sklearn k NN 833 from sklearn datasets import



")
")


 knn. fit(X, y) #0 = setosa, 1=versicolor,")


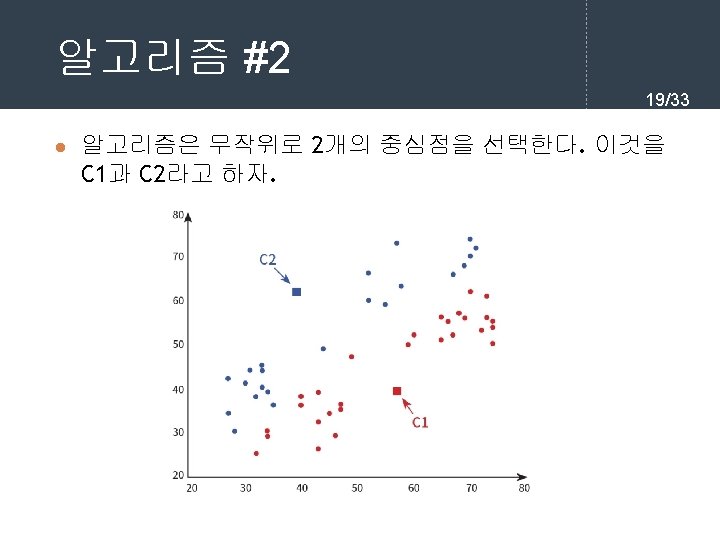
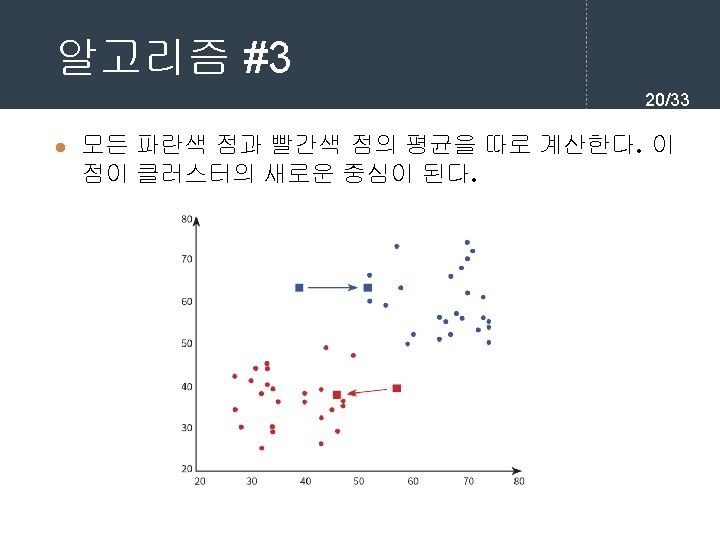
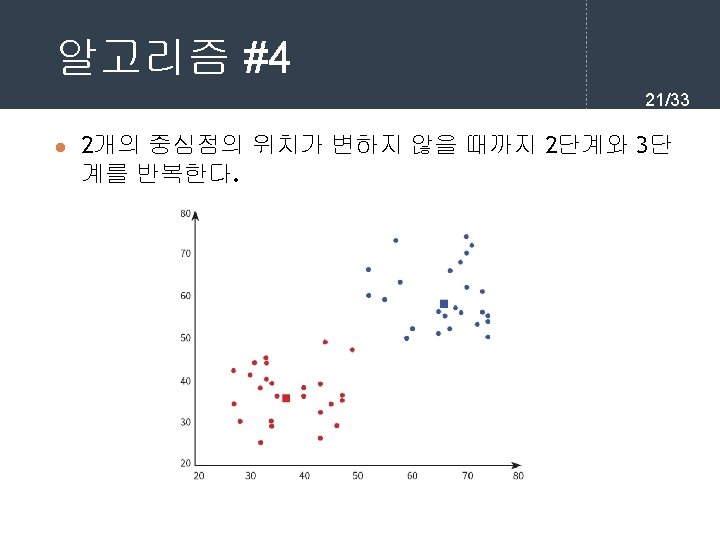


 kmeans. fit(X) print(kmeans. cluster_centers_) [[72.")
