianalzis elfelttelek folyamat Statisztika gyakorlat 201920

Többszörös lineáris regresszióanalízis – előfeltételek, folyamat Statisztika gyakorlat 2019/20 I. félév 10. óra

A gyakorlatok anyagai, azaz a tematika, a diasorok, házi feladatok és egyebek a tantárgy honlapján érhetőek el

Recap - Lineáris modellek Egyenes egyenlete: metszéspont, meredekség Adat = modell + hiba Független, függő változó Reziduális értékek Ordinary Least Squares Determinációs együttható – R 2 F-próba B és standardizált β együtthatók

Többszörös lin. reg. előfeltételei ● ● ● ● Elemszám A variancia nem lehet 0 Ne legyenek többdimenziós outlierek (Multi)kollinearitás ne álljon fenn Homoszkedaszticitás Linearitás Hibák ne korreláljanak egymással (ψ-ban ritkán probléma, inkább idősorelemzésnél fordul elő)

Az elemzés lépései – I. ● 1. Adatok előkészítése, ellenőrzése: ○ Változók típusának ellenőrzése: független változó folytonos vagy dichotóm legyen ha kategorikus, de nem dichotóm, akkor ún. dummy változók létrehozása ○ egyváltozós outlierek, hiányzó adatok kezelése ○ Leíró statisztikák alapján meg kell állapítani, hogy az elemzésünk változónak varianciája nem 0

Az elemzés lépései – II. ● 2. A modell definiálása: ○ A modellbe kerülő változók kiválasztása ○ A modell kiszámításának módszerének kiválasztása: enter, stepwise, hierarchikus ○ Ne legyen kollinearitás: ■ Kollinearitás a független változók közötti nagyon erős együttjárás (r > 0. 8), a független változók közötti korrelációs együtthatók kiszámításával ellenőrizzük; amennyiben van ilyen, vagy kihagyjuk az egyiket, vagy főkomponens-elemzéssel összevonjuk őket egy új változóba

Az elemzés lépései – III. ● 3. Feltételek ellenőrzése az output alapján: ○ Többdimenziós outlierek kezelése: ■ Mahalanobis-távolság: egy pont hány szórásnyira van a többdimenziós eloszlás átlagától; a kritériumérték függ az elemszámtól, a változók számától és attól, milyen szignifikanciaszinttel dolgozunk. ■ Centered Leverage value: mennyivel nagyobb a megfigyelt érték hatása a függő változóra, mint a modell értékének hatása. 0 = nincs hozzátett hatása, 1 = teljesen meghatározza a függő változó értékét; baj, ha nagyobb, mint 3*([független _változók_száma]+1) / [elemszám] ■ Cook-távolság: minden egyes érték regressziós modellre gyakorolt hatását becsli meg; mennyire lenne más a modell, ha az adott érték nem lenne benne. Ha >1, akkor outlier ■ Standardized df Beta: mennyivel lenne más a b 0 és b 1 standardizált értéke, ha az adott változót kivennénk a modellből. Ha > 2, akkor outlier

Az elemzés lépései – IV. ● 3. Feltételek ellenőrzése az output alapján: ○ Multikollinearitás: több független változó közötti közepes-erős korreláció, kollinearitás analízis tolerancia értékeivel vagy VIF-fel (Variance Inflation Factor) ellenőrizzük tolerancia 10% alatt vagy VIF 10 fölött bajos; főkomponens elemzéssel egybevonás vagy az alacsony toleranciájú változók kidobása a modellből ○ A standardizált bejósolt értékek és a standardizált reziduális hibák pontdiagramon ábrázolva ■ A pontfelhő mindenhol egyforma széles? ha nem, akkor nem áll fönn a szóráshomogenitás = homoszkedaszticitás, azaz nem mindenhol ugyanolyan pontos a modellünk; tesztelni non-constant variance score testtel, vagy Breusch-Pagan testtel lehet (de elég, ha ránézünk a plotra); amelyik változó esetén sérül, azt ki kell venni ■ A pontfelhő vízszintesen, egyenes vonalban helyezkedik el? ha nem, akkor nem áll fönn a linearitás; amelyik változó esetén sérül, azt ki kell venni