![sklearn을 이용한 K-means 클러 스터링 25/33 print(kmeans. labels_) plt. scatter(X[: , 0], X[: ,](https://slidetodoc.com/presentation_image/10eee075135bd83d38bfa776a7beba32/image-25.jpg "sklearn을 이용한 K-means 클러 스터링 25/33 print(kmeans. labels_) plt. scatter(X[: , 0], X[: ,")
에서는 k를 1부터 증가시키 면서 K-means 클러스터링을")

하 는 함수 이용 import")



- Slides: 33
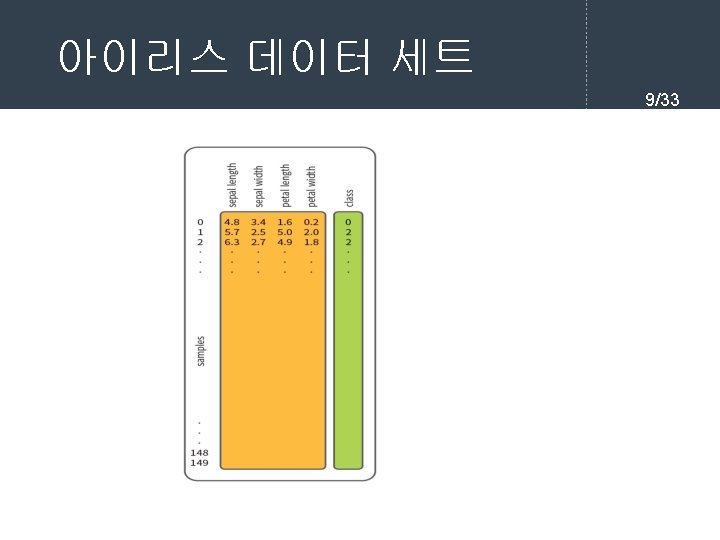
sklearn을 이용한 k. NN 알고리즘 실습 8/33 from sklearn. datasets import load_iris = load_iris() print(iris. data) array([[5. 1, 3. 5, 1. 4, 0. 2], [4. 9, 3. , 1. 4, 0. 2], [4. 7, 3. 2, 1. 3, 0. 2], [4. 6, 3. 1, 1. 5, 0. 2], [5. , 3. 6, 1. 4, 0. 2], [5. 4, 3. 9, 1. 7, 0. 4], . . .
sklearn을 이용한 k. NN 알고리즘 실습 10/33 # 4개의 특징 이름을 출력한다. print(iris. feature_names) ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] # 정수는 꽃의 종류를 나타낸다. : 0 = setosa, 1=versicolor, 2=virginica print(iris. target) [0 0 0 0 0 0 0 0 0 000000011111111111112222222222222222222 2 2]
k. NN학습 11/33 from sklearn. model_selection import train_test_split X = iris. data y = iris. target # (80: 20)으로 분할한다. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0. 2, random_state=4) print(X_train. shape) print(X_test. shape) (120, 4) (30, 4)
k. NN학습 12/33 from sklearn. neighbors import KNeighbors. Classifier from sklearn import metrics knn = KNeighbors. Classifier(n_neighbors=6) knn. fit(X_train, y_train) y_pred = knn. predict(X_test) scores = metrics. accuracy_score(y_test, y_pred) 0. 966666667
k. NN예측 13/33 knn = KNeighbors. Classifier(n_neighbors=5) knn. fit(X, y) #0 = setosa, 1=versicolor, 2=virginica classes = {0: 'setosa', 1: 'versicolor', 2: 'virginica'} # 아직 보지 못한 새로운 데이터를 제시해보자. x_new = [[3, 4, 5, 2], [5, 4, 2, 2]] y_predict = knn. predict(x_new) print(classes[y_predict[0]]) print(classes[y_predict[1]]) versicolor setosa
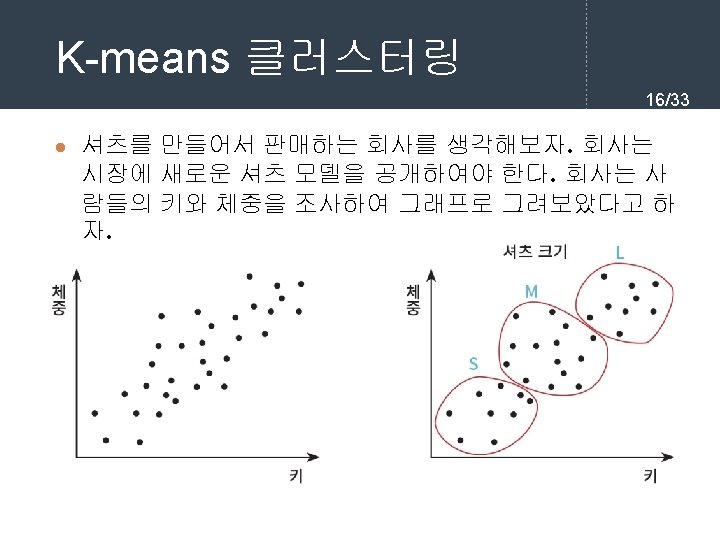
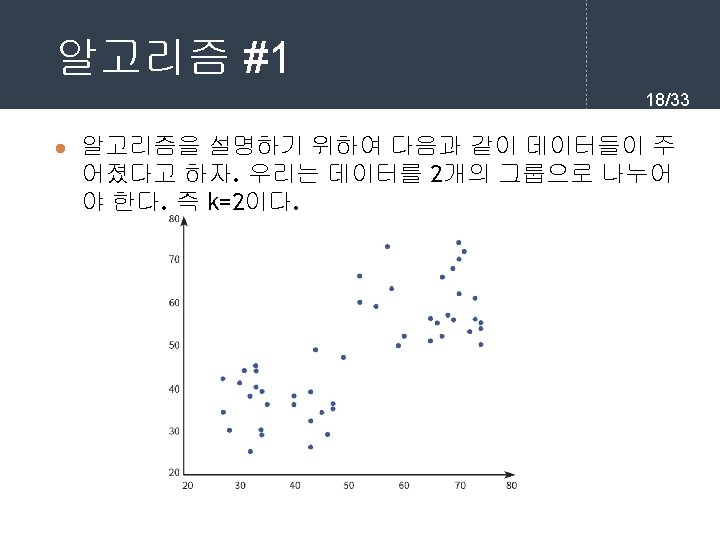
sklearn을 이용한 K-means 클러 스터링 22/33 l 여기서는 sklearn 라이브러리를 이용하여 K-means 클러 스터링 알고리즘을 실습해보자. import matplotlib. pyplot as plt import numpy as np from sklearn. cluster import Kmeans X = np. array([ [6, 3], [11, 15], [17, 12], [24, 10], [20, 25], [22, 30], [85, 70], [71, 81], [60, 79], [56, 52], [81, 91], [80, 81]]) plt. scatter(X[: , 0], X[: , 1])
sklearn을 이용한 K-means 클러 스터링 23/33
sklearn을 이용한 K-means 클러 스터링 24/33 kmeans = KMeans(n_clusters=2) kmeans. fit(X) print(kmeans. cluster_centers_) [[72. 16666667 75. 66666667] [16. 66666667 15. 83333333]]
sklearn을 이용한 K-means 클러 스터링 25/33 print(kmeans. labels_) plt. scatter(X[: , 0], X[: , 1], c=kmeans. labels_, cmap='rainbow')
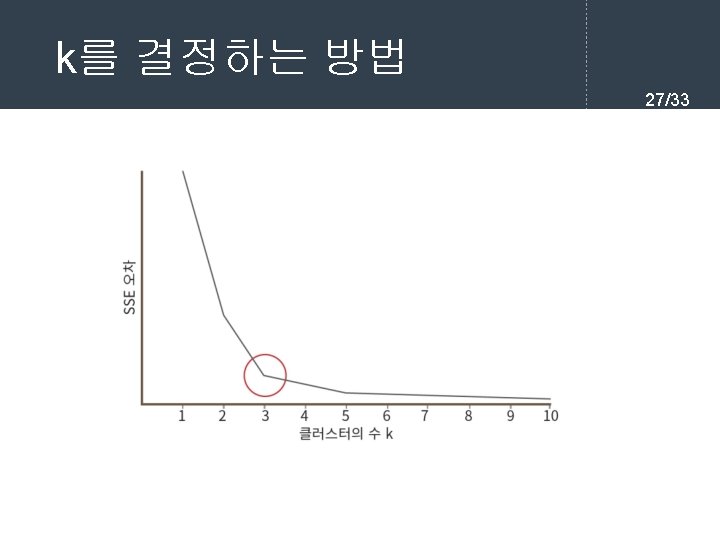
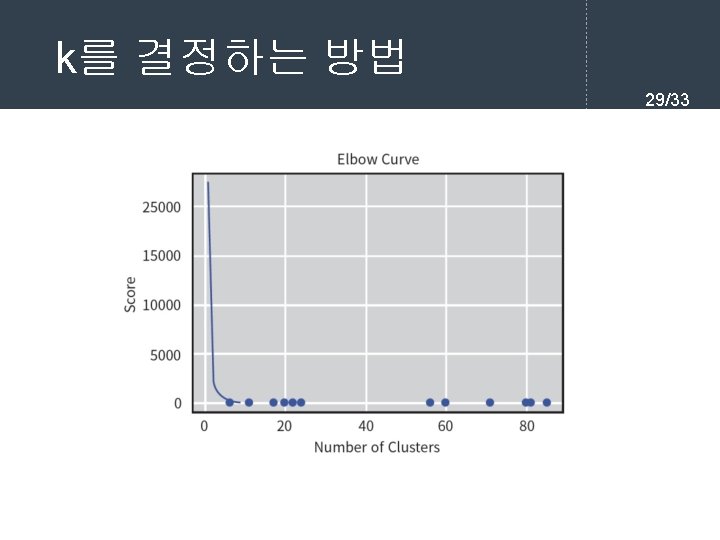
k를 결정하는 방법 26/33 l "팔꿈치" 방법(elbow method)에서는 k를 1부터 증가시키 면서 K-means 클러스터링을 수행한다. 각 k의 값에 대하 여 SSE(sum of squared errors)의 값을 계산한다. var sse = {}; for (var k = 1; k <= max. K; ++k) { sse[k] = 0; clusters = kmeans(dataset, k); clusters. for. Each(function(cluster) { mean = cluster. Mean(cluster); cluster. for. Each(function(datapoint) { sse[k] += Math. pow(datapoint - mean, 2); }); }