Az elemzés lépései – V. ● 3. Feltételek ellenőrzése az output alapján: ○ Hibák normális eloszlása: hisztogram, Shapiro-Wilk teszt; ezek a feltételek azért kell, hogy teljesüljenek, mert a hibák elvileg véletlenszerűek, és emiatt normális eloszlásúnak kell lenniük; ha nem normális az eloszlásuk, vizsgáljuk meg a független változók eloszlását egyenként 4. A javítások eszközölése után a modell futtatása ○ ● Hibák korrelálatlansága: Durbin-Watson test értéke 2 körül van; 1 alatt vagy 3 fölött problémás (pl. Cochran-Orcutt becslést lehet alkalmazni, de ez a probléma leginkább ismételt méréseknél állhat fenn)

A modell értelmezése ● ● ANOVA táblázat: F érték = hatás/hiba; a hozzá tartozó p érték azt mondja meg, a modell jobban magyaráz-e annál a modellnél, amelyik csak az interceptet tartalmazza (igen, ha p < 0. 05); report: F(df 1, df 2) = …, p = …. Például: F(2, 56) = 80. 357, p < 0. 001. Modell leírása: ○ b 0 vagy Intercept (=metszéspont): ha a független változók értéke 0, mennyi lenne a függő v. ○ b 1: a független változó egységnyi változása mekkora változást idéz elő a függőben ○ β: standardizált b 1 ○ t és p értékek: egymintás t-próba, amely azt vizsgálja, hogy b 0 és b 1 szignifikánsan eltér-e 0 tól. Ha b 1 nem különbözik, akkor nincs hatása az adott független változónak a függő változóra

Modellek összehasonlítása ● ● Az ugyanazon függő változó magyarázatára épített különböző modelleket össze tudjuk hasonlítani, hogy megállapítsuk, melyik a legjobb (melyiknek nagyobb a magyarázó ereje, illeszkedése, értelmezhetősége, stb. ) Kizárólag R 2 alapján nem szabad dönteni!
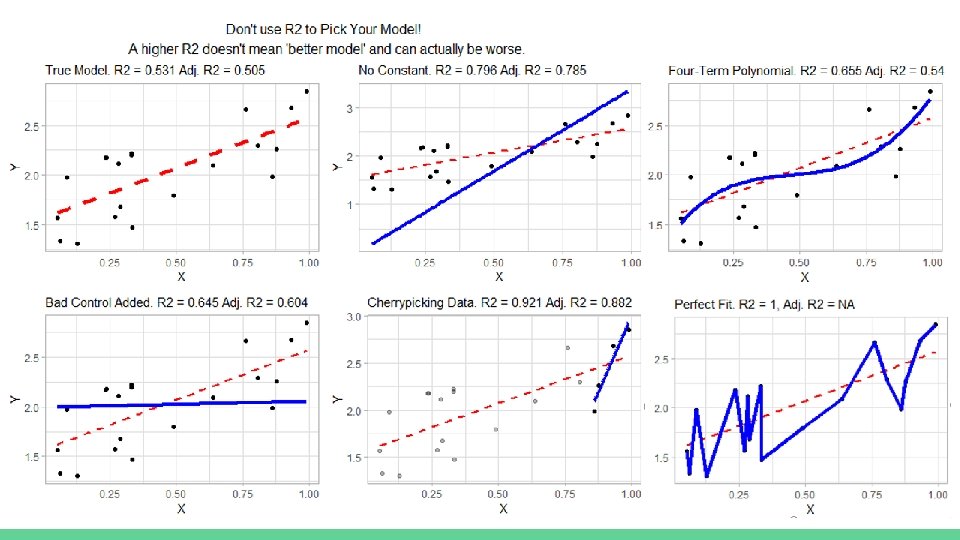

Modellek összehasonlítása ● ● ● Az ugyanazon függő változó magyarázatára épített különböző modelleket össze tudjuk hasonlítani, hogy megállapítsuk, melyik a legjobb (melyiknek nagyobb a magyarázó ereje, illeszkedése, értelmezhetősége, stb. ) Kizárólag R 2 alapján nem szabad dönteni! Akaike information criterion = AIC: egy adott modell általi becslés információveszteségét becsüli meg; (minél kisebb ez a szám, annál kevesebb információ veszik el a modell általi becslés miatt) egyedül legalább egy másik AIC értékkel együtt értelmezhető! Azt a modellt választjuk, amelyik AIC-je kisebb; legalább 2 -vel különbözniük kell Bayesian information criterion = BIC: nagyon hasonló az AIC-hez A kettő közül válassz egyet, és azt használd! (bővebb infóért a kettő közötti különbségekről: https: //www. methodology. psu. edu/resources/AIC-vs-BIC/ ○ ● ●
- Slides: 13