k를 결정하는 방법 import matplotlib. pyplot as plt import numpy as np from sklearn. cluster import KMeans X = np. array([ [6, 3], [11, 15], [17, 12], [24, 10], [20, 25], [22, 30], [85, 70], [71, 81], [60, 79], [56, 52], [81, 91], [80, 81]]) plt. scatter(X[: , 0], X[: , 1]) n_clusters = range(1, 10) kmeans = [KMeans(n_clusters=i) for i in n_clusters] # 모든 샘플에 대하여 제곱 오차를 계산하여 리스트에 추가한다. score = [kmeans[i]. fit(X). inertia_ for i in range(len(kmeans))] plt. plot(n_clusters, score) plt. xlabel('Number of Clusters') plt. ylabel('Score') plt. title('Elbow Curve') plt. show() 28/33
Lab: K-means 알고리즘 실습 30/33 l sklearn. datasets. samples_generator의 make_blobs()하 는 함수 이용 import matplotlib. pyplot as plt import seaborn as sns; sns. set() import numpy as np from sklearn. cluster import KMeans from sklearn. datasets. samples_generator import make_blobs X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0. 60, random_state=0) plt. scatter(X[: , 0], X[: , 1], s=50); kmeans = KMeans(n_clusters=4) kmeans. fit(X) y_kmeans = kmeans. predict(X) plt. scatter(X[: , 0], X[: , 1], c=y_kmeans, s=50, cmap='viridis') centers = kmeans. cluster_centers_ plt. scatter(centers[: , 0], centers[: , 1], c='black', s=200, alpha=0. 5);
Lab: K-means 알고리즘 실습 31/33
Q&A 33/33